一种基于实体关系联合抽取模型的多三元组抽取方法与流程
本发明涉及文本处理技术领域,特别是指一种基于实体关系联合抽取模型的多三元组抽取方法。
背景技术:
三元组抽取得到结构化的信息(同时抽取两个实体和他们之间的关系)来自非结构化的文本,这是自动知识库构建的一个重要的和关键步骤,传统的模型分别使用命名实体识别(ner)(shaalan,2014)和关系分类(rc)(rinkandharabagiu,2010)抽取实体和关系,产生最后的三元组。这种模块化的方法不能充分捕捉和利用ner和rc的任务之间的相关性,并容易级联错误(liandji,2014)。
为了克服这些缺点,有人提出了联合抽取模型。他们中的大多数是特征结构模型(kateandmooney,2010;yuandlam,2010;chanandroth,2011;miwaandsasaki,2014),这需要过多的人工干预和监督的自然语言处理工具来构建多元化、复杂化的特征。最近,已经提出了一些神经网络模型来联合抽取实体和关系。郑先生等人利用双向长短期记忆网络(bi-lstm)来学习联合的隐藏特征,然后用长短期记忆网络(lstm)抽取实体,用卷积神经网络(cnn)抽取关系(zhengetal.,2017a);miwa和bansal用一个端到端(end-to-end)的模型抽取的实体,依赖树用来确定关系(miwaandbansal,2016)。这两个模型首先识别实体,然后为每一对可能抽取的实体选择一个语义关系,在这种情况下,rc分类器的精度相对较低,但召回率较高,因为它被许多属于其他种类的对所误导;同时,有些模型只能抽取出有限的目标关系。郑先生等人把联合抽取问题转化成标注问题,用一个统一的标注方案标注实体和关系标签,利用端到端的模型来解决这个问题(zhengetal.,2017b);然而,在这个模型中,每一个实体在每个句子中都被限制只涉及一个关系。katiyar和cardie也用双向长短期记忆网络(bi-lstm)抽取实体,并添加一个注意力机制抽取关系(katiyar和cardie,2017),该模型假定一个实体只能与句子中的一个前置实体相关,这两个模型(部分)忽略了与一个实体相关联的多个关系;在这种情况下,rc任务执行的精度相对较高,但召回率较低,因为rc的候选范围是有限的
因此,现有的联合模型不仅在不实用的约束下抽取有限的关系(一句话中只有一个关系,一个实体只关联到一个前置实体),或简单地产生太多的候选人进行rc分类(所有可能的实体对关系)。深入的调查表明,主要原因在于他们忽视多三元组的影响,这在现存的大型语料库中很常见,以图2中的新闻句为例,可以看出,与实体巴黎有两种联系,即(唐纳德·特朗普,到达,巴黎)和(巴黎,位于,法国),然而,上述所有的模型都无法完全捕捉到它们,特别是,模型(zhengetal.,2017b)假设一个实体如巴黎只属于一个三元组,因此,两个三元组会隐藏。模型(katiyarandcardie,2017)发现了一个实体和其一个前置实体的关系,在这种情况下,从巴黎到唐纳德·特朗普和到法国的关系都不会被发现。另一方面,模型(miwaandbansal,2016;zhengetal.,2017a)认为,每一个实体对都有某一种关系,在这种情况下,大量的对需要被扔到一个叫做“其他”的类中,但是“其他”的特性在分类器训练中没有学到,因此,嘈杂的实体(爱丽舍宫)和像唐纳德·特朗普,爱丽舍宫这样的非预期的关系混淆了分类器。因此,可能无法正确地检测/选择多三元组的目标关系。
技术实现要素:
有鉴于此,本发明的目的在于提出一种基于实体关系联合抽取模型的多三元组抽取方法,用于对句子中的多三元组进行有效抽取。
基于上述目的本发明提供的一种基于实体关系联合抽取模型的多三元组抽取方法,其特征在于包括以下步骤:
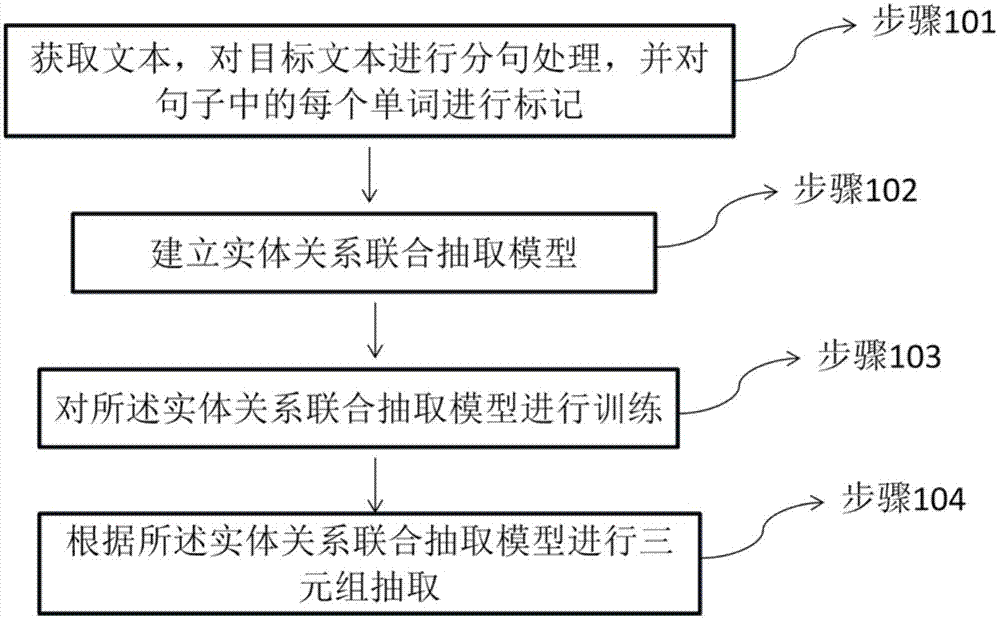
获取文本,对目标文本进行分句处理,并对句子中的每个单词进行标记;
建立实体关系联合抽取模型;
对所述实体关系联合抽取模型进行训练;
根据所述实体关系联合抽取模型进行三元组抽取。
所述对句子中的每个单词进行标记包括对句子中的每个单词进行位置、类型、是否涉及关系三部分进行标记。
所述关系抽取模型包括用于将具有单一语义特征(1-hot)表示的单词转换为嵌入向量的嵌入层、用于对输入句子进行编码的双向长短期记忆bi-lstm层和用于解码的crf层。
进一步,对于任意三元组t=(e1,e2,r)∈t,所述嵌入层包括从所述嵌入层获得头实体向量e1、尾实体向量e2和关系向量r,为更好地保留实体关系特征,要求e1+r≈e2,评分函数为:
其中,t为三元组集合、t为任意三元组、e1为头实体向量、e2为尾实体向量、r为关系向量、f(t)为评分函数。
进一步,所述bi-lstm层包括前向lstm层和反向lstm层,为防止双向lstm输出实体特征出现偏差,要求
其中,
进一步,所述对所述实体关系联合抽取模型进行训练包括建立损失函数,当所述损失函数越小时,模型的精度越高,模型能够更好的抽取句子中的三元组,所述损失函数为:
l=le+λlr;
其中,l为损失函数、le为实体抽取损失、lr为关系抽取损失、λ为权重超参数。
进一步,所述实体抽取损失le取正确标记概率p(y|x)的最大值,所述实体抽取损失le为:
所述关系抽取损失函数为:
其中,x为输入的句子序列;y表示x可能生成的所有序列;y指其中的一个预测序列;
进一步,所述训练集上的基于边界的排序损失函数为:
所述前向lstm损失函数为:
所述反向lstm损失函数为:
其中,t为任意一个三元组;t为三元组集合;t`为负三元组;t`为负三元组集合;f(t')为负三元组的评分函数;
进一步,所述根据实体关系联合抽取模型进行三元组抽取包括:
用下列得分函数的得最高分的序列来对所述实体标签进行预测:
其中,m是候选实体的数量;
本发明一种基于实体关系联合抽取模型的多三元组抽取方法使用了一个额外的关系标记来描述关系特征,从而允许负样例策略来强化模型的训练;本发明设计的三部分标记方案(tri-parttaggingscheme,tts),在关系抽取的过程中能够排除与目标关系不相关的实体;此外,本发明一种基于实体关系联合抽取模型的多三元组抽取方法可以用来抽取多三元组,并且基于本发明三元组抽取方法的模型与其它模型相比有更强的多三元组抽取能力。
附图说明
图1为发明实施例一种基于实体关系联合抽取模型的多三元组抽取方法的流程示意图;
图2为句子中存在多个三元组的示例;
图3为本发明实施例实体关系联合抽取模型的示意图;
图4为本发明三部分标记方案的示例图;
图5为本发明实施例不同的权重超参数λ值对模型准确率的影响图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
作为本发明的实施例,参阅图1所示,为本发明实施例一种基于实体关系联合抽取模型的多三元组抽取方法的流程示意图。所述的一种基于实体关系联合抽取模型的多三元组抽取方法,包括:
步骤101:获取文本,对目标文本进行分句处理,并对句子中的每个单词进行三部分标记。
对句子中的每个单词进行三部分标记包括对句子中的每个单词进行位置、类型、是否涉及关系三部分进行标记;位置标记(positionpart,pp)用来描述实体中每个词的位置,例如,用“bio”来表示实体中第一个单词的位置信息,“b”表示该单词是实体中的第一个单词,“i”表示该单词是实体中第一个单词后的任一个单词,“o”表示该单词位于非实体位置;类型标记(typepart,tp)将单词和实体类型信息联系起来,例如,“per”代表人,“loc”代表地点,“org”代表组织机构;关系标记(relationpart,rp)是指对问题中的实体是否涉及任何关系进行标记,“r”表明该实体涉及句子中的一些关系,“n”表示不涉及任何关系。
如图4所示为一个样本中句子标记的实施例,该句子中包含四个实体和两个目标关系,其中,donald是实体donaldtrump的第一个单词,它的类型是person,并且跟其他实体存在关系,因此,donald的tts标签是“b-per-r”,trump的标签是“i-per-r”。
与传统的bilou标记方案(liandji,2014;miwaandbansal,2016)相比,本发明一种基于实体关系联合抽取模型的多三元组抽取方法的标记方案能够明确哪些是噪音实体,其能够不借助不真实存在的约束产生候选实体对,同时避免过度无关的实体参与每个实体对之间的关系抽取。
步骤102:建立实体关系联合抽取模型。
如图3所示,本发明一种实体关系联合抽取模型包括用于将具有1-hot表示的单词转换为嵌入向量的嵌入层、用于对输入语句进行编码的双向长短期记忆bi-lstm层和用于解码的crf层。
首先,假设对于一个输入句子序列x,w=(w1,w2,...,ws)是词向量序列,
其中e,
其次,对于任意三元组t=(e1,e2,r)∈t,从嵌入层中获得头实体想e1和尾实体向量e2,然后得到一个相匹配的关系向量r,并要求e1加上r约等于e2,即e1+r≈e2;则评分函数为:
相似地,从前向和反向lstm中分别获取实体向量
步骤103:对实体关系联合抽取模型进行训练。
对实体关系联合抽取模型进行训练包括建立损失函数,损失函数l包括两部分,实体抽取损失le和关系抽取损失lr,当损失函数越小时,模型的精度越高,模型能够更好的抽取句子中的三元组,损失函数为:
l=le+λlr
其中,l为损失函数、le为实体抽取损失、lr为关系抽取损失、λ为权重超参数。
在实体抽取的损失函数中,取正确标记序列的概率p(y|x)的最大值,实体抽取损失函数le为:
实体抽取损失le的目的是鼓励模型创建正确的标记序列。
在关系抽取的损失函数中,首先建立负样本集合t'。负样本集合是由初始的正确的三元组和被替换的关系组成的,对于一个三元组(e1,r,e2),用任意一个关系r′∈r替换初始关系r,则负样本t'可以被描述成:
t'={(e1,e2,r')|r'∈r,r'≠r}。
为了训练关系向量和激励区分正面三元组和负面三元组,在隐藏层中取训练集上的基于边界的排序损失函数的最大值,则:
其中γ>0是超参数用来约束正样例和负样例之间的边界,relu=max(0,x)(glorotetal.,2011)。相似地,前向和反向lstm的损失函数可以描述如下:
因此,关系抽取损失函数如下:
其中,x为输入的句子序列;y表示x可能生成的所有序列;y指其中的一个预测序列;
步骤104:根据所述实体关系联合抽取模型进行三元组抽取。
根据关系模型进行三元组抽取,使用下列得分函数,得分最高的序列作为预测序列,得分函数为:
通过预测的标签,选用标签为“r”的单词作为候选实体,将这些结果置入一个集合
因此,如果
本发明的另一个实施例,给出了本发明所建模型与其它模型分别对三元组进行抽取的结果的比较。
本发明不同模型对三元组抽取结果的比较选用的样本集为nyt(riedeletal.,2010)和nyt(2)。
nyt包含newyorktimes从1987到2007年的文章,总计包含235k句子。无效的和重复的句子已经被过滤掉,最终得到67k的句子。特别地,测试集包含395个句子,其中大多数句子都包含一个三元组。
nyt(2)是一个从nyt中导出的数据集,它是为了进行多三元组抽取而特别构造的。从nyt中任意取出1000条句子作为测试集,并把剩余部分作为训练集。不同于nyt,测试集中较大比例(39.1%)的部分包含超过一个三元组。
表1为数据集统计量。
本发明三元组抽取模型记为tme,本发明三元组抽取模型的变体tme-rr指用随机的和稳定的关系向量r来进行模型训练,tme-ns指分别用额外的关系向量
对于参数设置,选择词向量dw的维度的取值范围是{20,50,100,200},字符特征向量dch的取值范围是{5,10,15,25},大小写特征向量dc的取值范围是{1,2,5,10},正负样例三元组的边界γ的取值范围是{1,2,5,10},权重超参数λ的取值范围是{0.2,0.5,1,2,5,10,20,50};dropout比率设置从0到0.5之间;随机梯度下降(amari,1993)用来使损失函数最优化。从测试集里任取10%的句子做验证集,剩下的被作为评价集。最理想的参数是λ=10.0,γ=2.0,dw=100,dch=25,dc=5,dropout=0.5。
表2为各模型在nyt上的实验结果。
其中,tme(top-1)表示模型中的每个句子中最多抽取一个三元组,tme(top-2)表示模型中的每个句子中最多抽取两个三元组,tme(top-3)表示模型中的每个句子中最多抽取三个三元组,tme(top-1)-pretrain表示向量未经过预训练时的抽取结果。
从表2可以看出,相比其他模型,tme(top-1)取得了卓越的结果,f1值增长到了0.530,胜过第二名nts-joint7个百分点;证明本发明基于排序和迁移的模型能够更加适应地处理实体对之间的关系。
表3为各模型在nyt(2)上的实验结果。
从表3可以看出,tme(top-2)的f1值增至0.567,相比于nts-joint增涨了36.7%,tme(top-2)取得了nyt(2)样本集上的最佳结果,可以证明其对于处理多三元组的能力优于其他模型。
本发明一种基于实体关系联合抽取模型的多三元组抽取方法的另一个实施例对tme模型的成份进行了分析,表4为分析结果:
表4为本发明tme模型的成份分析结果。
表中,tme为本发明基于排序和迁移的模型,其中,-tts(-tp)指移除单词三部分标记中的类型标记部分,-tts(-rp)指移除单词三部分标记中的关系标记部分,-tts(-tp-rp)指同时移除单词三部分标记中的类型和关系标记部分。
由表4可以看出,在tme(top-2)中,引入关系标记后,三元组抽取的精度显著提高,提高了42.6%,但召回率仅下降1.3%,说明在模型中引入关系标记可以有效过滤掉与目标关系不相关的实体。
本发明一种基于实体关系联合抽取模型的多三元组抽取方法的另一个实施例给出了不同的权重超参数λ值对模型准确率的影响;如图4所示,若λ>20或λ<5,f1值下降。当λ=10时,tme在实体和关系抽取之间达到平衡,得到了杰出的f1值。
本发明的又一个实施例给出了tme(top-3)(表示模型中的每个句子中最多抽取三个三元组)对句子中的实体及关系抽取结果。
表5为tme(top-3)的案例研究(其中,加粗实体表示预测的存在关系的实体,斜体实体表示预测的不存在关系的实体,加粗的的三元组表示正确的且被预测出来的三元组)。
由表5可以看出,tme可以对每个句子中的多三元组进行抽取,不仅可以对每个实体包含不同的关系(句子ii)的三元组进行抽取,而且可以对每个句子包含多个不同实体对之间的同类关系(句子iii)的三元组进行抽取。
在句子i和句子ii中,不相关的实体iran和unitedstates证明基于本发明三部分标记方案的三元组抽取模型可以有效提高句子中三元组抽取的性能。
综上所述,本发明一种基于实体关系联合抽取模型的多三元组抽取方法使用了一个额外的关系标记来描述关系特征,从而允许负样例策略来强化模型的训练;本发明设计的三部分标记方案,在关系抽取的过程中能够排除与目标关系不相关的实体;此外,本发明一种基于实体关系联合抽取模型的多三元组抽取方法可以用来抽取多三元组,并且基于本发明三元组抽取方法的模型与其它模型相比有更强的多三元组抽取能力。
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本公开的范围(包括权利要求)被限于这些例子;在本发明的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本发明的不同方面的许多其它变化,为了简明它们没有在细节中提供。
本发明的实施例旨在涵盖落入所附权利要求的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本发明的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!