一种高精度提取和快速分类的三维模型数据解析方法与流程
本发明属于计算机信息处理技术领域,尤其涉及三维模型数据解析方法。
背景技术:
三维数据模型是一种半结构化的数据,用户可任意地设定元素标记和它们间的嵌套关系,以dae为例,dae文件的数据模式是一份非常重要的信息,只有获取了一份dae文件的数据模式,才有利于识别文件的真实含义,为后续的数据分类、聚类和数据挖掘等工作提供了良好的基础。
到目前为止,已经有很多研究针对三维模型数据的提取提出了各种各样的算法,为相关研究提供了重要的思路。jun-kimin等人提出一种基于元素内容模型的提取方法,该方法对元素内容模型进行限制,在元素的内容模型中,子元素只能出现一次。该方法中使用自底向上的方法,先得到子元素的模式,再根据子元素的模式提出父元素的模式。svetlozarnestorov等人提出从半结构化数据中提取模式信息的方法。该方法用有向标记图来描述半结构化数据,使用一元datalog程序的最大不动点的语义定义半结构化数据的数据类型。但这些算法也存在着相应的缺点,主要体现在两方面:①不够精确。②算法复杂度高。利用最优级正则表达式固然可以得到很精确的模式,但是正则表达式生成给系统带来很大的开销。这很大程度上是因为其语言的半结构化特点,使其模式缺乏强制性,给数据的提取工作带来了很大的困难。而二叉树是一种折中的方式,即使是在二叉树步数较大时,仍可以精确地获得理论数据。故本文采用一种二叉树的算法来提取数据,对于复杂度很大的三维模型文件,能迅速得到其有效的数据;同时,对于文档中有可选和重复标记等情况,也能够给出准确的判别和处理。
而在模型所提数据的归纳分类上,也有众多的研究,传统的机器学习分类模型有决策树、贝叶斯、人工神经网络、支持向量机等,但这些模型存在维数灾难和训练时间较长等弊端。而极限学习机算法,随机产生输入层与隐含层间的连接权值及隐含层神经元的阈值,且在训练过程中无需调整,只需设置隐含层神经元的个数,便可获得唯一的最优解,与传统的神经网络算法相比,极限学习机方法学习速度快、泛化性能好。最终,本文采用二叉树与改进极限学习机一同使用的方法,对三维模型文件进行解析,输出文档。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种减少了冗余数据的堆叠,加快了数据的处理速度,提高解析效率的高精度提取和快速分类的三维模型数据解析方法。本发明的技术方案如下:
一种高精度提取和快速分类的三维模型数据解析方法,其包括以下步骤:
1)、首先读取三维模型数据,抽取出三维模型数据中的所有元素标记,所述元素标记包括开始标记和结束标记,并用一个标记结点来表示;将标记结点按顺序逐一编号从而生成标记链;
2)、建立二叉树结点模型,通过步骤1)得到的标记链以及其中标记结点的编号,将同一名称的开始标记和结束标记配成一对,同时将他们对应的标记结点配对为一组,再根据比较标记结点的编号数值大小来分析各元素标记的嵌套关系;
3)、极限学习机是单隐层神经网络,本算法中改进极限学习机采用双层模型,加快训练速度,然后使用这种改进极限学习机方法,训练步骤2)中的二叉树结点模型判断和删除标记二叉树中的冗余数据,从而得到三维模型文件的最简文档。
进一步的,所述步骤1)是通过自动状态机来抽取三维模型数据中所有的元素标记,所述元素标记包括开始标记和结束标记,并将所得的元素标记通过链表结点来表示。
进一步的,所述将所得的元素标记通过链表结点来表示,具体包括:
首先将文档中所有的开始和结束标记抽取出来,并用一个标记结点elementnode表示,所述标记结点的格式为:(charelemstring,intnum,intmatchnum,elementnode*next),其中,elemstring用来记录标记字符串;num表示当前标记结点在链表中的编号;matchnum表示:如果当前结点是元素的开始标记,记录链表中与当前结点相配对的结束标记结点的编号;如果结点本身是结束标记,则该项置为空;next是指向下一个结点的指针。
进一步的,所述步骤2)建立二叉树结点模型的步骤包括:所述二叉树结点模型由nodestring,treenode*leftchild,tree-node*rightchild三类组成,其中nodestring表示当前开始标记结点所包含的标记字符串;leftchild:左子树结点指针,如果当前结点的leftchild不为空,则表示leftchild指向的结点嵌套于当前结点,它们互为父子关系;rightchild:右子树结点指针,如果当前结点的rightchild不为空,则表示rightchild指向的结点和当前结点嵌套于同一个标记,它们互为兄弟关系。
进一步的,所述步骤2)分析各元素标记的嵌套关系,其规则有如下两点:①识别根元素;找出标记链中最大的节点值,识别出最大的节点值为根元素节点;②对非根元素,通过遍历追踪链表的移动指针,从而验证模型数据的嵌套关系。
进一步的,所述步骤3)采用节点对比的方法剔除数据的重复冗余,具体包括:通过将所有结点和其非空右子结点进行比较,如果标记不相同则没有重复的标记,如果相同也还会有两种不同情况:(1)以当前结点为根的树和以其右子结点为根的树完全相同:表示两个元素标记完全相同,可直接将当前结点的右子结点置为空以删除这个冗余标记;并将当前结点标识为可重复标记;(2)以当前结点为根的树和以其右子结点为根的树比较不完全相同,表示有不同可选标记嵌套于当前结点标记或其右子结点标记中,这种情况下则在删除当前结点的右子结点之前,将嵌套于右子结点但不嵌套于当前结点的标记合并到当前结点的子结点中,使其嵌套于当前结点。
进一步的,所述步骤3)使用改进极限学习机方法得到三维模型文件的最简文档,包括分为训练阶段和预测阶段,这一模型目的是利用训练样本集在输入变量和分类结果间建立一种映射关系;
对应的结构化向量定义为:dsv=<d1,d2,…,dn>,n为特征术语对应的特征向量的个数;其中di为第i个三维模型文件的特征术语对应的特征向量:
具体步骤如下:
输入:训练集fd,测试集ft,激活函数g(x);隐藏节点数l(l≤t);核函数k,参数c和γ,随机选择输入权重wi和偏移量bi。
输出:分类结果xt和yt。
步骤2.1:首先随机选择训练样本,然后分别对相应的三维模型文件进行预处理,得到三维模型文件的向量表示。最后,通过提出的改进极限学习机方法快速建立分类模型。
步骤2.2:转换fd到向量模型ms-vsm,得到原始训练数据集d。
步骤2.3:转换ft到向量模型ms-vsm,得到原始训练数据集t。
步骤2.4:将d作为新的训练集,从而减小训练错误,进行特征抽取,得到特征矩阵x,将x作为下一层的输入计算分类结果xt。
步骤2.5:重复以上训练步骤得到参数l,c,γ的最优值。
步骤2.6:将t作为新的训练集,从而减小训练错误,进行特征抽取,得到特征矩阵y,将y作为下一层的输入计算分类结果yt。
最终综合数据提取和归纳分类,给出最终文档。
本发明的优点及有益效果如下:
本发明采用一种二叉树的算法来提取数据,对于复杂度很大的三维模型文件,能迅速得到其有效的数据;同时,对于文档中有可选和重复标记等情况,也能够给出准确的判别和处理。
然后采用极限学习机算法,极限学习机方法学习速度快、泛化性能好,随机产生输入层与隐含层间的连接权值及隐含层神经元的阈值,在训练过程中无需调整,设置隐含层神经元的个数,获得唯一的最优解。
最终,本发明采用二叉树与极限学习机一同使用的方法,并改进了极限学习机,采用双层模型,加快训练的速度。对三维模型文件进行数据提取,归纳分类,提高了提取数据的准确率,并且加速了数据分类,最终完成解析,输出文档。
附图说明
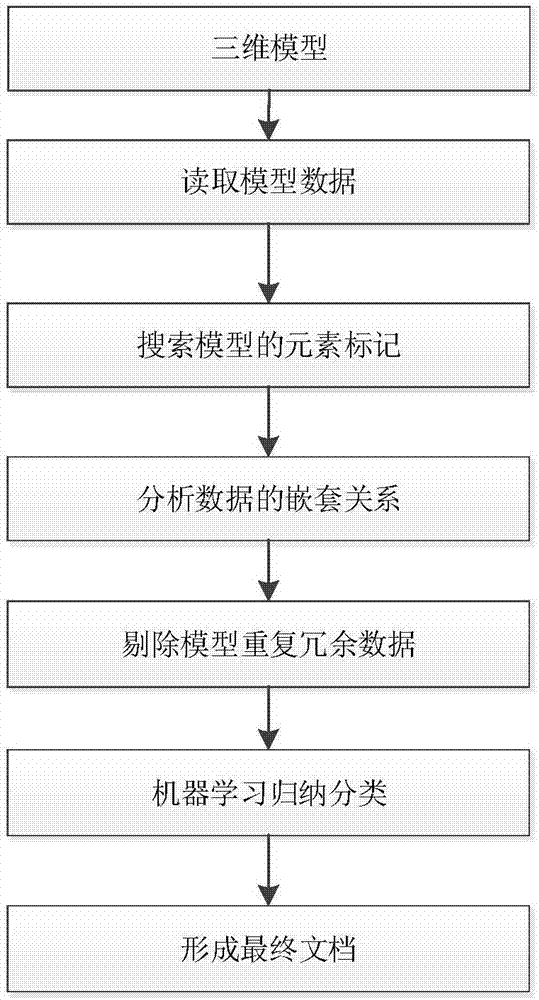
图1是本发明提供优选实施例的总体实现框架;
图2给出了本发明下一种使用二叉树将三维模型数据提取并剔除重复冗余数据的流程图;
图3给出了本发明下一种使用改进极限学习机的模型所提数据归纳分类方法。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
图1的内容就是总体实现框架,具体内容分为数据提取与数据分类两项。
当接收到一份三维模型文件时,首先使用将模型文件转成可读文本形式。采用二叉树的方法从模型中提取非重复数据,也就是图2的内容。步骤如下
步骤1.1:识别出三维模型文件中所有的元素标记。通过一个简单的自动状态机抽取出三维模型数据中的所有元素标记,所述元素标记包括开始标记和结束标记,并用一个标记结点来表示;将标记结点按顺序逐一编号从而生成标记链。首先将文档中所有的开始和结束标记抽取出来,并用一个标记结点elementnode(charelemstring,intnum,intmatchnum,elementnode*next)来表示。其中,elemstring用来记录标记字符串;num表示当前标记结点在链表中的编号;matchnum表示:如果当前结点是元素的开始标记,记录链表中与当前结点相配对的结束标记结点的编号;如果结点本身是结束标记,则该项置为空;next是指向下一个结点的指针。分析标记链中结点之间的嵌套关系,建立二叉树结点模型,模型由nodestring,treenode*leftchild,tree-node*rightchild三类组成,其中nodestring表示当前开始标记结点所包含的标记字符串;leftchild:左子树结点指针,如果当前结点的leftchild不为空,则表示leftchild指向的结点嵌套于当前结点,它们互为父子关系;rightchild:右子树结点指针,如果当前结点的rightchild不为空,则表示rightchild指向的结点和当前结点嵌套于同一个标记,它们互为兄弟关系。
步骤1.2:分析所得标记之间的嵌套关系。通过上一步得到的标记链按顺序进行编号,再根据与每个标记结点配对的标记编号来分析各元素标记的嵌套关系。分析模型的嵌套关系,其规则有如下两点:①识别根元素;找出标记链中最大的节点值,识别出最大的节点值为根元素节点②对非根元素,通过遍历追踪链表的移动指针,从而验证模型数据的嵌套关系。
步骤1.3:剔除重复冗余。采用节点对比的方法剔除数据的重复冗余。可以通过将所有结点和其右子结点(如果不为空)进行比较,如果标记不相同则没有重复的标记,如果相同也还会有两种不同情况:(1)以当前结点为根的树和以其右子结点为根的树完全相同:表示两个元素标记完全相同,可直接将当前结点的右子结点置为空以删除这个冗余标记;并将当前结点标识为可重复标记。(2)以当前结点为根的树和以其右子结点为根的树比较不完全相同,表示有不同可选标记嵌套于当前结点标记(或其右子结点标记)中。这种情况下则在删除当前结点的右子结点之前,将嵌套于右子结点但不嵌套于当前结点的标记合并到当前结点的子结点中,使其嵌套于当前结点。
当拿到剔除重复冗余数据之后,将数据归纳分类,这里采用改进极限学习机的方法,也就是图3的内容。整个模型的实施过程可以分为训练阶段和预测阶段。这一模型目的是利用训练样本集在输入变量和分类结果间建立一种映射关系。
对应的结构化向量定义为:dsv=<d1,d2,…,dn>,n为特征术语对应的特征向量的个数;其中di为第i个三维模型文件的特征术语对应的特征向量:
具体步骤如下:
输入:训练集fd,测试集ft,激活函数g(x);隐藏节点数l(l≤t);核函数k,参数c和γ,随机选择输入权重wi和偏移量bi。
输出:分类结果xt和yt。
步骤2.1:首先随机选择训练样本,然后分别对相应的三维模型文件进行预处理,得到三维模型文件的向量表示。最后,通过提出的改进极限学习机方法快速建立分类模型。
步骤2.2:转换fd到向量模型ms-vsm,得到原始训练数据集d。
步骤2.3:转换ft到向量模型ms-vsm,得到原始训练数据集t。
步骤2.4:将d作为新的训练集,从而减小训练错误,进行特征抽取,得到特征矩阵x,将x作为下一层的输入计算分类结果xt。
步骤2.5:重复以上训练步骤得到参数l,c,γ的最优值。
步骤2.6:将t作为新的训练集,从而减小训练错误,进行特征抽取,得到特征矩阵y,将y作为下一层的输入计算分类结果yt。
最终综合数据提取和归纳分类,给出最终文档。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!