一种用于用户行为分析的基于证据推理的集成聚类方法与流程
本发明涉及聚类方法技术领域,尤其涉及一种用于用户行为分析的基于证据推理的集成聚类方法。
背景技术
目前常用的聚类方法有五类,包括基于划分的聚类方法、基于层次的聚类方法、基于层次的聚类方法、基于密度的聚类方法和基于网格的聚类方法。基于划分的基于划分的聚类方法,代表方法如-均值(k-means)聚类方法,它的思想是将距离簇中心最近的对象可以划分为一个簇;基于层次的聚类方法思想是通过为给定数据对象集创建层次分解来进行聚类的方法;基于密度的聚类方法,代表方法如dbscan算法,该算法假设聚类结构能通过样本分布的紧密程度确定;基于模型的聚类方法如em算法,可用于含有隐变量(latentvariable)的概率参数模型的最大似然估计或极大后验概率估计;基于网格的聚类方法的思想是将对象空间量化为有限数目的单元,形成一个网状结构,所有聚类都在这个网状结构上进行。
通常,这些单个的聚类方法能够通过对用户行为数据的挖掘和行为特性的分析,有效识别用户行为模式、评估需求响应潜力、从而为营销方案的制定提供决策依据。然而,随着用户行为数据的不断更新,数据量的增长迅速,数据采集用户具有极强的分散性等一系列挑战的出现,现有方法由于采用单个聚类模型其稳定性和准确性很容易受到数据变化的影响,其泛化能力和适应性不强,无法对不同类型用户的用电行为进行深入、快速、准确的分析。根本原因在于数据集中自然分组概念的内在不明确性。另一个困难之处是聚类簇的多样性,聚类簇可以有不同的形状,不同的密度,不同的大小,而且它们经常相互重叠。由于单个聚类算法往往存在各种问题,近年来出现了许多集成聚类算法的研究。集成聚类的思想就是要生成一个聚类集体,也就是有多个聚类结果可用,然后结合这些聚类的结果以求得到一个更优的聚类。结合聚类集体中成员聚类的问题也称为一致性函数问题,或称为集成问题。现有的集成聚类方法包括基于co-occurrence的方法和基于medianpartition的方法。基于co-occurrence的集成聚类方法有重打标签和投票方法、共协矩阵方法和图方法等;基于medianpartition的集成聚类方法有遗传算法、非负矩阵分解和核方法等。近年来,关于集成聚类的研究已经得到了许多研究者的重视,而且证据推理作为一种有效的信息融合方法已经应用于许多领域,然而目前尚未有将证据推理规则融入到集成聚类过程中的现有技术。
技术实现要素:
为了解决现有技术中存在的上述技术缺陷,本发明提供一种用于用户行为分析的基于证据推理的集成聚类方法,能够充分考虑用户数据的时间特性以及基聚类器的可信程度,通过采用证据推理的方法综合解决单个聚类器鲁棒性和稳定性不强和现有集成聚类方法适应性较差的问题,从而提高用户行为数据的聚类效果。
本发明是通过以下技术方案实现的:
一种用于用户行为分析的基于证据推理的集成聚类方法,适用于带有时间特性的流数据集;该集成聚类方法包括如下步骤:
步骤1,对于不同时段的用户行为数据集{d1,d2,...,dk,...,dk},利用不同参数的模糊c均值算法分别生成k个隶属度矩阵{u1,u2,...,uk,...,uk};其中,dk表示第k个时段的数据,uk表示第k个隶属度矩阵;所述用户行为数据集是将带有时间特性的原始流数据按时间窗口切分获得的数据集;
步骤2,将步骤1得到的所述k个隶属度矩阵{u1,u2,...,uk,...,uk}转换为k个相似矩阵{sm1,sm2,...,smk,...,smk},并将所述k个相似矩阵转化为相似向量{sv1,sv2,...,svk,...,svk},并进行归一化处理;其中,相似向量由sv=ω={h1,h2,...,hm,...,hm}表示;
步骤3,令ω的幂集由公式(7)表示:
则根据证据推理规则,将所述相似向量{sv1,sv2,...,svk}通过迭代算法可得到合并后的集成相似向量sv*=e(k)={h1,h2,...,hm,...,hm},且ph,e(k)表示为证据e(k)对h的信度;
步骤4,基于证据推理的集成相似向量sv*,利用层次聚类方法中的agnes算法确定最终集成聚类结果{c1,c2,...,ct,...,ct},其中ct为聚类簇,t为最终聚类个数。
本发明相对于现有技术的有益效果在于:
第一,本发明将用户行为数据按时间跨度进行切分,采用模糊c均值算法对不同时间段的用户行为数据进行聚类,并通过基于证据推理的方法进行集成聚类,能够克服用户行为数据因高维所带来的传统聚类算法失效的问题。
第二,本发明能充分考虑用户数据的时间特性以及基聚类器的可信程度,通过采用证据推理的方法综合解决单个聚类器鲁棒性和稳定性不强和现有集成聚类方法适应性较差的问题,从而提高用户行为数据的聚类效果。
第三,本发明所提出的方法可用于用户行为数据的聚类,特别是带有高维特征的用户行为数据聚类问题,还可以用于流数据的聚类等,应用范围广泛。
附图说明
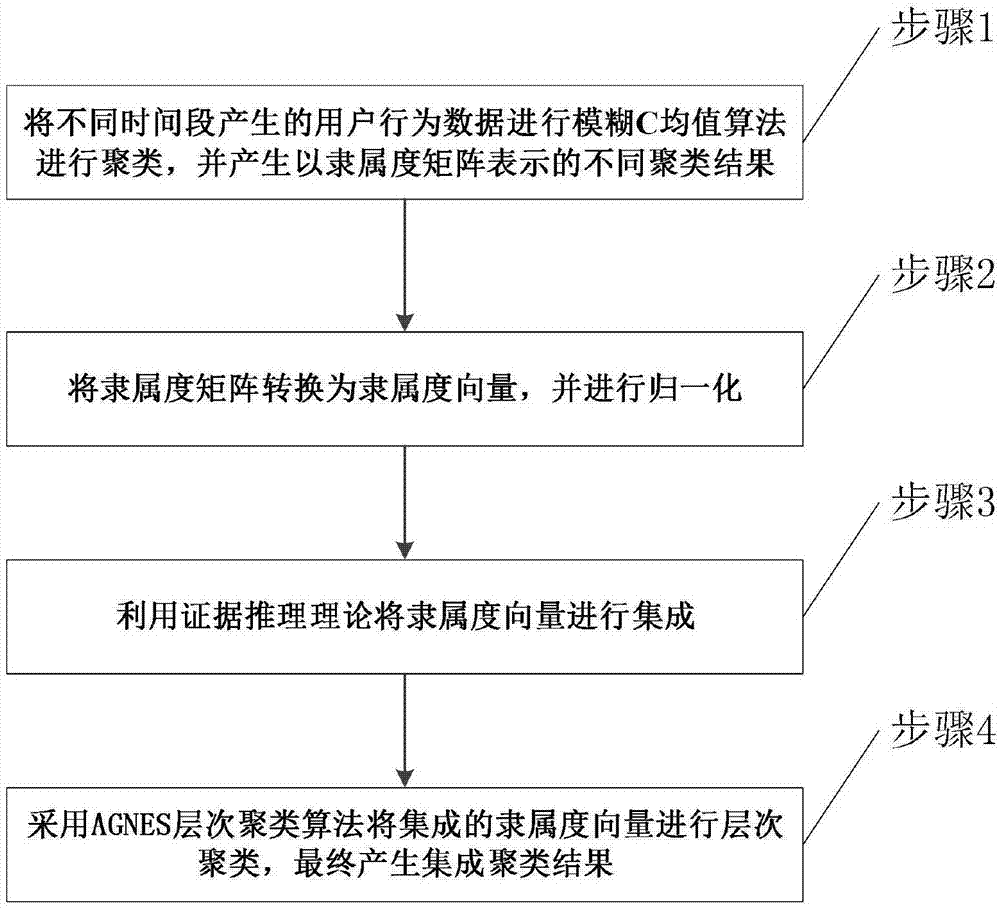
图1为用于用户行为分析的基于证据推理的集成聚类方法的总流程图。
图2为误差平方和sse值的分析结果图。
图3为一致性指数c-index值的分析结果图。
图4为轮廓系数sc值的分析结果图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
实施例1:
如图1所示,一种用于用户行为分析的基于证据推理的集成聚类方法,适用于带有时间特性的流数据集,该集成聚类方法包括如下步骤:
步骤1,对于不同时段的用户行为数据集,按照数据的本身的特征按年、月或日为时间窗切分为{d1,d2,...,dk,...,dk},利用不同参数的模糊c均值算法分别生成k个隶属度矩阵{u1,u2,...,uk,...,uk};其中,dk表示第k个时段的数据,uk表示第k个隶属度矩阵。用户行为数据集是将原始数据按时间窗口切分获得的,(比如实验中所用的七年的用户用电数据,若时间窗口定为年,则将原始数据按年切分为七个的面板数据)。
具体的,步骤1进一步包括如下步骤:
步骤1.1,用值在(0,1)区间内的随机数初始化隶属矩阵u,并且所述隶属矩阵u满足公式(1)的约束:
在公式(1)中,uij在所述隶属度矩阵u中表示第j个样本点属于第i个聚类中心的概率;c表示第k个模糊c均值算法的聚类个数。
步骤1.2,利用公式(2)构造模糊c均值算法的目标函数:
在公式(2)中,
步骤1.3,利用公式(3)和公式(4)更新聚类中心ci和隶属度矩阵u中的元素uij:
步骤1.4,回转执行步骤1.2,将步骤1.3更新后的聚类中心ci和元素uij带入公式(2)。
步骤1.5,回转执行步骤1.1,将步骤1.1至步骤1.4重复k次,得到k个隶属度矩阵{u1,u2,...,uk,...,uk}。
步骤2,将步骤1得到的所述k个隶属度矩阵{u1,u2,...,uk,...,uk}转换为k个相似矩阵{sm1,sm2,...,smk,...,smk},并将所述k个相似矩阵转化为相似向量{sv1,sv2,...,svk,...,svk},并进行归一化处理;其中,相似向量由sv=ω={h1,h2,...,hm,...,hm}表示。
具体的,步骤2进一步包括如下步骤:
步骤2.1,基于步骤1得到的隶属度矩阵uk,根据公式(5)计算获得第k次聚类结果的相似矩阵smk:
smk=uk(uk)t(5)
式(5)中,相似矩阵smk中的元素
步骤2.2,令相似向量由sv=ω={h1,h2,...,hm,...,hm}表示,且相似向量的值由相似矩阵sm对角线以上部分的元素构成,元素的个数
步骤2.3,利用公式(6)对所述相似向量svk中的元素进行归一化处理,可得到:
在所述公式(6)中,
步骤3,令ω的幂集由公式(7)表示:
则根据证据推理规则,将所述相似向量{sv1,sv2,...,svk}通过迭代算法可得到合并后的集成相似向量sv*=e(k)={h1,h2,...,hm,...,hm},且ph,e(k)表示为证据e(k)对h的信度。
具体的,步骤3进一步包括如下步骤:
步骤3.1,令wk(0≤wk≤1)和rk(0≤rk≤1)分别表示用户行为数据dk的权重和相似向量svk的可信度,其中wk为0表示“最不重要”,wk为1表示“最重要”;rk为0表示“极度不可信”,rk为1表示“完全可信”;结合权重wk与可信度rk并根据公式(8)得到第k个相似向量的混合权重
在所述公式(8)中,wk表示用户行为数据dk的权重,且当用户行为数据dk产生时间越早,wk越小;
rk为相似向量svk的可信度,由聚类评价指标轮廓系数进行度量,根据公式(9)计算获得:
其中,a(i)表示样本xi与同一聚类簇中其他样本的平均距离,由公式(10)计算获得:
其中,b(i)表示样本xi与其他聚类簇的样本的平均距离的最小值,根据公式(11)计算获得:
在公式(10)和公式(11)中,d(i,a)和d(i,b)均由欧几里得距离计算获得,a表示与xi处于同一个簇的样本集合,b表示与xi处于不同簇的样本集合;
步骤3.2,利用公式(12)计算证据e(2)对h的支持度
在公式(12)中,
步骤3.3,利用公式(13)将得到的所有
在公式(13)中,信度ph,e(2)即为支持度
步骤3.5,设前k个相似向量的合并结果由
在公式(15)中,mh,e(k-1)表示标准化后支持度,由初始值
步骤3.6,根据公式(19)对支持度
在公式(19)中,
步骤4,基于证据推理的集成相似向量sv*,利用层次聚类方法中的agnes算法确定最终集成聚类结果{c1,c2,...,ct,...,ct},其中ct为聚类簇,t为最终聚类个数。
具体的,步骤4进一步包括如下步骤:
步骤4.1,将每个样本归为一类,此时t=n,其中t为聚类个数,n为样本个数,且样本之间的相似度利用上述证据推理的结果集成相似向量sv*表示。
步骤4.2,找出集成相似向量sv*中最大的元素max_sv*,将max_sv*所代表的样本xi和样本xj聚为一类,设此类别为ct。
步骤4.3,利用公式(20)计算这个类与其他类的相似度:
在公式(20)中,sim(x,x')表示来自聚类簇cs的样本x和来自聚类簇ct的样本x'之间的相似度,并与相似向量sv*中元素的值一一对应,|cs|和|ct|分别表示聚类簇cs和ct中的样本个数。
步骤4.4,若此时聚类簇的个数为t,则停止计算,否则重复步骤4.2和步骤4.3直到最终聚类个数达到t。
下面以具体实例,针对本发明方法进行实验论证,具体内容如下:
1、数据集
本实施例选用我国沿海某城市的商业用户用电行为数据来验证用于用户行为分析的集成聚类方法的有效性。在此商业用户用电量数据中,包括169个商业用户,时间跨度从2010年至2016年共7年的用电量数据。
2、评价指标
本实施例使用聚类领域常用的轮廓系数(sc),误差平方和(sse),和一致性指数(c-index)作为实验评价指标。sse是通过计算每个类的中心点到所有样本点的距离之和得到的,是聚类领域广泛应用的评价指标,sse的值越小,表示聚类效果越好。c-index主要从凝聚度方面反映聚类效果的好坏,它的值越小,表示聚类效果越好。sc综合考虑了凝聚度和分离度两种因素,能够有效地判断不同的聚类算法在同一数据集的好坏,sc的值越大,表示聚类的效果越好越高。轮廓系数、误差平方和与一致性指数的计算可分别由式(9)、式(21)和式(22)得到。
式(21)中,nt表示第t个聚类簇ct中的样本数,
3、实验结果
为了验证本发明所提出的方法的有效性,本发明在商业用户用电行为数据集上进行实验,并将本发明提供的用于用户行为分析的基于证据推理的集成聚类方法及六种对比方法模糊c均值聚类(fcm)、k均值聚类(k-means)、密度聚类(dbscan)、层次聚类(hierarchy)、投影聚类(proclus)和投票k均值聚类(voting-kmeans)的实验结果进行比较。实验结果如表1、图2、图3和图4所示,图2中横坐标表示聚类个数,纵坐标表示sse的值,图3中纵坐标表示c-index的值,图4中纵坐标表示sc的值。
表1erce与对比算法聚类结果比较(聚类个数:2-10)
从表1中可以看出,本发明所提的用于用户行为分析的集成聚类方法erce在sse,c-index,sc三个评价指标下均优于另外六种聚类方法。从表1还可以看出,erce的聚类效果比集聚类器fcm有较大幅度的提升,这也进一步验证了本发明提出的基于证据推理的聚类融合方法的有效性。
由图2、图3和图4可以明显看出,本发明所采用的基于证据理论的集成聚类方法在各项指标中均有较好的表现,而且在不同的聚类个数下,本发明提出的方法都能取得较好的结果。另外,从上述图中的曲线可以看出,当聚类个数为6的时候,正好对应着曲线“拐点”位置,而聚类个数大于6时,聚类评价指标的变化趋于平缓。因此,在此用户行为数据集中,聚类个数的最佳选择为6。当本发明的方法应用到其他类似的数据集中,也可以通过此方法来确定最佳聚类个数。
本领域的技术人员容易理解,以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!