一种基于用户行为的网页静态资源预加载方法与流程
本发明是关于web技术领域,特别涉及一种基于用户行为的网页静态资源预加载方法。
背景技术:
在web技术不断推陈出、商业竞争日益激烈的今天,访问网站时还是存在静态资源加载耗时的问题。该问题不解决带来的危害是访问页面时,页面内容无法快速展现,带来不好的用户体验。网页的加载速度对用户体验的提升,对用户留存率的提高具有至关重要的作用。
对于图片、js脚本文件等页面静态资源,主要用于页面样式的展现和业务逻辑的运行。当浏览器访问某个网站url,经过dns解析后,将会从该网站的服务器上下载这些资源。如果资源的下载时间过长,将会直接导致网页加载时间被延长,带来极其不佳的用户体验。研究表明:用户最满意的打开网页时间是2-5秒,如果等待超过10秒,99%的用户会关闭这个网页。所以如何提高页面加载速度,对于前端开发来说是一个重要的话题
当前实际应用较广的方案主要如下:
方法一:合并资源,减少网络请求。一个页面需要发起几十个网络请求来获取脚本、图片等资源,每个请求需要进行dns寻址、建立链接、处理请求、返回数据等操作,这些开销大大延长了资源加载的时间。所以可以通过将多个文件合并成一个文件的方式,来减少请求数。
此方法的优点是:1)减少了网络请求带来的dns寻址、客户端与服务端握手等网络请求自身消耗的时间;2)由于浏览器存在网络请求并发上限,超过上限的请求必须等待,无法与其他请求并发,合并资源后,可以尽可能地减少请求被延迟执行的情况。
此方法的缺点是:1)使得单个资源过大,无法做到渐进式页面渲染;2)存在资源浪费问题,打包合并后的资源内,包含了很多对当前页面无用的内容。
方法二:页面懒加载。页面只加载屏幕可视范围内的资源,当页面滚动时,再加载后续内容需要的静态资源。
此方法的优点是:1)减少了首屏加载时间;2)资源按需获取,不存在资源浪费问题。
此方法的缺点是:页面交互的流畅度降低,由于资源的加载是由用户的操作触发,而资源加载时间一般都会长于用户操作的时间,所以会让用户感觉到明显的卡顿。
技术实现要素:
本发明的主要目的在于克服现有技术中的不足,提供一种根据请求预判模型来预测下一请求对象,前端主动预加载的静态资源加载优化方案。为解决上述技术问题,本发明的解决方案是:
提供一种基于用户行为的网页静态资源预加载方法,具体包括下述步骤:
步骤(1):建立初始预判模型;
扫描用户请求日志文件,通过分析用户实际的资源请求顺序(该顺序是用户操作和兴趣点的侧面反映),对每个页面构建资源请求依赖树(即静态资源下载顺序与依赖树);
所述资源请求依赖树,能体现对应页面静态资源的下载顺序;该网站所有页面的资源请求依赖树,即为预判模型;
步骤(2):服务端开启静态资源预判;
当服务端接收到来自客户端的静态资源请求,分析出当前请求的历史请求路径(即访问页面时,是沿着什么请求顺序到达当前请求的);
根据历史请求路径和步骤(1)产生的预判模型,预判出客户端下一个静态资源请求对象;在当前请求对象返回时,将提前将该预判结果一起返回给客户端;
步骤(3):完善预判模型;
客户端将服务端返回的预判静态资源请求对象与实际下一个请求的对象进行对比,将预判成功或者失败的信息返回给服务端;
服务端根据反馈信息,自动调整预判模型。
在本发明中,所述步骤(1)中,构建资源请求依赖树具体包括下述步骤:
步骤a1):将页面url设为树的根节点;
步骤b1):将页面初始加载的资源作为根节点的子节点,每个节点包含资源名称和资源被请求总次数信息;
步骤c1):依次遍历步骤b1)中新产生的子节点,分别找到在这些节点之后请求的资源,并将这些资源对象作为对应节点的子节点;每个新产生的节点包含资源名称和资源请求路径对应的请求次数;
步骤d1):递归遍历新产生的子节点,直到资源请求依赖树建立完成。
在本发明中,所述步骤(2)中,根据预判模型和历史请求路径,预判出客户端下一个静态资源的请求对象,具体方法如下:
在预判模型中找出当前请求对应的节点:
若当前请求对应的节点存在多个子节点(表示在当前请求之后,可能有多种请求情况),则通过历史请求路径与各个子节点的资源请求路径对应的请求次数进行核算,获取对应当前历史请求路径次数最多的一个子节点,预测该子节点对应资源为下一个请求对象;
若当前请求对应的节点只存在一个子节点,则预测该子节点对应资源为下一个请求对象。
在本发明中,所述步骤(3)中,完善预判模型,具体包括下述步骤:
步骤a3):客户端根据服务端返回的预测资源信息,在当前线程空闲的情况下,预先加载该资源;
步骤b3):当下一个请求发生时,客户端将请求的资源与预测资源信息进行比对;
若预测成功,则无需再次请求,并请预测成功的结果信息反馈给服务端;
若预测失败,则重新请求,并请预测失败的结果信息反馈给服务端;
步骤c3):服务端收到客户端的反馈信息;
若预测成功,则将该被预测的子节点的资源请求路径对应的请求次数加1;
若预测失败,则将该被预测的子节点的资源请求路径对应的请求次数减1。
提供一种存储设备,其中存储有多条指令,所述指令适用于由处理器加载并执行:
步骤(1):建立初始预判模型;
扫描用户请求日志文件,通过分析用户实际的资源请求顺序(该顺序是用户操作和兴趣点的侧面反映),对每个页面构建资源请求依赖树(即静态资源下载顺序与依赖树);
所述资源请求依赖树,能体现对应页面静态资源的下载顺序;该网站所有页面的资源请求依赖树,即为预判模型;
步骤(2):服务端开启静态资源预判;
当服务端接收到来自客户端的静态资源请求,分析出当前请求的历史请求路径(即访问页面时,是沿着什么请求顺序到达当前请求的);
根据历史请求路径和步骤(1)产生的预判模型,预判出客户端下一个静态资源请求对象;在当前请求对象返回时,将提前将该预判结果一起返回给客户端;
步骤(3):完善预判模型;
客户端将服务端返回的预判静态资源请求对象与实际下一个请求的对象进行对比,将预判成功或者失败的信息返回给服务端;
服务端根据反馈信息,自动调整预判模型。
提供一种移动终端,包括处理器,适于实现各指令;以及存储设备,适于存储多条指令,所述指令适用于由处理器加载并执行:
步骤(1):建立初始预判模型;
扫描用户请求日志文件,通过分析用户实际的资源请求顺序(该顺序是用户操作和兴趣点的侧面反映),对每个页面构建资源请求依赖树(即静态资源下载顺序与依赖树);
所述资源请求依赖树,能体现对应页面静态资源的下载顺序;该网站所有页面的资源请求依赖树,即为预判模型;
步骤(2):服务端开启静态资源预判;
当服务端接收到来自客户端的静态资源请求,分析出当前请求的历史请求路径(即访问页面时,是沿着什么请求顺序到达当前请求的);
根据历史请求路径和步骤(1)产生的预判模型,预判出客户端下一个静态资源请求对象;在当前请求对象返回时,将提前将该预判结果一起返回给客户端;
步骤(3):完善预判模型;
客户端将服务端返回的预判静态资源请求对象与实际下一个请求的对象进行对比,将预判成功或者失败的信息返回给服务端;
服务端根据反馈信息,自动调整预判模型。
本发明的原理是:自动分析用户操作流程数据,总结出资源下载先后顺序和彼此间依赖的规律,使得在用户请求某资源后,预判出下一个请求的资源对象并提前告知客户端,客户端根据该预判信息,主动提前请求下一个资源。该发明的关键点是请求预判。
与现有技术相比,本发明的有益效果是:
1、本发明是一种基于懒加载,但弥补了懒加载会出现顿挫感的方案。
2、本发明存在自学习、自优化的能力,能够应对软件持续更新、页面内容改变使得请求顺序变化的情况。
3、本发明对于前端开发影响小,只需一次编写预加载和反馈机制,对于单个请求的代码编写没有额外影响。
附图说明
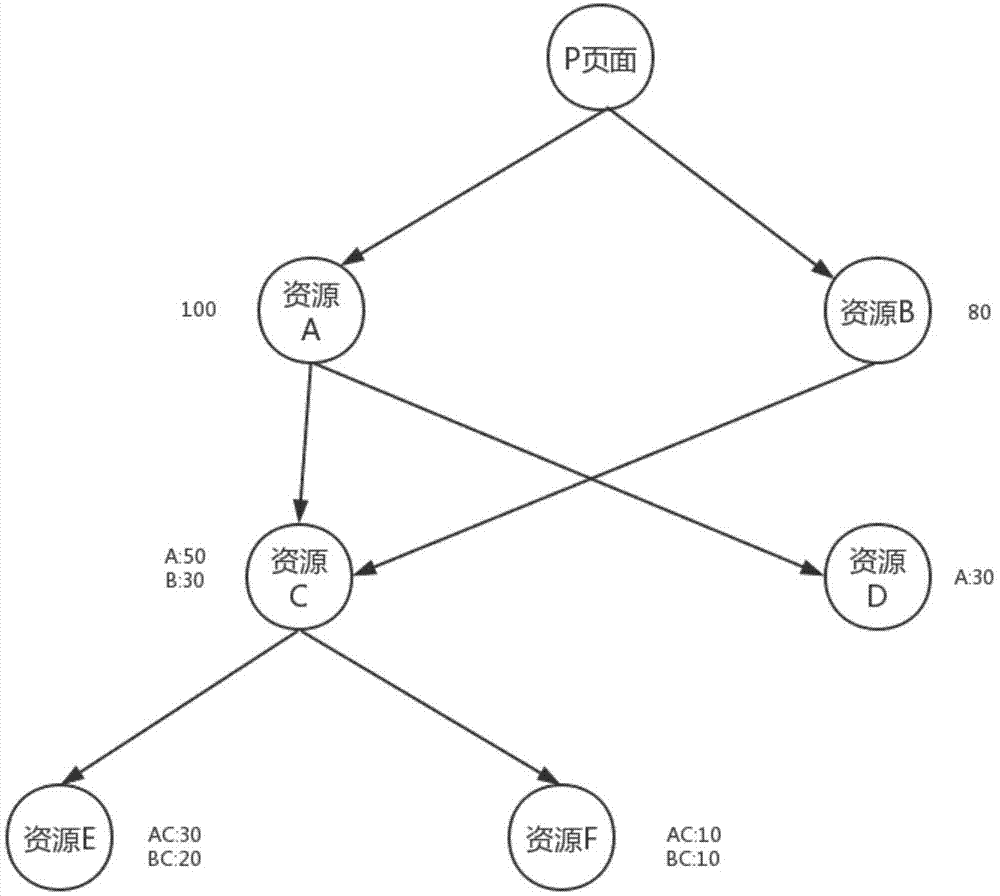
图1为本发明中的资源请求依赖树示意图。
具体实施方式
首先需要说明的是,本发明是计算机技术的一种应用。在本发明的实现过程中,会涉及到多个软件功能模块的应用。申请人认为,如在仔细阅读申请文件、准确理解本发明的实现原理和发明目的以后,在结合现有公知技术的情况下,本领域技术人员完全可以运用其掌握的软件编程技能实现本发明。凡本发明申请文件提及的均属此范畴,申请人不再一一列举。
下面结合附图与具体实施方式对本发明作进一步详细描述:
一种基于用户行为的网页静态资源预加载方法,解决的是当前web静态资源加载速度慢,导致用户体验差的问题。该方法包括建立初始预判模型、服务端开启静态资源预判、完善预判模型三个步骤,具体为:
步骤(1):建立初始预判模型:
扫描用户请求日志文件,通过分析用户实际的资源请求顺序(该顺序是用户操作和兴趣点的侧面反映),对每个页面构建资源请求依赖树。如图1所示的资源请求依赖树,即静态资源下载顺序与依赖树,能体现对应页面静态资源的下载顺序,依据此树可以为下一步的预判做重要的参考依据。该网站所有页面的资源请求依赖树,即为预判模型。
构建资源请求依赖树具体包括下述步骤:
步骤a1):将页面url设为树的根节点。
步骤b1):将页面初始加载的资源作为根节点的子节点,每个节点包含资源名称和资源被请求总次数信息。
步骤c1):依次遍历步骤b1)中新产生的子节点,分别找到在这些节点之后请求的资源,并将这些资源对象作为对应节点的子节点;每个新产生的节点包含资源名称和资源请求路径对应的请求次数。以图1中的资源f为例,节点的“ac:10”信息表示从请求路径a->c->f的请求次数是10次。
步骤d1):递归遍历新产生的子节点,直到资源请求依赖树建立完成。
步骤(2):服务端开启静态资源预判:
当服务端接收到来自客户端的静态资源请求,分析出当前请求的历史请求路径,即访问页面时,是沿着什么请求顺序到达当前请求的。
根据步骤(1)产生的预判模型和历史请求路径,预判出客户端下一个静态资源请求对象,具体为:
步骤a2):在预判模型中找出当前请求对应的节点:
若当前请求对应的节点存在多个子节点(表示在当前请求之后,可能有多种请求情况),则通过历史请求路径与各个子节点的资源请求路径对应的请求次数进行核算,获取对应当前历史请求路径次数最多的一个子节点,预测该子节点对应资源为下一个请求对象。
若只存在一个子节点,则预测该子节点对应资源为下一个请求对象。
步骤b2):在当前请求对象返回时,将提前将该预判结果一起返回给客户端。
步骤(3):完善预判模型:
客户端将服务端返回的预判静态资源请求对象与实际下一个请求的对象进行对比,将预判成功或者失败的信息返回给服务端。服务端根据反馈信息,自动调整预判模型,以使模型的准确率不断提高。具体为:
步骤a3):客户端根据服务端返回的预测资源信息,在当前线程空闲的情况下,预先加载该资源。
步骤b3):当下一个请求真实发生时,客户端将请求的资源与预测资源信息进行比对:
若预测成功,则无需再次请求,并请预测成功的结果信息反馈给服务端;
若预测失败,则重新请求,并请预测失败的结果信息反馈给服务端。
步骤c3):服务端收到客户端的反馈信息:
若预测成功,则将该被预测的子节点的资源请求路径对应的请求次数加1;
若预测失败,则将该被预测的子节点的资源请求路径对应的请求次数减1。
最后,需要注意的是,以上列举的仅是本发明的具体实施例。显然,本发明不限于以上实施例,还可以有很多变形。本领域的普通技术人员能从本发明公开的内容中直接导出或联想到的所有变形,均应认为是本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!