基于少量样本的风格字符生成方法与流程
本发明涉及一种风格字符生成方法,尤其涉及一种基于少量样本风格的手写或印刷体字符生成方法。
背景技术:
根据z.h.lian等人在siggraphasia2016发表的论文《automaticgenerationoflarge-scalehandwritingfontsviastylelearning》中描述的模型,用户可根据其提供的接口输入自己手写的部分字符,从而得到一些模型输出的风格类似的字符。例如,用户提供266个字符输入到模型中可以得到27533个风格类似的字符。但是,该模型的训练需要提供大量的标注数据,并且需要用户较为规范的输入才能得到预期的结果,在较少标注数据的情况下的效果不好。模型的重点在于分离出字体的各个笔画,再输入到神经网络中进行学习,从而根据笔画的风格来学习到整个字体的风格。但其构造仅仅是简单的多层卷积网络,对于稍微复杂的输入例如较潦草的字符,则效果一般。并且模型的泛化能力不足。
zi2zi是一种基于风格转换通用模型pix2pix(isola,phillipandzhu,jun-yanandzhou,tinghuiandefros,alexeia,《image-to-imagetranslationwithconditionaladversarialnetworks》)的字符风格学习模型,它通过16层深度卷积/反卷积网络来实现从标准字体到有风格字体到风格迁移任务。每一种手写体的风格信息由一个1*128维的随机向量来表示,表示多个手写体风格的随机向量矩阵我们称之为categoryembedding。
将表示风格信息的随机向量输入16层的深度卷积/反卷积网络中,使标准字体向用户手写风格靠近。当训练样本足够多时,能够生成较好的字体。然而模型参数数量巨大,难以训练,并且需要很多训练样本才能够完成任务。同时,因为训练时需要固定所有涉及到的手写字体,该模型无法处理未知手写字体的生成任务。
基于以上模型,z.h.lian等在siggraphasia2017发表的论文《dcfont:anend-to-enddeepchinesefontgenerationsystem》则提出了原本模型的改进方法:引入条件生成式对抗网络(cgan),将学习笔画轮廓替换为在标准字体(例如楷体)的基础上加入手写风格的特征。手写特征提取则由生成器(encoder-decoder)和vgg-16深度卷积网络完成。然而模型的问题仍然是无法处理很潦草的输入字符风格问题,并且需要较多的训练样本。
技术实现要素:
本发明的目的是提供一种基于少量样本的风格字符生成方法,该手写字符生成方法实现了根据同一风格的少量(甚至一个)字符生成相应风格的字体,包括手写体和印刷体。
为达到上述目的,本发明采用的技术方案是:一种基于少量样本风格字符生成方法,其特征在于:以若干种(多余50种)手写体字符为手写体风格迁移目标,或者若干种常见印刷体(多余50种)字符为印刷体风格迁移目标,以及一种标准字体的字符作为风格迁移源,使用基于深度生成对抗网络的图像翻译模型,训练出一个字符风格迁移的字符生成模型;
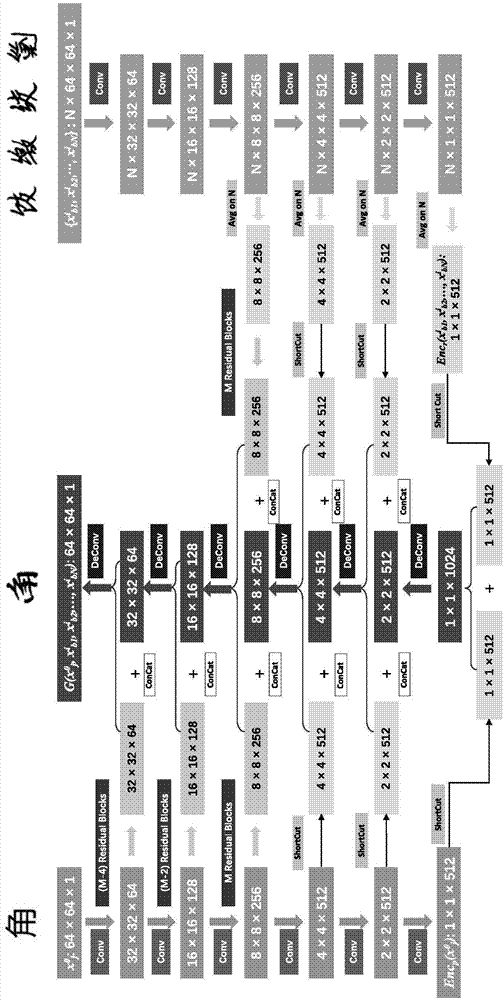
所述字符生成模型由内容原型编码器contentprototypeencoder,encp,风格参考编码器stylereferenceencoder,encr和解码器decoder,dec所组成,因为两个编码器从结构上来说是并列的关系,因此,网络的总层数是12层;
所述内容原型编码器contentprototypeencoder,encp输入数据为一个带有标准风格的字符(x0j),表示成长宽为64*64,值域在[0,255]之间的的灰度图片,输出为经过若干个残差单元(residualblocks)或者直接连接的各级卷积特征;该内容原型编码器由连续的卷积(conv)间隔步幅值为2的卷积运算,用于提取所输入的标准字符(x0j)从低级(像素级)到高级(隐空间)的各级特征,每级特征较之其上一级特征,特征长宽减半,其所得到的标准字符的最高级特征,长宽均为1;
所述风格参考编码器stylereferenceencoder,encr,其输入为带有某一种风格(风格用i来表示)n个不同字符({xib1,xib2,…,xibn}),同样表示成长宽为64*64,值域在[0,255]之间的的灰度图片;输出为对各级卷积特征对n进行平均运算后,再经过若干个残差单元(residualblocks)或者直接连接的各级卷积特征;
该风格参考编码器基本结构与encp相似,但为了处理一次性输入的多个(n个)带有某种书写风格字符(假设为第i个风格,{xib1,xib2,…,xibn})的平均特征,对应这些n个字符的n个卷积特征首先需要对n进行平均运算,从而得出这n个字符({xib1,xib2,…,xibn})的1个各级平均卷积特征,此后再放入若干个残差单元(residualblocks)或者直接连接后送入dec;
所述内容原型编码器encp、风格参考编码器encr对各自输入数据进行特征提取,并将提取过后的信息串联后输入解码器网络decoder,dec;dec解码器网络对从内容原型编码器encp和风格参考编码器encr的输入来的各级卷积特征进行串联(concat)后进行恢复及重建,输出带有某一种的风格的生成字符(g(x0j,xib1,xib2,…,xibn)),亦表示为同样表示成长宽为64*64,值域在[0,255]之间的灰度图片;
该生成字符的内容来源于输入到encp的标准字符(x0j),风格来源于输入到encr的n个带有第i个风格的字符(({xib1,xib2,…,xibn});
该解码器由连续的卷积间隔步幅值为2的反卷积(deconv)运算所组成,即后一级特征的长宽是前一级特征的两倍,最终生成与输入的无风格标准字符长宽一致的具有特定风格的字符;
包括以下步骤:
步骤一、训练开始之前,需要对字符生成模型的参数进行随机初始化,从而给定训练的开始状态;
步骤二、我们使用随机优化(stochasticoptimization)的训练策略来对该字符生成模型进行训练,训练目标即为最小化训练误差
步骤三、当
步骤四、获取某个书写风格的任意若干个字符(假设为n个,一般n<=32,{xib1,xib2,…,xibn}),并将此n个字依次输入到训练完成的字符生成模型的风格参考编码器(encr),得出n份各级卷积特征,对应n个不同的同风格字符;
步骤五,对由encr计算得出的,对应于n个输入的带有同一种书写风格的字符的n份各级卷积特征进行平均计算,得出n份各级卷积特征的平均各级卷积体征(一份);
步骤六、对步骤五所得出的各级卷积特征进行相应的残差单元操作或直接连接操作,保存下各级特征的计算结果,作为此后输入解码器的风格参考特征;
步骤七、向内容原型编码器(encp)输入欲生成字符对应的标准字体字符(黑体,x0j),计算出各级卷积特征后,进行相应的残差单元或者直接连接操作;
步骤八、将两个编码器所得到的各级卷积特征,分别串联到解码器的各级输出特征之上,从而生成欲产生的带有特定风格的任意字符,g(x0j,xib1,xib2,…,xibn)。
上述技术方案中进一步改进的技术方案如下:
1.上述方案中,所述步骤二具体包括以下步骤:
步骤1、我们从训练数据集中随机选取一批训练数据(一批数据的大小一般设置为16个数据)其中一个数据由一对字符组成,包括一个标准字符(x0j)和与之相同的带有某一个特定风格的字符的真实样本(xij);
步骤2、此后,根据所选取的带有某一个特定风格的风格字符(xij),随机从同一个训练数据集中选取另外n个带有同样风格的不同的字符({xib1,xib2,…,xibn});
步骤3、将x0j输入encp,{xib1,xib2,…,xibn}输入encr,从而获取两个编码器各级卷积特征;
步骤4、将上一步获得的两个编码器的各级卷积特征根据图示连接关系送入解码器,从而生成希望生成的带有某一个特定书写风格的字符样(g(x0j,xib1,xib2,…,xibn));
步骤5、将上一步所生成的字符样本计算以下两个训练误差:
(1)生成样本g(x0j,xib1,xib2,…,xibn)与数据库中真实样本(xij)的1-范数误差,即:
(2)除了以上像素层面上的第几特征的1-范数误差,本专利在训练过程中也考虑到了高级特征误差,我们使用一个预先训练好的vgg-16(simonyan,karen,andandrewzisserman."verydeepconvolutionalnetworksforlarge-scaleimagerecognition."arxivpreprintarxiv:1409.1556(2014))网络(该vgg-16网络的训练目标为区分不同的字体风格),将g(x0j,xib1,xib2,…,xibn)与xij分别输入到该网络中,即可得到各自的逐级卷积特征,记为φ(g(x0j,xib1,xib2,…,xibn))和φ(xij),则此处的高级特征误差可由以下公式来计算:
在本专利中,我们选取φ1-2,φ2-2,φ3-3,φ4-3,φ5-3五个卷积特征来计算高级特征误差;
(3)训练中引入“生成对抗网络”的的训练方法(gulrajani,i.,ahmed,f.,arjovsky,m.,dumoulin,v.,courville,a.c.:improvedtrainingofwassersteinganspp.5769–5779(2017)),即在训练所要得到的字符生成模型之外(g),同时训练另外一个以卷积神经网络为基础的一个判别式模型(d),该模型的基本功能是用于判断输入模型的数据为真实数据还是生成数据.如果输入的数据是真实数据,则输出为1;如果输入的数据为生成数据,则输出为零.当该判别式模型无法有效地区分真实数据和生成数据时,我们可以认为生成数据已经具有很高的质量,已经无法与真实数据相区分了;
生成对抗网络的训练方法所对应的误差称为对抗损失.本专利中所提出的字符生成模型称为生成器g.g的对抗损失为:
对于判别器d,对抗损失为:
步骤6、每一次迭代过程使用交替优化的策略,在每一个迭代过程中,首先根据最小化
2.上述方案中,所述训练中所使用的手写体数据库为casia-hwdb1.1-offline和casia-hwdb2.1-offline(offlineversion,liu,c.l.,yin,f.,wang,d.h.,wang,q.f.:casiaonlineandofflinechinesehand-writingdatabasespp.37–41(2011))两个数据集.两个数据集中,挑选若干书写者(大于50种)所写字符中所有收录在gb2312一级字符集中的所有简体字符数据作为训练数据,用以训练该字符生成模型。印刷体数据库为若干种挑选出来的常用中文印刷体(多余50种),其中所有收录于gb2312字符集中的所有简体汉字作为训练数据.
由于上述技术方案的运用,本发明与现有技术相比具有下列优点:
本发明基于少量样本风格的风格字符生成方法,其实现了根据一种风格的少量字符(甚至一个字符)生成相应风格的任意字符。该方法能够以若干个甚至一个带有风格的字符作为风格参考样板,生成带有同种书写/印刷风格的任意字符,生成字符的内容则由输入的带有标准风格的内容原型来决定。
附图说明
附图1为本发明基于少量样本风格的手写字符生成方法原理示意图;
附图2为附图1中标识出内容原型编码器的原理示意图;
附图3为附图1中标识出风格参考编码器的原理示意图;
附图4为附图1中标识出解码器的原理示意图;
附图5为由输入的一个带有某种印刷风格的字符所生成的其它带有同种印刷风格的汉字;
附图6为附图5的对应真实的印刷体汉字.数据库中无法找到的对应的带有相应风格的印刷体汉字则由标准字体汉字来代替作为占位使用;
附图7为由输入的一个带有某种手写风格的字符所生成的其它带有同种手写风格的汉字;
附图8为附图7的对应真实的手写体汉字.数据库中无法找到的对应的带有相应风格的手写体汉字则由标准字体汉字来代替作为占位使用;
附图9为由输入的四个带有某种印刷风格的字符所生成的其它带有同种印刷风格的汉字;
附图10为附图9的对应真实的印刷体汉字.数据库中无法找到的对应的带有相应风格的印刷体汉字则由标准字体汉字来代替作为占位使用;
附图11为由输入的四个带有某种手写风格的字符所生成的其它带有同种手写风格的汉字;
附图12为附图11的对应真实的手写体汉字.数据库中无法找到的对应的带有相应风格的手写体汉字则由标准字体汉字来代替作为占位使用;
附图13为由输入的八个带有某种印刷风格的字符所生成的其它带有同种印刷风格的汉字;
附图14为附图13的对应真实的印刷体汉字.数据库中无法找到的对应的带有相应风格的印刷体汉字则由标准字体汉字来代替作为占位使用;
附图15为由输入的八个带有某种手写风格的字符所生成的其它带有同种手写风格的汉字;
附图16为附图15的对应真实的手写体汉字.数据库中无法找到的对应的带有相应风格的手写体汉字则由标准字体汉字来代替作为占位使用;
附图17为由输入的16个带有某种印刷风格的字符所生成的其它带有同种印刷风格的汉字;
附图18为附图17的对应真实的印刷体汉字.数据库中无法找到的对应的带有相应风格的印刷体汉字则由标准字体汉字来代替作为占位使用;
附图19为由输入的16个带有某种手写风格的字符所生成的其它带有同种手写风格的汉字;
附图20为附图19的对应真实的手写体汉字.数据库中无法找到的对应的带有相应风格的手写体汉字则由标准字体汉字来代替作为占位使用;
附图21为由输入的32个带有某种印刷风格的字符所生成的其它带有同种印刷风格的汉字;
附图22为附图21的对应真实的印刷体汉字.数据库中无法找到的对应的带有相应风格的印刷体汉字则由标准字体汉字来代替作为占位使用;
附图23为由输入的32个带有某种手写风格的字符所生成的其它带有同种手写风格的汉字;
附图24为附图23的对应真实的手写体汉字.数据库中无法找到的对应的带有相应风格的手写体汉字则由标准字体汉字来代替作为占位使用。
具体实施方式
下面结合实施例对本发明作进一步描述:
实施例:一种基于少量样本风格的字符生成方法,其特征在于:以若干种(多余50种)手写体字符为手写体风格迁移目标,或者若干种常见印刷体(多余50种)字符为印刷体风格迁移目标,以及一种标准字体的字符作为风格迁移源,使用基于深度生成对抗网络的图像翻译模型,训练出一个字符风格迁移的字符生成模型;
所述字符生成模型由内容原型编码器contentprototypeencoder,encp,风格参考编码器stylereferenceencoder,encr和解码器decoder,dec所组成,因为两个编码器从结构上来说是并列的关系,因此,网络的总层数是12层;
所述内容原型编码器contentprototypeencoder,encp输入数据为一个带有标准风格的字符(x0j),表示成长宽为64*64,值域在[0,255]之间的的灰度图片,输出为经过若干个残差单元(residualblocks)或者直接连接的各级卷积特征;该内容原型编码器由连续的卷积(conv)间隔步幅值为2的卷积运算,用于提取所输入的标准字符(x0j)从低级(像素级)到高级(隐空间)的各级特征,每级特征较之其上一级特征,特征长宽减半,其所得到的标准字符的最高级特征,长宽均为1;
所述风格参考编码器stylereferenceencoder,encr,其输入为带有某一种风格(风格用i来表示)n个不同字符({xib1,xib2,…,xibn}),同样表示成长宽为64*64,值域在[0,255]之间的的灰度图片;输出为对各级卷积特征对n进行平均运算后,再经过若干个残差单元(residualblocks)或者直接连接的各级卷积特征;
该风格参考编码器基本结构与encp相似,但为了处理一次性输入的多个(n个)带有某种书写风格字符(假设为第i个风格,{xib1,xib2,…,xibn})的平均特征,对应这些n个字符的n个卷积特征首先需要对n进行平均运算,从而得出这n个字符({xib1,xib2,…,xibn})的1个各级平均卷积特征,此后再放入残差单元(residualblocks)或者直接连接后送入dec;
所述内容原型编码器encp、风格参考编码器encr对各自输入数据进行特征提取,并将提取过后的信息串联后输入解码器网络decoder,dec;dec解码器网络对从内容原型编码器encp和风格参考编码器encr的输入来的各级卷积特征进行串联(concat)后进行恢复及重建,输出带有某一种的风格的生成字符(g(x0j,xib1,xib2,…,xibn)),亦表示为同样表示成长宽为64*64,值域在[0,255]之间的灰度图片;
该生成字符的内容来源于输入到encp的标准字符(x0j),风格来源于输入到encr的n个带有第i个风格的字符(({xib1,xib2,…,xibn});
该解码器由连续的卷积间隔步幅值为2的反卷积(deconv)运算所组成,即后一级特征的长宽是前一级特征的两倍,最终生成与输入的无风格标准字符长宽一致的具有特定风格的字符;
包括以下步骤:
步骤一、训练开始之前,需要对字符生成模型的参数进行随机初始化,从而给定训练的开始状态;
步骤二、我们使用随机优化(stochasticoptimization)的训练策略来对该字符生成模型进行训练,训练目标即为最小化训练误差
步骤三、当
步骤四、获取某个书写风格的任意若干个字符(假设为n个,一般n<=32,{xib1,xib2,…,xibn}),并将此n个字依次输入到训练完成的字符生成模型的风格参考编码器(encr),得出n份各级卷积特征,对应n个不同的同风格字符;
步骤五,对由encr计算得出的,对应于n个输入的带有同一种书写风格的字符的n份各级卷积特征进行平均计算,得出n份各级卷积特征的平均各级卷积体征(一份);
步骤六、对步骤五所得出的各级卷积特征进行相应的残差单元操作或直接连接操作,保存下各级特征的计算结果,作为此后输入解码器的风格参考特征;
步骤七、向内容原型编码器(encp)输入欲生成字符对应的标准字体字符(x0j),计算出各级卷积特征后,进行相应的残差单元或者直接连接操作;
步骤八、将两个编码器所得到的各级卷积特征,分别串联到解码器的各级输出特征之上,从而生成欲产生的带有特定风格的任意字符,g(x0j,xib1,xib2,…,xibn)。
上述技术方案中进一步改进的技术方案如下:
1.上述方案中,所述步骤二具体包括以下步骤:
步骤1、我们从训练数据集中随机选取一批训练数据(一批数据的大小一般设置为16个数据),其中一个数据由一对字符组成,包括一个标准字符(x0j)和与之相同的带有某一个特定风格的字符的真实样本(xij);
步骤2、此后,根据所选取的带有某一个特定风格的风格字符(xij),随机从同一个训练数据集中选取另外n个带有同样风格的不同的字符({xib1,xib2,…,xibn});
步骤3、将x0j输入encp,{xib1,xib2,…,xibn}输入encr,从而获取两个编码器各级卷积特征;
步骤4、将上一步获得的两个编码器的各级卷积特征根据图示连接关系送入解码器,从而生成希望生成的带有某一个特定书写风格的字符样(g(x0j,xib1,xib2,…,xibn));
步骤5、将上一步所生成的字符样本计算以下两个训练误差:
(1)生成样本g(x0j,xib1,xib2,…,xibn)与数据库中真实样本(xij)的1-范数误差,即:
(2)除了以上像素层面上的第几特征的1-范数误差,本专利在训练过程中也考虑到了高级特征误差,我们使用一个预先训练好的vgg-16(simonyan,karen,andandrewzisserman."verydeepconvolutionalnetworksforlarge-scaleimagerecognition."arxivpreprintarxiv:1409.1556(2014))网络(该vgg-16网络的训练目标为区分不同的字体风格),将g(x0j,xib1,xib2,…,xibn)与xij分别输入到该网络中,即可得到各自的逐级卷积特征,记为φ(g(x0j,xib1,xib2,…,xibn))和φ(xij),则此处的高级特征误差可由以下公式来计算:
在本专利中,我们选取φ1-2,φ2-2,φ3-3,φ4-3,φ5-3五个卷积特征来计算高级特征误差;
(3)训练中引入“生成对抗网络”的的训练方法(gulrajani,i.,ahmed,f.,arjovsky,m.,dumoulin,v.,courville,a.c.:improvedtrainingofwassersteinganspp.5769–5779(2017)),即在训练所要得到的字符生成模型之外(g),同时训练另外一个以卷积神经网络为基础的一个判别式模型(d),该模型的基本功能是用于判断输入模型的数据为真实数据还是生成数据.如果输入的数据是真实数据,则输出为1;如果输入的数据为生成数据,则输出为零.当该判别式模型无法有效地区分真实数据和生成数据时,我们可以认为生成数据已经具有很高的质量,已经无法与真实数据相区分了;
生成对抗网络的训练方法所对应的误差称为对抗损失.本专利中所提出的字符生成模型称为生成器g,g的对抗损失为:
对于判别器d,对抗损失为:
步骤6、每一次迭代过程使用交替优化的策略,在每一个迭代过程中,首先根据最小化
所述训练中所使用的手写体数据库为casia-hwdb1.1-offline和casia-hwdb2.1-offline(offlineversion,liu,c.l.,yin,f.,wang,d.h.,wang,q.f.:casiaonlineandofflinechinesehand-writingdatabasespp.37–41(2011))两个数据集.两个数据集中,挑选若干书写者(大于50种)所写字符中所有收录在gb2312一级字符集中的所有简体字符数据作为训练数据,用以训练该字符生成模型。印刷体数据库为若干种挑选出来的常用中文印刷体(多余50种),其中所有收录于gb2312字符集中的所有简体汉字作为训练数据.
为了克服一般深度网络(12层)在训练过程中所面临的梯度消失的问题,将两个编码器的各级输出特征连接到对应层的解码器的特征之上.连接的形式有直接连接(short-cut)和经过若干残差单元(resudialblocks)后再连接两种。
内容原型编码器(encp)第四层及其之下各级特征通过直接连接的方式与对应的解码器的特征相串联(concat);第四层之上特征通过若干个残差单元后,也与对应的解码器的各级特征相串联;风格参考编码器(encr)的输入数据为n个同风格的不同字符,因此,该编码器的各级输出的各级特征均有n份,每一份对应一个同风格的不同字符.因此,再将该编码器输出特征与标准字体编码器的输出特征整合以及输入到解码器之前,需要对该编码器第四层及其之下特征进行平均计算(avg),从而削去因为不同的字符所带来的特征差异,只保留与某一种手写体风格有关的特征.将平均后的第四层特征经过若干个残差单元后与解码器的对应层特征相串联,第四层以上的平均特征直接串联到解码器的对应层特征之上。
本发明基于少量样本风格的风格字符生成方法,其实现了根据一种风格的少量字符(甚至一个字符)生成相应风格的任意字符。该方法能够以若干个甚至一个带有风格的字符作为风格参考样板,生成带有同种书写/印刷风格的任意字符,生成字符的内容则由输入的带有标准风格的内容原型来决定;
附图5~附图24给出一些根据较少样本(样本数为1,4,8,16,32)的带有某种风格(印刷风格或者手写风格)的标定样本,使用本发明中所提出的字符生成模型所产生的带有同种风格的其它字符.
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!