一种错位书籍查找系统及其查找方法与流程
本发明属于图书馆自动化技术领域,主要涉及到一种错位书籍查找系统及其查找方法。
背景技术:
现代社会图书馆收藏的书目逐年增多,图书借阅活动日益频繁。在读者还书时,由管理员用扫码设备扫描书籍条码,将其在图书管理系统中入库,然后再摆放到书架指定位置。然而读者在阅览室自行取阅书籍后,经常不会放回原位,图书馆工作人员需要定期整理错位书籍,但是人工整理方式效率低下而且容易错漏,经常出现读者在图书管理系统中查询到某些书籍明明还有馆藏存本,但是在相应书架上找不到书籍的情况。
针对这种情况,现有的解决方案往往是利用rfid射频标签技术进行图书定位,但是使用成本和系统集成方面仍然存在一定障碍,难以大规模普及。此外还有一些其他方案也试图解决图书整理问题,例如:中国发明专利文件cn106504443a公开了一种自动图书整理装置,使用行走车体和布置在车体上的升降机构和运动机构对书架进行自动整理。中国发明专利文件cn107862488a公开了一种爬虫式图书整理系统,在书架上安装爬虫扫描装置扫描书架上的书籍的信息,然后根据书架上书籍的信息,通过条件组件、推挡组件整理图书。中国发明专利文件cn107329469a公开了一种自主机器人的乱架图书管理系统,为书架的每一层编码并制作二维码,机器人上的扫描枪模块扫码获取书架信息,扫描书脊上的条码获取图书信息,机器人扫描整个书架上的图书条码比对原始位置信息判断图书是否错架,实现乱架图书管理。上述的这三种现有方案需要对书架进行改造或使用自动化装置对书架进行整理,若需要判断图书是否错架,还需要提前在数据库中存放图书的正确存放位置,使用和维护的成本较高,推广存在一定障碍。
技术实现要素:
图书馆书籍整理的主要问题在于如何发现错位书籍,一旦发现了错位书籍,后续的整理工作通过人工完成并不困难;目前市场上尚缺少一种价格相对低廉的错位书籍查找方法。本发明提出一种错位书籍查找系统及其查找方法,利用图像识别和数据处理技术查找错位书籍。
为解决上述技术问题,本发明采用了如下技术手段:
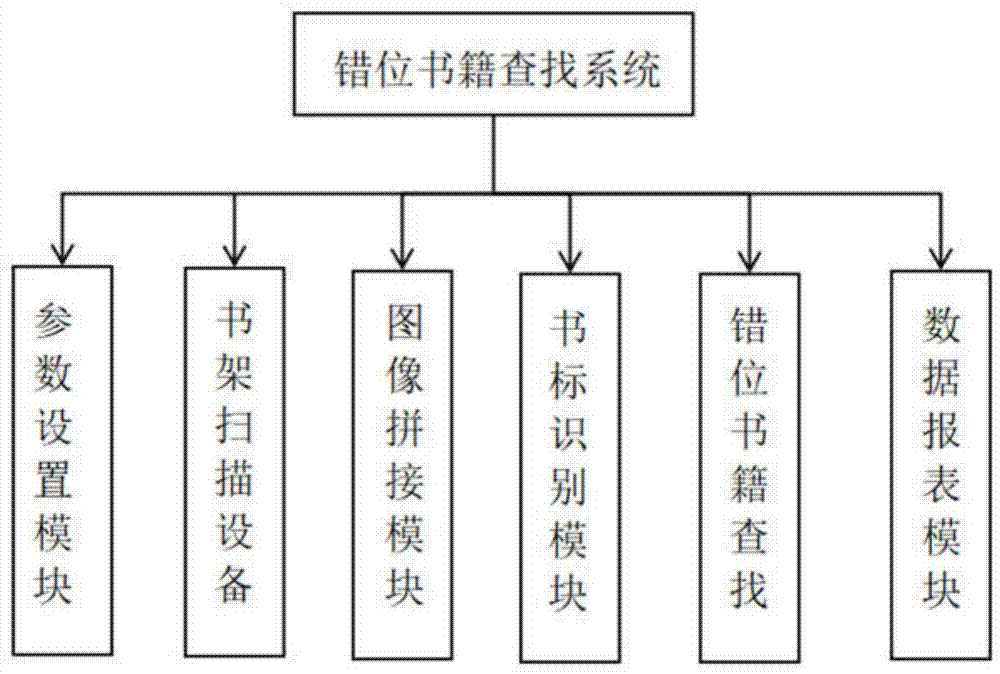
一种错位书籍查找系统,具体包括参数设置模块、书架扫描设备、图像拼接模块、书标识别模块、错位书籍查找模块和数据报表模块。
所述的参数设置模块用于设置室内平面布局、书架数量、书架位置和书架尺寸;所述的书架扫描设备用于分部分拍摄书架图片并将拍摄的图片上传到图像拼接模块;所述的图像拼接模块用于将书架扫描设备拍摄并上传的多张书架图像拼接为完整图像;所述的书标识别模块用于识别书脊标签图像,将其转换为文本格式的索书号;所述的错位书籍查找模块用于对识别到的索书号数据进行分析,查找出其中的错位书籍;所述的数据报表模块储存错位书籍查找模块找到的错位书籍信息,并将错位书籍信息做成报表供工作人员查看。
进一步的,所述的书架扫描设备采用自动化拍照设备或者人工拍摄。
进一步的,所述的图像拼接模块采用基于标准差的harris角点检测算法进行图像拼接。
一种错位书籍查找方法,具体包括以下步骤:
s1、在书架正面拍摄多张书籍图像,将图片上传到系统中并按照顺序拼接为一张完整的图像p;
s2、对图像p进行文本识别,提取图像p中各个书脊标签上的索书号;
s3、将书籍索书号和对应书籍标签在图像p中的坐标依次存放到列表a和列表pos中;
s4、对列表a中存放的索书号进行扫描分析,检测其中错位的索书号;
s5、在列表pos中找到步骤s4中检测到的错位书籍索书号对应的坐标数据,根据坐标数据在图像p中用特定的颜色做出标记;
s6、重复步骤s1到s5,直到完成所有书架的错位书籍查找和标记。
进一步的,所述的步骤s3将书籍索书号和对应书籍标签在图像p中的坐标依次存放到列表a和列表pos中,具体通过如下步骤实现:
s31、构造一个列表a,用于依次存放各书籍的索书号,构造一个列表pos,用于存放书籍标签在图像p中的横坐标和纵坐标;
s32、令t为当前书籍,初始为图像p左上角的第一本书;
s33、将t的索书号添加到列表a中,将t的坐标添加到列表pos中;
s34、令t为当前书籍右侧的下一本书,若右侧已无书籍,则令t为图像p中下一层的最左侧书籍,若当前书籍已经是图像p中右下角最后一本书,则结束流程,否则转到步骤s33。
进一步的,所述的s4步骤对列表a中存放的索书号进行扫描分析,检测其中错位的索书号,具体通过如下几个步骤实现:
s41、创建与列表a长度相同的数组l,用于记录列表a中各元素以自己为结尾元素的最长递增子序列长度,并令l[1]=1;
s42、创建与列表a长度相同的数组p,用于记录列表a中各元素在以自己为结尾元素的最长递增子序列中的前驱元素,并令p[1]=null;
s43、定义当前下标号x,令x=2;
s44、检测列表a在下标x之前所有元素的索书号,寻找以a[x]为结尾元素的最长递增子序列,即对每一个i<x,按下面公式计算得到l[x]:
l[x]=max{l(i)+1|a[i]<a[x]∧i<x}(1)
并记录p[x]为计算l[x]时得到的最长递增子序列的前一个元素下标i;
s45、令x=x+1,若x≤|a|,转到s44,否则转到s46;
s46、遍历数组l并找到其最大值处的下标k,然后在p[k]处开始往前回溯出以a[k]为结尾元素的最长递增子序列,记为lis;
s47、设置错位书籍列表b为列表a除lis以外的所有书籍。
本发明错位书籍查找方法的基本思路是:图书馆中每本书的书脊部分都贴有标签,标签上打印着唯一的索书号,书籍在上架时总是按照索书号逐层逐序摆放。如果书架上的书籍摆放顺序全部正确,这些书籍的索书号必然会形成一个单调递增序列;反之,若书架上出现了错位书籍,该序列的单调递增性质就会被打破。因此,只要能够找出索书号序列中的错误编号,即可找到错位的书籍。
采用以上技术手段后可以获得以下优势:
本本发明提出的一种错位书籍查找系统及其查找方法,通过图像识别和数据分析技术实现错位书籍查找,不需要对原本的图书或者图书馆设备进行任何改造,成本较低,不受环境限制,自适应能力较强。此外根据书籍索书号递增的特点检索错位书籍,不需要在后台数据库中预先存储书籍的正确存放位置,大大降低了操作复杂性和操作难度,不需要在后续使用中进行过多维护,易于推广使用。
附图说明
图1是本发明错位书籍查找系统模块示意图。
图2是本发明错位书籍查找方法的流程图。
图3是本发明错位书籍查找方法书籍查找顺序示意图。
图4是本发明进行数据分析检索错位书籍的具体流程图。
具体实施方式
下面结合附图对本发明的技术方案作进一步说明:
一种错位书籍查找系统,如图1所示,具体包括参数设置模块、书架扫描设备、图像拼接模块、书标识别模块、错位书籍查找模块和数据报表模块。
参数设置模块用于设置室内平面布局、书架数量、书架位置和书架尺寸等参数;书架扫描设备用于分部分拍摄书架图片,并将拍摄的图片上传到图像拼接模块,分部分拍摄是为了更清晰的记录各个书籍的细节信息,书架扫描设备可以选择自动拍照设备,也可以由工作人员手动拍摄上传;图像拼接模块用于将书架扫描设备拍摄并上传的多张书架图像拼接为清晰完整的图像;书标识别模块用于识别书脊标签图像,将其转换为文本格式的索书号;错位书籍查找模块用于对识别到的索书号数据进行整理分析,查找出其中的错位书籍;数据报表模块储存查找到的错位书籍信息,并将错位书籍信息做成报表供工作人员查看。
一种错位书籍查找方法,如图2所示,具体包括如下步骤:
s1、在书架正面拍摄多张书籍图像,然后拼接成一张完整的图像p。在本具体实施例中采用基于标准差的harris角点检测算法进行特征检测,进而进行图像拼接。在纹理信息丰富的区域,harris算子可以提取出大量有用的特征点,因为其计算过程只涉及了图像的一阶导数,所以即使存在图像旋转、灰度变化和视点变换,对角点的提取亦比较稳定。图像每个角点用9×9的矩阵表示,计算每个角点描述子与对应角点描述子的欧式距离,对所有角点进行粗匹配,然后利用随机抽样一致ransac方法剔除伪匹配点对,计算单应性矩阵,得到精确地匹配点对。图像的融合采用平滑过渡法,实现图像间的平滑过渡,消除拼接的痕迹。最后将拼接完成的完整图像记为p。
s2、对图像p进行文本识别,提取书脊上的索书号。图书标签上的文字是印刷体文字,比手写字体书写更规范,像素分布更规律,有利于用统计特征的方法去识别。
在本具体实施例中采用基于统计特征的识别方法进行书籍标签识别,利用基于训练样本像素的统计运算得到模板,用模板和书籍标签进行匹配,得到文字识别结果,具体步骤为:
s21、图像预处理。首先对图像进行预处理,将其灰度化后进行分割;然后对分割后的图像进行归一化,采用线性插值的方法把各字符修正为统一的尺寸;接下来使用otsu算法计算阈值,将图像二值化。
s22、图像识别。通过统计数字、字母图像像素点的分布概率进行模板训练,然后通过计算图像文字的特征矩阵与每个字符模板的距离进行分类识别,每个书籍标签的图像识别结果存放在一个字符串中。
s3、将各个书籍的索书号和该标签在图像p中的坐标按照在书架中的位置顺序分别存放到列表a和列表pos中,具体步骤如下:
s31、构造一个列表a,用于存放各书籍的索书号;构造一个列表pos,用于存放各标签在图像p中的横坐标和纵坐标;
s32、令t为当前书籍,初始为图像p左上角的第一本书;
s33、将t的索书号添加到列表a中,t的坐标添加到列表pos中;
s34、如图3所示,令t为当前书籍右侧的下一本书,若右侧已无书籍,则令t为图像p中下一层的最左侧书籍;若当前书籍已经是图像p中右下角最后一本书,则结束流程,否则转到步骤s33。
s4、对列表a中存放的索书号进行扫描分析,检测其中错位的索书号,如图4所示,具体步骤如下:
s41、创建与列表a长度相同的数组l,用于记录列表a中各元素以自己为结尾元素的最长递增子序列长度,并将l数组的第一个元素赋值为1,即l[1]=1;
s42、创建与列表a长度相同的数组p,用于记录列表a中各元素在以自己为结尾元素的最长递增子序列中的前驱元素,并令p[1]=null;
s43、定义当前下标号x,令x=2;
s44、检测列表a在下标x之前所有元素的索书号,寻找以a[x]为结尾元素的最长递增子序列,即对每一个i<x,按下面公式计算得到l[x]:
l[x]=max{l(i)+1|a[i]<a[x]∧i<x}(2)
并记录p[x]为计算l[x]时得到的最长递增子序列的前一个元素下标i;
s45、令x=x+1,若x≤|a|,转到s44,否则转到s46;
s46、遍历数组l并找到其最大值处的下标k,然后在p[k]处开始往前回溯出以a[k]为结尾元素的最长递增子序列,记为lis;
s47、设置错位书籍列表b为列表a除lis以外的所有书籍。
s5、在图像p中将s4步骤中检测到的错位书籍标签,根据s3步骤得到的pos坐标,用特定的颜色做出标记。
s6、重复s1到s5步骤,直到所有书架均处理完成。
通过上述方法可以准确查找出所有的错位书籍,生成一个标记了错位书籍的图像组,这个图像组可以存放在计算机中,也可以打印出来查看,图书馆的工作人员可以根据图像组中标记的错位书籍找到图书馆中对应的书架和书籍,进行错位书籍的整理工作。本发明提出的错位书籍查找系统及查找方法,不仅成本较低,而且不受图书馆本身设计限制,只需要对书架图像信息进行分析就可以找到错位的书籍,前期准备较简单,后续也不需要过多维护,适用于各大图书馆。
上面结合附图对本发明的实施方式作了详细地说明,但是本发明并不局限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!