对于网络特征词进行数据模型筛选方法与流程
本发明涉及计算机数据挖掘领域,尤其涉及一种对于网络特征词进行数据模型筛选方法。
背景技术:
由于互联网应用十分普及,但是对于网络环境中海量的数据无法得到及时的归类以及提炼,通常网络使用者都会对海量的数据束手无策,现有技术中协同过滤的推荐方法利用用户的兴趣偏好相似性来产生推荐,把相似用户喜欢关键词或者特征点推荐给对应节点。但是匹配的并不准确和完整。这就亟需本领域技术人员解决相应的技术问题。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种对于网络特征词进行数据模型筛选方法。
为了实现本发明的上述目的,本发明提供了一种对于网络特征词进行数据模型筛选方法,包括如下步骤:
s1,根据遗传算法形成特定网络环境特征词的计算模型,用户形成特征词预测模型:
其中,a1为简单特征词记录值;a2为词组特征词记录值;a3为句式特征词记录值;wa为特征词相关程度权重,pi为特征词动态变化趋势量;ri为特征词获取完成量;
s1-2,选择特征词网络预测模型:
其中,b1为陌生网络特征词出现频率预测值;b2为熟悉网络特征词出现频率预测值;b3为二级域名网络特征词出现频率预测值;b4为一级域名网络特征词出现频率预测值;r为诊断周期分量;vj为特征词出现率随机干扰分量,t为响应周期,
s2,对于特征词分布考虑到各种特性之间的相关性,定义n为特征词匹配成功数据,l为特征词匹配未成功数据,m为未进行匹配的特征词数据,sk为特征词种类分量,b为偏移值,
xk,yk∈n+lorxk,yk,zk∈n+l+m;
s2-2,进行特征词分布目标函数构建,形成特征词数据的目标函数算法如下:
w为特征词出现次数的偏置项,δ为特征词数据噪声,pi(k)为特征词选择过程向量,k为特征词数量,ew为迭代分量,字母w为区分度,下标i为正整数;
用该目标函数来度量过程向量ci(k)的平滑状态值;
得到的平滑部分和高斯混合模型的似然估计进行线性组合,其中
优选的,包括如下步骤:
该算法不仅考虑了数据的正态分布信息,也考虑了数据间的几何结构信息通过度量平滑度最终将特征词分布相关度进行优化划分做准备。
综上所述,由于采用了上述技术方案,本发明的有益效果是:通过对特征词种类预测形成初步计算条件;从而筛选出特征词分布结果;该算法不仅考虑了数据的正态分布信息,也考虑了数据间的几何结构信息通过度量平滑度最终将特征词分布相关度进行优化划分做准备;然后完成最大值的提炼数据集,把特征词数据进行收集整理。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
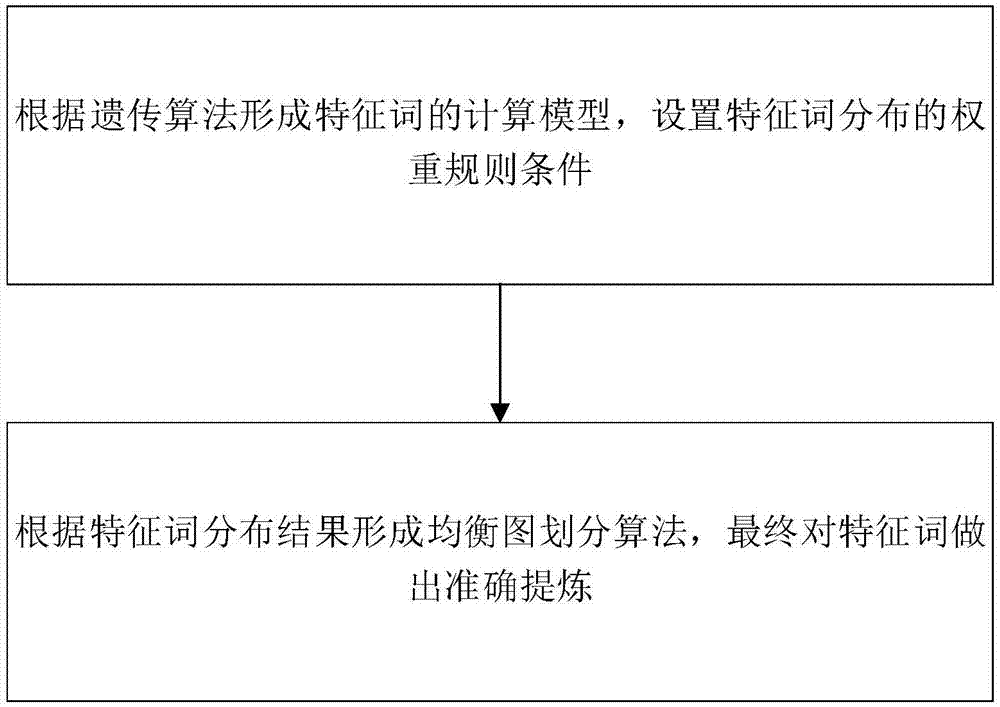
图1是本发明工作流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
如图1所示,本发明提供了一种对于网络特征词进行数据模型筛选方法,包括如下步骤:
s1,根据遗传算法形成特定网络环境特征词的计算模型,用户形成特征词预测模型:
其中,a1为简单特征词记录值;a2为词组特征词记录值;a3为句式特征词记录值;wa为特征词相关程度权重,pi为特征词动态变化趋势量;ri为特征词获取完成量;
s1-2,选择特征词网络预测模型:
其中,b1为陌生网络特征词出现频率预测值;b2为熟悉网络特征词出现频率预测值;b3为二级域名网络特征词出现频率预测值;b4为一级域名网络特征词出现频率预测值;r为诊断周期分量;vj为特征词出现率随机干扰分量,t为响应周期,
s2,对于特征词分布考虑到各种特性之间的相关性,定义n为特征词匹配成功数据,l为特征词匹配未成功数据,m为未进行匹配的特征词数据,sk为特征词种类分量,b为偏移值,
xk,yk∈n+lorxk,yk,zk∈n+l+m;
s2-2,进行特征词分布目标函数构建,形成特征词数据的目标函数算法如下:
w为特征词出现次数的偏置项,δ为特征词数据噪声,pi(k)为特征词选择过程向量,k为特征词数量,ew为迭代分量,字母w为区分度,下标i为正整数;
用该目标函数来度量过程向量ci(k)的平滑状态值;
得到的平滑部分和高斯混合模型的似然估计进行线性组合,其中
优选的,包括如下步骤:
该算法不仅考虑了数据的正态分布信息,也考虑了数据间的几何结构信息通过度量平滑度最终将特征词分布相关度进行优化划分做准备。
采用标签传播的方法,每次迭代过程中进行特征词相关度匹配,从而对特征词诊断过程中提炼出相关特征词经常入住的医院和医院级别;
为了防止过大的提炼数据集出现,对数据集的规模以及迭代次数进行了限制,每个数据集规模条件为
载入提炼数据集规模条件进行累加之后,如果
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!