一种基于轻量化网络的实时场景图像语义分割方法与流程
本发明属于图像语义分割
技术领域:
,具体涉及一种基于轻量化网络的实时场景图像语义分割方法。
背景技术:
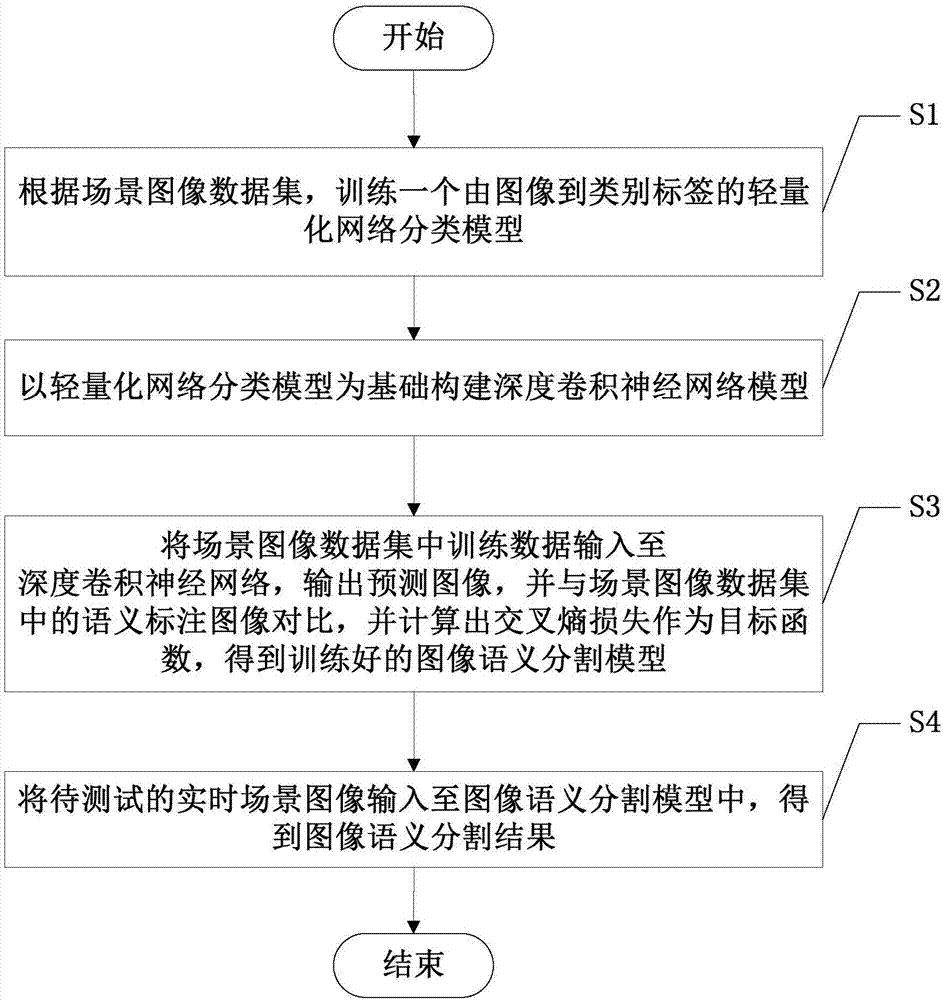
:场景语义分割应属于图像语义分割在场景图像上的应用。场景语义分割对后续的计算机视觉任务具有至关重要的作用,例如无人驾驶中行人及车辆等的区分。语义分割在很多实际应用场景的重要组成部分,如机器视觉,自动驾驶,以及移动计算等,准确理解周围场景对实际应用的决策非常重要,因此,运行时间是评估语义分割系统在实际应用场景中的关键因素。目前,深度卷积神经网络的发展在语义分割上取得了显著进步,但大多数相关研究都集中在提高分割精度而不是模型的计算效率上,这些网络的有效性在很大程度上是取决于复杂的深度和宽度模型的设计,这需要涉及很多操作和参数。然后,大量的实际应用场景如自动驾驶系统,通常基于嵌入式设备,计算和存储资源相对有限。用于语义分割的网络都需要很高的计算资源超过了一些移动或者嵌入式系统所能提供的,造成了准确率较高,但是速度远远不够的情况。mobilenetv2是一种针对移动或者移动资源受限的神经网络结构,他能通过显著减少操作和内存的数量,同时保持相同的精度。近年来,绝大多数当前最佳的图像语义分割方法都是基于深度卷积神经网络的。典型的语义分割网络结构是基于编码器解码器的结构,编码器是一个图像降采样过程,负责抽取图像粗糙的语义特征,紧接着就是一个解码器,解码器的一个图像上采样过程,负责对降采样得到的图像特征进行上采样恢复到输入图像原始维度。轻量化网络在图像分类任务中展现了十分优秀的结果,将轻量化网络基础网络(即编码器),来快速的提取场景图像特征,能在不牺牲准确率的同时还能提升速度。技术实现要素:针对现有技术中的上述不足,本发明提供的基于轻量化网络的实时场景图像语义分割方法解决了现有技术中,实现图像语义分割速度慢的问题。为了达到上述发明目的,本发明采用的技术方案为:一种基于轻量化网络的实时场景图像语义分割方法,包括以下步骤:s1、根据场景图像数据集,训练一个由图像到类别标签的轻量化网络分类模型;s2、以轻量化网络分类模型为基础构建深度卷积神经网络模型;s3、将场景图像数据集中训练数据输入至深度卷积神经网络,输出预测图像,并与场景图像数据集中的语义标注图像对比,并计算出交叉熵损失作为目标函数,得到训练好的图像语义分割模型;s4、将待测试的实时场景图像输入至图像语义分割模型中,得到图像语义分割结果。进一步地,所述步骤s1中,所述轻量化网络分类模型包括顺次连接的1个conv2d单元、17个bottleneck单元、1个1×1的conv2d、单元1个7×7的avgpool单元和1个1×1的conv2d单元;每个所述bottleneck单元均包括第一inplace-abn层、第二inplace-abn层和一个投影层。进一步地,所述轻量化网络分类模型中:当步长为1时,所述bottleneck单元的结构为:第一inplace-abn层、第二inplace-abn层和一个投影层顺次串联连接,输入端同时与第一inplace-abn层和投影层串联连接,投影层作为bottleneck单元的输出端;当步长为2时,所述bottleneck单元的结构为:第一inplace-abn层、第二inplace-abn层和一个投影层顺次串联连接,输入端仅与第一inplace-abn层连接,投影层作为bottleneck单元的输出端。进一步地,所述步骤s3中:图像语义分割模型为编码器-译码器网络结构;所述编码器为轻量化网络分类模型,用于提取图像特征;所述译码器包括顺次连接的快捷连接块和一个1×1的卷积层,用于恢复图像分辨率。进一步地,所述快捷连接块包括顺次连接的1个1×1的卷积层、1个3×3的深度可分离卷积单元、1个1×1的卷积层以及1个快捷连接;所述深度可分离卷积单元包括顺次连接的深度卷积层和逐点卷积层。进一步地,所述步骤s3中,所述深度卷积神经网络训练过程为:s31、将场景图像数据集中的训练数据图像进行预处理;s32、将训练好的轻量化网络分类模型的参数值作为深度卷积神经网络模型的初始值;s33、对训练数据图像进行数据扩增处理;s34、以数据扩增后的训练数据图像的每一像素的交叉熵损失的和作为损失函数,使用随机梯度下降法,采用多项式学习策略,完成对深度卷积神经网络模型的训练;进一步地,所述步骤s34中多项式学习策略的学习率lr为:其中,baselr为初始学习率;iter为当前迭代次数;total_iter为总迭代次数;上标power为多项式的幂。进一步地,所述步骤s31中训练数据图像进行预处理为将图像的尺寸裁剪为224×224;所述步骤s33中数据扩增处理包括对图像进行随机翻转、在0.5到2倍之间随机缩放图像和在-10度和10度之间随机旋转图像。本发明的有益效果为:本发明提供的基于轻量化网络的实时场景图像语义分割方法通过将修改过的mobilenetv2作为基础网络,能高效地提取图像特征,在上采样过程中,快捷连接块的运用,使参数利用更加高效,进一步提高了语义分割模型的速度。附图说明图1为本发明提供的实施例中基于轻量化网络的实时图像语义分割方法实现流程图。图2为本发明提供的实施例中两种bottlencke层结构示意图。图3为本发明提供的实施例中深度卷积神经网络训练流程图。具体实施方式下面对本发明的具体实施方式进行描述,以便于本
技术领域:
的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本
技术领域:
的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。如图1所示,一种基于轻量化网络的实时场景图像语义分割方法,包括以下步骤:s1、根据场景图像数据集,训练一个由图像到类别标签的轻量化网络分类模型;上述场景图像数据集为cityscapes城市街道场景数据集,包含20个类别标注(含1个背景类别),涵盖欧洲50个城市,共5000张精细标注的数据集,以其中2975张作为训练数据集,500张作为验证数据集,1525张作为测试数据集。上述轻量化网络分类模型的网络结构如表1所示:表1:轻量化网络分类模型网络结构表layerinputoperatortcns12242×3conv2d-321221122×32bottleneck1161131122×16bottleneck624224562×24bottleneck632325282×32bottleneck664426142×64bottleneck696317142×96bottleneck616032872×160bottleneck632011972×320conv2d1×1-1280111072×1280avgpool7×7--1-111×1×1280conv2d1×1-k-表中,t表示‘扩张’倍数,c表示输出通道数,n表示重复次数,s表示步长。所述轻量化网络分类模型包括顺次连接的1个conv2d单元、17个bottleneck单元、1个1×1的conv2d单元1个7×7的avgpool单元和1个1×1的conv2d单元;每个所述bottleneck单元均包括第一inplace-abn层、第二inplace-abn层和一个投影层。inplace-abn是一个高效减少深度神经网络训练内存消耗的新方法,能够代替传统的批归一化与激活层,带来更好的语义分割效果。如图2所示,当步长为1时,所述bottleneck单元的结构为:第一inplace-abn层、第二inplace-abn层和一个投影层顺次串联连接,输入端同时与第一inplace-abn层和投影层串联连接,投影层作为bottleneck单元的输出端;当步长为2时,所述bottleneck单元的结构为:第一inplace-abn层、第二inplace-abn层和一个投影层顺次串联连接,输入端仅与第一inplace-abn层连接,投影层作为bottleneck单元的输出端。s2、以轻量化网络分类模型为基础构建深度卷积神经网络模型;将表1中的layer3输出的特征图,尺寸为1122×16,layer4输出的特征图,尺寸562×24,layer5输出的特征图,尺寸为282×32,layer7输出的特征图,尺寸为142×96,分别作为特征提取网络(编码器)的第一层、第二层、第三层、第四层,分别记为encoder_1,encoder_2,encoder_3,encoder_4。将encoder_4与encoder_3上采样后的特征图输入至快捷连接块中,输出decoder_1。将decoder_1与encoder_2上采样后的特征图输入至快捷连接块中,输出decoder_2。将decoder_2与encoder_1上采样后的特征图输入至快捷连接快中,输出decoder_3。最后将encoder_4,decoder_1,decoder_2,decoder_3上采样至输入图像大小,然后将得出的四个特征图进行串联,最后经过1个1×1的卷积,得出的特征图与语义分割标注图像计算损失函数,误差反向传播,更新权值,得到语义分割网络模型。s3、将场景图像数据集中训练数据输入至深度卷积神经网络,输出预测图像,并与场景图像数据集中的语义标注图像对比,并计算出交叉熵损失作为目标函数,得到训练好的图像语义分割模型;上述步骤s3中:图像语义分割模型为编码器-译码器网络结构;所述编码器为轻量化网络分类模型,用于提取图像特征;为了保留图像的空间信息,去掉所述轻量化网络的全连接层,并将其作为编码器。所述译码器包括顺次连接的快捷连接块和一个1×1的卷积层,用于恢复图像分辨率。利用快捷连接块,结合编码器的特征图,上采样特征图,最后将解码器的输出的各个特征图上采样至原图大小串联起来,再经过一个1×1卷积,最后得到的特征图与语义分割标注图像进行误差反向传播,得到神经网络模型。其中,快捷连接块包括顺次连接的是1个1×1的卷积层、1个3×3的深度可分离卷积单元、1个1×1的卷积层以及1个快捷连接,其中3×3的深度可分离卷积单元上采样特征图。所述深度可分离卷积单元包括顺次连接的深度卷积层和逐点卷积层;深度卷积层通过在每个输入通道上应用一个卷积滤波器来实现轻量级的滤波;第二个是1个1×1卷积层,即逐点卷积层,通过计算输入通道的线性组合来建立新的特征。深度可分离卷积实现了空间和通道之间的解耦,达到模型加速的目的,广泛运用在轻量化网络中。其中,交叉熵损失函数为:式中,y表示样本标签,表示预测输出。如图3所示,上述步骤s3中,所述深度卷积神经网络训练过程为:s31、将场景图像数据集中的训练数据图像进行预处理;将训练数据图像进行预处理为将图像的尺寸裁剪为224×224;s32、将训练好的轻量化网络分类模型的参数值作为深度卷积神经网络模型的初始值;s33、对训练数据图像进行数据扩增处理;所述步骤s43中数据扩增处理包括对图像进行随机翻转、在0.5到2倍之间,随机缩放图像和在-10度和10度之间,随机旋转图像。s34、以数据扩增后的训练数据图像的每一像素的交叉熵损失的和作为损失函数,使用随机梯度下降法,采用多项式学习策略,完成对深度卷积神经网络模型的训练;所述步骤s34中多项式学习策略的学习率lr为:其中,baselr为初始学习率;设置为0.001;iter为当前迭代次数;total_iter为总迭代次数;上标power为多项式的幂,设置为0.9。s4、将待测试的实时场景图像输入至图像语义分割模型中,得到图像语义分割结果。本发明的有益效果为:本发明提供的基于轻量化网络的实时场景图像语义分割方法通过将修改过的mobilenetv2作为基础网络,能高效地提取图像特征,在上采样过程中,快捷连接块的运用,使参数利用更加高效,进一步提高了语义分割模型的速度。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1