一种基于深度迁移度量学习的小样本目标识别方法与流程
本发明属于深度学习及目标识别技术领域,涉及一种基于深度迁移度量学习的小样本目标识别方法。
背景技术:
在机器学习领域,小样本学习相关的研究工作是近年的发展重点,其中包括:1)迁移学习:是指利用数据、任务、或模型之间的相似性,将在旧领域(源域)学习过的模型,应用于新领域(目标域)的一种学习过程。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。迁移学习的核心问题是,找到新问题和原问题之间的相似性,实现知识的顺利迁移。2)度量学习:亦即相似度学习,是对样本间距离分布进行建模,使得属于同类样本靠近,异类样本远离。目前比较好的方法可学习一个端到端的最近邻分类器,它同时受益于带参数和无参数的优点,对已知样本有很好的泛化性,且对新样本有良好的拓展能力。
针对遥感影像小样本目标检测识别问题,上述的机器学习方法提供了可借鉴之处,但若直接套用,则还存在诸多局限:1)迁移学习对源域有较严格的限制,为了保证“正迁移”,要求源域与目标域有强关联;2)属性学习针对特定目标如何定义属性以及如何保证属性的鉴别能力,尚无明确规范;3)半监督学习对未标记样本的真实类别也有限制等等。
本发明所提出的基于深度迁移度量学习的小样本目标识别方法就是将充分利用目标的先验信息作为突破口。充分利用目标的先验信息是指深入挖掘出的待识别目标类型与已有目标类型样本在空间分布上的结构相似性,迁移相似样本上蕴含的通用信息。多类别的小样本学习,鉴于相似类别样本在三维结构/纹理上的相似性,其在高维空间的局部流形结构也存在一定程度上的相似性。度量学习提供了利用此相似性先验知识的一个合理框架,进而提高了小样本学习的泛化能力。在度量学习框架下,学习特征空间中目标局部流形结构及参数,计算图像对之间的相似性测度。
技术实现要素:
本发明的目的在于针对传统小样本目标识别方法的不足,为深度学习及视频分析研究提供一种基于深度迁移度量学习的小样本目标识别方法。
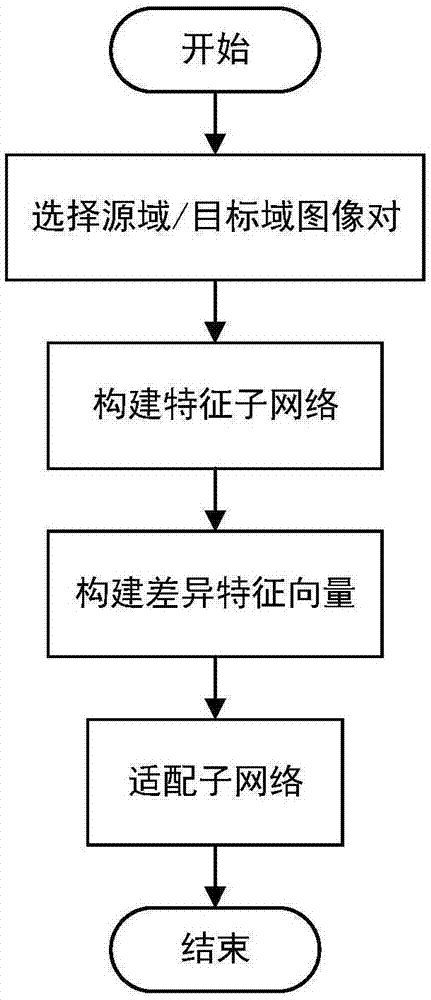
本发明方法包括以下步骤:
步骤(1)、选择源域与目标域图像对。
目标域图像对是一对待识别的目标遥感图像,源域图像对是一对目标类别相近的遥感图像,如一对具体型号的相近类的目标图像,以确保源域图像的信息能够有效迁移到目标域。
源域图像对分为正样本和反样本,其中属于同一目标类别的为正样本,反之则为反样本。例如在同一型号或不同型号图像集中选择图像对,如果2张图像来自同一型号,则该图像对视为正样本,反之则为反样本。
步骤(2)、构建特征子网络。
直接提取典型深度网络(alexnet,vgg-16/vgg-19)的前几个卷积层,构建特征子网络。输入为目标域图像对与源域图像对,输出为可作为通用特征的上述前几个卷积层。
步骤(3)、构建差异特征向量。
提取源域与目标域图像的特征,采用典型特征提取方法以保证样本描述在特征空间上具有紧致性;用差异特征向量表示源域与目标域图像对在特征空间上的相对距离,将目标域图像对相应的特征子网络输出相减并转换为一维向量,从而获得源域差异特征向量;将源域图像对相应的特征子网络输出相减并转换为一维向量,从而获得目标域差异特征向量。
这里的典型特征可以是方向梯度直方图(hog)特征、局部二值模式(lbp)特征等。
步骤(4)、适配特征子网络。
适配子网络的目的是适配源域与目标域之间的分布差异,确保源域的信息能够合理迁移到目标域,适配是深度迁移度量学习的核心处理环节。
采用多核最大均值差异(multi-kernelmaximummeandiscrepancy,mk-mmd)描述源域与目标域样本的分布差异。最大均值差异是将源域的一维差异特征向量与目标域的一维差异特征向量用同一个核函数映射到高维空间,然后求映射后两部分数据的均值差异,就当作是两部分数据的差异。
构建多核mmd,具体采用多个核函数去构造一个总的核函数:
其中ku是第u个单个核函数,βu是对应的权重系数βu≥0。m表示总核函数数量。
对于源域差异特征向量和目标域差异特征向量的概率分布p与q,它们的mk-mmd距离可表示为:
其中,xs、xt分别是源域样本与目标域样本,φ是特征映射函数,满足:k(xs,st)=<φ(xs),φ(xt)>。ep[]表示函数在p分布上的数学期望。
对特征子网络中源域与目标域对应的每个卷积层均进行适配,对应的优化目标函数为:
其中,θ表示网络的所有权重和bias参数,是用来学习的目标。其中l1,l2分别是适配层的最小卷积层与最大卷积层(大小根据卷积维数判断)。xa,ya分别表示源域、目标域数据集中所有正样本的,na是该数据集的元素个数。λ是惩罚系数。j(·)定义了一个损失函数,如深度网络中一常用的交叉熵。
在适配子网络的训练过程中,不断输入不同的正反样本进行迭代学习,直至所有样本输入完毕,优化上述目标函数,调整网络参数θ与核函数权重β。
步骤(5)、目标识别
在步骤(4)中适配好的子网络作为分类器,输入一对待识别的目标图像,输出它们是否同类的分类信息,完成目标识别。
本发明的有益效果是:针对遥感影像目标检测识别问题,在图像样本分布的高维空间,度量学习构建了同类或异类的2张图像样本之间的差异模型,通过这种方式,度量学习实际上是给学习过程施加了一个约束条件:待识别的多个类在高维空间的局部分布结构保持一致,从而利用多类样本共同学习一个统一模型,提高了小样本学习的泛化能力。迁移度量学习,引入源域样本,设计了一个合理的适配过程,一方面尽量挖掘相同分布信息,提高对目标域局部流形结构估计的精度;另一方面也尽量规避不同部分信息,避免了对目标域的学习引入干扰。
本发明的关键在于充分利用待识别目标类型与已有目标类型样本在空间分布上的结构相似性这一目标的先验信息进行迁移学习;同时利用度量学习将差异特征向量映射到高维,对样本间距离分布进行建模,使得属于同类样本靠近,异类样本远离。本发明由于有机结合了迁移学习与度量学习这两种机器学习方法,突破现有小样本学习方法的局限,方法简单易于实现,对使用传统方法的工程无需重新构造,详细兼容,能够节省大量人力。并且可以与其它小样本目标识别的方法相结合,对提高目标检测识别(特别是目标具体型号识别)精度有重要意义。
附图说明
图1为本发明的流程图。
图2为本发明各网络构建设计图。
具体实施方式
下面结合具体实施例对本发明做进一步的分析。
本实施例采用舰船图像作为样本数据集。在基于深度迁移度量学习的小样本目标识别过程中具体包括以下步骤,如图1、2所示:
步骤(1)、选择源域/目标域图像对。
以舰船为例,目标域图像是若干对待识别的某型号军事舰船图像,源域图像对是类似的图像对,如一对具体型号的民船/商船的舰船图像。在同一型号或不同型号图像集中选择图像对,如果2张图像来自同一型号,则该图像对视为正样本,反之则为反样本。
步骤(2)、构建特征子网络。
直接提取典型深度网络alexnet的前3个卷积层,分别为55*55*96、27*27*256、13*13*384的特征图,作为通用特征,构建特征子网络。
步骤(3)、构建差异特征向量。
用差异特征向量表示源域与目标域图像对在特征空间上的相对距离,将目标域上述图像对相应的特征子网络输出相减并转换为一维向量,从而获得源域差异特征向量;将源域图像对相应的特征子网络输出相减并转换为一维向量,从而获得目标域差异特征向量。
步骤(4)、适配子网络。
适配子网络的目的是适配源域与目标域之间的分布差异,是深度迁移度量学习的核心处理环节。
采用多核最大均值差异(multi-kernelmaximummeandiscrepancy,mk-mmd)描述源域与目标域样本的分布差异。最大均值差异是将源域的一维差异特征向量与目标域的一维差异特征向量用同一个核函数映射到高维空间,然后求映射后两部分数据的均值差异,就当作是两部分数据的差异。其中一个重要的概念是核函数,在单核mmd中,这个核函数是固定的,但如何选择一个合适的核函数还是一个需要解决的问题。多核mmd采用多个核函数去构造一个总的核函数:
其中ku是单个核函数,βu是对应的权重系数βu≥0。
对于源域差异特征向量和目标域差异特征向量的概率分布p与q,它们的mk-mmd距离可表示为:
其中,xs、xt分别是源域样本与目标域样本,φ是特征映射函数,满足:k(xs,st)=<φ(xs),φ(xt)>。ep[]表示函数在p分布上的数学期望。
在适配子网络中源域与目标域对应的每个层都需要进行适配,对应的优化目标函数为:
其中,θ表示网络的所有权重和bias参数,是用来学习的目标。其中l1,l2分别是适配层的最小层与最大层,在l1前面的网络层不进行适配。xa表示源域和目标域中所有带标签的数据集,na是该数据集的元素个数。λ是惩罚系数。j(·)定义了一个损失函数,如深度网络中一常用的交叉熵。
在适配子网络的训练过程中,不断输入正反样本迭代学习,优化上述目标函数,调整网络参数θ与核函数权重β。
步骤(5)、目标识别。
在步骤(4)中适配好的子网络即可作为分类器对军事舰船图像进行识别,输入一对待识别的目标图像,输出它们是否同类的分类信息,完成目标识别。
上述实施例并非是对于本发明的限制,本发明并非仅限于上述实施例,只要符合本发明要求,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!