一种基于目标检测的全种类车牌识别方法与流程
本发明属于图像处理与深度学习领域,具体提供一种基于目标检测的全种类车牌识别方法,主要用于复杂场景下的全种类车牌识别。
背景技术:
车牌识别技术是智能交通系统中的一项非常重要的技术,传统车牌识别技术一般包含三个部分:车牌定位,字符分割,字符识别;车牌识别算法虽然已经被广泛应用到停车场、高速公路、小区出入口,但是依然还有很多等待解决的问题比如公路监控等复杂场景下的整体识别率低,需要针对新类型车牌修改算法等。
随着2012年alexnet的提出,深度学习技术在图像识别、目标检测、语义分割等任务中大放异彩;深度学习的成功有两个重要的因素,第一是模型大量参数的强大拟合能力,第二是大量训练数据,二者相辅相成造就了深度学习对传统方法的全面超越。对于车牌识别领域来说,引入深度学习是大的趋势,但是目前提出的方法大部分都有着共同的缺点:没有完全抛弃传统方法中造成鲁棒性差的图像处理步骤;如申请号为:cn201710188171、发明名称为一种基于全卷积网络的车牌定位方法及装置的发明专利中的形态学处理、轮廓提取,又如申请号为cn201710432232、发明名称为高效准确的车牌识别方法的发明专利中的二值化、投影操作;此外,这些方法都是只考虑固定几种甚至只有一种类型车牌的识别,一旦要识别新类型车牌,便不再适用。
技术实现要素:
本发明的目的在于提供一种基于目标检测的全种类车牌识别方法,以深度学习技术中的目标检测算法为切入点,着手解决车牌识别算法的难点问题。
为实现上述目的,本发明采用的技术方案为:
一种基于目标检测的全种类车牌识别方法,其特征在于,包括以下步骤:
步骤1、训练denet车牌检测器,并使用训练出的denet车牌检测器检测出图像中车牌的包围框和类型,得到车牌类型为t类型;
步骤2、训练denet字符检测器,并使用训练好的denet车牌字符检测器检测出车牌字符的包围框和类型,得到n个字符的包围框和类别,将检测结果记为集合:
{di=(boxi,clsi)}、i∈[1,n]、其中、boxi表示字符检测结果中第i个字符的包围框、clsi表示字符检测结果中第i个字符的类别;
步骤3、字符排序
对于字符检测结果{di}、i∈[1,n],为每个字符添加标记k表示其在车牌号中的序号,得到:
列举检测出的字符所有可能的n!种排序组合:
计算每一个组合
1)对于组合
2)计算t类型车牌的字符连接向量和当前组合的字符连接向量每一维向量之间夹角,得到夹角集合
3)根据
遍历所有组合与t类型车牌的字符连接向量的余弦相似度,得到相似度最大值对应的组合作为最优组合,得到字符排序。
进一步的,所述步骤1中denet车牌检测器训练过程为:按照denet训练数据的格式制作车牌的标注数据,标注内容包括:车牌的包围框和车牌类型,
根据需要检测的车牌类别设置网络参数,
使用theano深度学习框架训练出denet车牌检测器。
进一步的,所述步骤2中denet字符检测器训练过程为:按照denet训练数据的格式制作车牌字符的标注数据,标注内容包括:字符的包围框和字符类别,
根据需要检测的字符类别设置网络参数,
使用theano深度学习框架训练出denet字符检测器。
本发明的有益效果在于:
本发明提供一种基于目标检测的全种类车牌识别方法,以深度学习技术中的目标检测算法为切入点,将车牌识别技术中的子任务统一到了目标检测的框架下,首次使用基于深度学习的字符检测并结合字符排序完成全种类车牌字符序列识别;由于完全使用深度学习技术,只要有足够的训练数据,本发明能够有非常好的整体识别率;与已有基于传统方法和基于深度学习的车牌识别方法相比,本发明具有极强的普适性,该方法考虑了全种类车牌的检测与识别,对于任意类型的车牌,不需要修改算法,只要准备相应的训练数据,便可使用本发明完成车牌识别。
附图说明
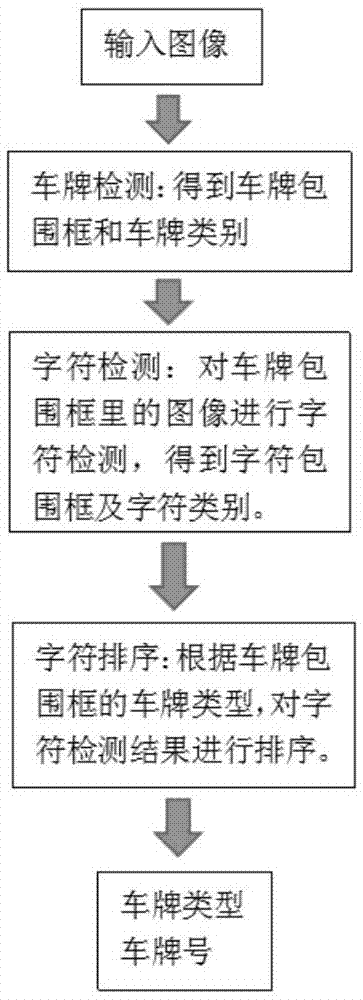
图1为本发明基于目标检测的全种类车牌识别方法流程示意图。
图2为本发明实施例中待识别车牌图像。
图3为本发明实施例中车牌检测后结果。
图4为本发明实施例中字符检车后结果。
图5为本发明实施例中t类型车牌的字符连接向量构成原理图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细说明。
本发明提供一种基于目标检测的全种类车牌识别方法,该方法将车牌识别技术中的子任务统一到了目标检测的框架下,在车牌检测和字符检测两个步骤都用到了目标检测算法,只要目标检测算法可以输出目标的包围框和类别,都可以应用到本方法中,例如经典的faster-rcnn、ssd、yolo等基于深度神经网络的目标检测算法。
本发明将车牌的检测识别拆分为3个步骤:车牌检测、字符检测和字符排序,如图1所示:
车牌检测:定位出图像中所有车牌的包围框,包围框是一个由4个点组成的四边形,并同时输出包围框对应的车牌类型;
字符检测:将包围框中的图像透视变换为一个正矩形形状的待识别车牌图像,然后对待识别车牌图像运行字符检测算法,定位出待识别车牌图像中所有车牌字符的包围框,并同时输出包围框对应的字符类别;
字符排序:计算字符检测结果中每个包围框的中心点坐标,接下来根据车牌类型,找出与车牌类型对应的标准字符连接向量相似度最高的字符排序,进而得出最终的车牌字符序列;
此方法能够提高复杂场景下的整体识别率,并且适用于任何类型的车牌。
具体步骤如下:
步骤1、训练denet车牌检测器:
按照denet训练数据的格式制作车牌的标注数据,标注内容包括:车牌的包围框和车牌类型,
根据需要检测的车牌类别等设置网络参数,
使用theano深度学习框架训练出denet车牌检测器;
使用训练出的denet车牌检测器可以检测出图像中车牌的包围框和类型,如对图2进行车牌检测,将包围框中的图像取出可以得到车牌检测图像,记检测出来的车牌类型为t;将包围框中的图像截取出来得到图3;
步骤2、训练denet字符检测器
按照denet训练数据的格式制作车牌字符的标注数据,标注内容包括:字符的包围框和字符类别,
根据需要检测的字符类别等设置网络参数,
使用theano深度学习框架训练出denet字符检测器;
使用训练好的denet车牌字符检测器可以检测出车牌字符的包围框和类型,要求输入图像的车牌的倾角不得大于30度,通过字符检测可得到n个字符的包围框和类别,将检测结果记为集合{di=(boxi,clsi)}、i∈[1,n]、其中、boxi表示检测结果中第i个字符的边框、clsi表示检测结果中第i个字符的类别;但是直接检测出的字符是无序的,无法直接得到检测出的第i个字符在车牌字符序列中的位置,所以还需要对检测出的字符进行排序;如图4所示为对图3进行字符检测的结果;
步骤3、字符排序
字符排序是实现任意类型车牌识别的关键一步,本发明将使用检测出的字符的相对位置关系求解出每个字符在车牌字符序列中的位置;纵观国内外现有车牌,一个车牌类型的构成要素是车牌底板尺寸、颜色和车牌字符字体、颜色、尺寸、空间位置,在字符排序步骤中只需要使用到车牌的字符空间位置信息;
对于任一类型(记为t)的车牌如图5所示,用c1~cn表示车牌号的n个字符,为了描述t类型车牌的字符相对空间位置关系,记
对于字符检测结果{di}、i∈[1,n],为每个字符添加参数k表示其在车牌号中的序号
为了确定字符检测结果中的每个字符的序号,列举检测出的字符所有可能的n!种组合:
按照如下流程计算每种组合与t类型车牌的字符连接向量的余弦相似度:
1)对于组合
2)计算t类型车牌的字符连接向量和当前组合的字符连接向量每一维向量之间夹角,得到夹角集合
3)根据
计算完每种组合与t类型车牌的字符连接向量的余弦相似度,选取相似度最大的组合作为最优组合并记为
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
- 还没有人留言评论。精彩留言会获得点赞!