一种图像非局部立体匹配方法与流程
本发明属于图像处理技术领域,涉及一种图像非局部立体匹配方法。
背景技术:
立体匹配是计算机视觉中一个重要热点和难点,它借助立体成像原理,寻找多目图像中对应点的位置,把得到的二维图像恢复到三维场景,匹配正确就可以得到精确的深度信息。该技术可以被广泛应用于机器人、人工智能、医学、航天航空、工业检测等领域。近年来,由于应用背景的多样化,对匹配精度的要求也不断提高。
scharstein对已有的立体匹配算法进行了全面的综述,包括四个步骤:匹配代价计算、代价聚集、视差计算和视差精化。立体匹配算法在总体上分为局部匹配算法和全局匹配算法。
局部立体匹配算法,通常结合窗口内相邻像素的信息进行单像素的相似性计算,由于该类算法信息量少,结构简单,所以运行效率高,但对噪声敏感,在弱纹理、遮挡、视差不连续区域的误匹配率较高。
全局立体匹配算法主要通过全局的优化理论方法估计视差,建立全局能量函数,再通过最小化全局能量函数来得到最优视差值,设计合理的数据项和平滑项是全局匹配算法的基本问题。常用的全局算法有置信度传播(bp)、动态规划(dp)、图割(gc)等。一般情况下,全局算法得到的匹配结果准确度比局部算法高,但计算量大、耗时长,不适合实时应用。
在匹配代价计算阶段,常用的代价函数有灰度差绝对值之和(sad)、灰度差平方和(ssd)、梯度、颜色和census变换等。其中,梯度信息能够很好地突出图像的边缘,但对噪声和光照变化很敏感。在代价聚集阶段,大多数的聚集方法通过定义一个局部窗口,通过求解窗口中像素的平均代价值,局部匹配方法未充分考虑到窗口外其他像素点的权重支持,其难点在于窗口的选择,而全局匹配方法的聚集过程基于整个图像,实时性较差。
在视差精化阶段,通常采用左右一致性检测,检测出遮挡点后再对遮挡点进行处理,通过将稳定点的视差值传播到不稳定点,以此来更新代价值得到最后的视差图。
技术实现要素:
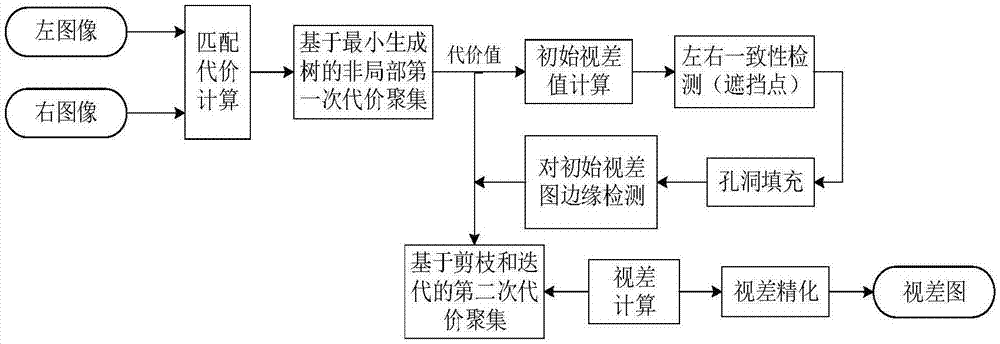
为解决上述技术问题,本发明提出一种图像非局部立体匹配方法,可以提高图像在双目立体匹配方法中匹配的准确率和速率,包括以下步骤:
1)结合颜色和梯度信息作为相似性测度函数构建代价计算函数;
2)分别对左右目图像构建最小生成树,并对代价函数值进行代价聚集;
3)采用wta策略得到初始视差图,通过左右一致性检测得到不稳定点,并进行孔洞填充,然后对视差图进行边缘检测;
4)根据步骤3得到的边缘图像,结合剪枝的思想对代价函数值进行进一步的聚集;
5)通过视差求精得到最终的稠密视差图。
进一步地,步骤(1)具体包括:
①采用rgb三通道信息代替单一的灰度信息,通过三通道计算出颜色信息,表达式如下:
其中,
②采用二维离散函数求导的方式求得图像的梯度,表达式如下:
其中
③通过上述计算来构建初始匹配代价函数如下:
c(p,d)=w1cad(p,d)+w2cgrad(p,d)(3),
其中,w1、w2分别为颜色信息和梯度信息的权值,w1+w2=1。
优选地,在无纹理区域,构建初始匹配代价函数的表达式为:
c'(p,d)=ln(1+exp(c(p,d)))(4),
其中,c'(p,d)是改进后的匹配代价值。
进一步地,步骤(2)具体包括如下步骤:
采用kruskal方法构建最小生成树,连接相邻顶点s和r的边权值为:
we=w(s,r)=|i(s)-i(r)|
其中,i为rgb三通道中其中最大的像素值;
代价聚集值计算:在最小生成树中,根据相邻像素点的远近来定义像素之间的相关性,顶点p和q之间的相似性为:
非局部区域代价聚集值如下:
其中,s1(p,q)是初始相似性,d(p,q)表示最小生成树中相邻节点p和q的距离,σ是预先设定的调节两点相似性的参数;
代价聚集:
①自下而上,即从叶节点向根节点(leaftoroot)聚合,任一个像素,它的最后代价聚集值是直到它的所有孩子节点被遍历,它的代价值才更新完成:
其中,
②自上而下,即从根节点到叶节点(roottoleaf)聚合,对任一个像素,它的代价聚集值为:
其中,pr(p)是像素p的父节点。
优选地,在无纹理区域,顶点p和q之间的相似性表达式如下:
其中,cd(p)是像素p在视差为d时的匹配代价值,q遍历图像中的每个像素。
进一步地,步骤(3)具体包括:选取最小匹配代价对应的视差值为像素点最终的视差表达式如下:
其中,d为视差范围值,
根据左右两幅输入图像,分别进行代价聚集得到左右两幅视差图,再进行左右一致性检测;具体方法为:
对于左图中的一个点p视差值为d1,p在右图里的对应点应为d2=p-d1;若|d1-d2|>threshold,p标记为遮挡点,其中threshold为预先设定值。
进行孔洞填充,即对于遮挡点p,分别在水平方向上寻找左、右的第一个非遮挡点,记作pl、pr,点p的视差值为pl和pr中视差值较小的一个,即
d(p)=min(d(pl),d(pr))
对填充之后的视差图进行边缘检测;
优选地,采用canny方法对填充之后的视差图进行边缘检测。进一步地,步骤(5)具体步骤如下:
①自下而上,即从叶节点向根节点聚合,对于任一个像素,它的代价聚集值由和它在同一边缘区域内子节点决定,即:
其中,cd(p)是p点的匹配代价值,ch(p)代表着p的子节点,s(p,q)为两点间的相似权值,
其中,pr(p)是像素p的父节点;
采用wta方法求得视差值。
更近一步的,在步骤(5)中,通过视差求精得到最终的稠密视差图,包括:
左图和右图都需要作为参考图像得到左右两张视差图;
进行相互一致性检测,将像素点分为稳定点和不稳定点,稳定点能通过左右一致性检测,设dl,dr分别表示左右初始视差图,当dl(x-dp,y)≠dr(x,y)时,则认为p是不稳定点,将其视差值置为零;
对于任一视差范围的任一像素,新的代价值为:
其中,d指视差图,d是视差范围值;
在此代价值的基础上通过代价聚集更新值,更新的代价值是从稳定点传播到不稳定点,再用传统的wta进行视差值的选择,得到最后的精化视差图。
本发明的有益技术效果:
1.本发明方法采用rgb彩色信息代替单一的灰度信息,可以避免灰度图像中相同灰度、不同颜色的像素点产生的误匹配,从而提高弱纹理区域的匹配精度;
2.本发明方法采用最小生成树(mst)的非局部立体匹配方法,在整个图像上进行代价聚集,保证了每个像素点都对其他像素点有相应的权值贡献。
3.本发明方法考虑了无纹理区域的图像匹配,对原匹配代价函数值进行对数变换,实现无纹理区域的邻域在代价聚集阶段也能提供相应的权值支撑;所以,本发明提出的方法可以对有纹理区域的代价聚集有微小的影响,同时也能有效解决无纹理区域不提供有效代价聚集值的问题;
4.第一次代价聚集得到的视差图会导致边缘模糊,在视差不连续区域误匹配率较高。因此,第二次代价聚集在视差不连续区域设定聚集条件再进行约束聚集以提高匹配精度:根据图像在梯度值变化比较大的区域一般是视差变化不连续即图像边缘区域,采用wta得到的初始视差图,并用canny算子对该视差图进行边缘检测,再结合约束条件进行代价聚集;剪枝策略使得在同一边缘区域内的像素点彼此提供权值,边缘区域外的像素点根据距离信息提供一定比例的权值,减少了不同区域块的不相关像素点的相互作用,进一步提高了匹配精度。
附图说明
图1是本发明方法具体实施例的流程图;
图2是本发明具体实施例的基于最小生成树的代价聚集过程,其中:
图2(a)为本发明具体实施例自下而上遍历过程;
图2(b)为本发明具体实施例自上而下遍历过程;
图2(c)为本发明具体实施例自下而上遍历过程计算说明示意图;
图3是本发明具体实施例基于剪枝和迭代的第二次代价聚集过程,其中:
图3(a)为本发明具体实施例自下而上遍历过程;
图3(b)为本发明具体实施例自上而下遍历过程。
具体实施方式
本发明具体实施例的流程图如图1所示,一种图像非局部立体匹配方法,具体步骤包括:
1)结合颜色和梯度信息作为相似性测度函数构建代价计算函数。具体步骤包括:
11)匹配代价计算是整个立体匹配方法的基础,实际是对不同视差下进行灰度相似性测量,计算初始匹配代价值,代价函数的选取将直接影响最终视差图的精度,所以选择具有较高匹配性能的匹配代价函数是立体匹配方法面临的首要问题。本发明方法结合颜色信息和梯度信息这两种测度作为初始匹配代价函数。为了避免图像中具有相同灰度、不同颜色信息的像素点间的误匹配,采用rgb三通道信息代替单一的灰度信息,通过三通道计算出颜色信息。颜色信息cad(p,d)和梯度信息cgrad(p,d)的表达式如下:
其中,
12)确定本发明构建的初始匹配代价函数c(p,d)如下:
c(p,d)=w1cad(p,d)+w2cgrad(p,d)
其中,w1、w2分别为颜色信息和梯度信息的权值,w1+w2=1,在具体实施例中优选的,w1=0.11。
在无纹理区域,像素点的匹配代价值接近于0,因此在代价聚集阶段基本没有提供权重支持,为了解决这个问题,本发明对原匹配代价函数值进行对数变换,即:
c'(p,d)=ln(1+exp(c(p,d)))
其中,c'(p,d)是改进后的匹配代价值。通过对数变换,匹配代价值从0变成非零项,无纹理区域的邻域在代价聚集阶段也能提供相应的权值支撑。所以,本发明提出的方法可以对有纹理区域的代价聚集有微小的影响,同时也能有效地解决了无纹理区域不提供有效代价聚集值的问题。
2)分别对左右目图像构建最小生成树,并对代价函数值进行代价聚集。下面将从最小生成树的构建和聚集方法两部分进行描述。
21)最小生成树的构建
将整个图像看成一个四邻域的无向图g(v,e),图像上的每个像素点为无向图的顶点v,e为相邻像素点之间的边,但是无向图中有若干回路,不适合聚集,在一个具体实施例中,采用kruskal方法产生最小生成树,先初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里,直到所有的顶点都在一棵树中,就将其转化成了最小生成树(mst),最小生成树是连接了图像中的所有像素点,使得边权值的总和达到最小。连接相邻顶点s和r的边权值为:
we=w(s,r)=|i(s)-i(r)|
其中,i为rgb三通道中其中最大的像素值。
22)聚集方法
在最小生成树中,根据相邻像素点的远近来定义像素之间的相关性,顶点p和q之间的相似性为:
其中,s1(p,q)是初始相似性,s2(p,q)是具体实施例中提出的优选地改进相似性函数,d(p,q)表示最小生成树中相邻节点p和q的距离,σ是调节两点相似性的参数,在一个具体实施例中设为0.1。在无纹理区域,由于像素点信息相似,颜色距离差别不大但也不是非零值,相似性s1(p,q)会趋向于1,逐渐地会出现小权重累积的问题,在无纹理区域,许多小权重的边缘沿着树的路径聚集,会产生一个较高的代价聚集值,造成无纹理区域代价值过大。而改进后的相似性计算,乘上
其中,cd(p)是像素p在视差为d时的匹配代价值,q遍历图像中的每个像素。
代价聚集需要所有像素点在所有视差范围进行,最小生成树的聚集方法可以通过遍历两条路径的方式高效地计算出所有像素点的聚集值,并且每一个点的代价聚合值只与它的父节点和子树有关。代价聚集过程如图2所示(图2包括图2(a)、图2(b)和图2(c)),p为根节点,q是p的子节点。
①自下而上,即从叶节点向根节点(leaftoroot)聚合。如图2(a)所示,根节点p1的聚集值包括p1点的匹配代价值和p1的子树(p2、p3)聚集值乘两点间的相似性。
所以,对于任一个像素,它的最后代价聚集值是直到它的所有孩子节点被遍历,它的代价值才更新完成:
其中,
②自上而下,即从根节点到叶节点(roottoleaf)聚合。如图2(b)所示,子节点p2的聚集值是除了p2以及它的子树的代价值,即只来自p1点及右半部分的代价聚集值,图中的阴影节点部分。
代价聚集之后,
其中,pr(p)是像素p的父节点。
3)采用wta(winnertakesall,wta)策略即优胜者全选策略得到初始视差图,通过左右一致性检测得到不稳定点,并进行孔洞填充,然后对视差图进行边缘检测。描述如下。
31)在视差计算阶段,本发明采用wta优胜者全选的方式,每一个视差值都有一个最终的匹配代价,wta就是选取最小匹配代价对应的视差值为像素点最终的视差,即:
其中,d为视差范围值,
32)以左右两幅分别作为参考图像,树滤波两次分别得到左右两幅视差图。再进行左右一致性检测,对于左图中的一个点p视差值为d1,那么p在右图里的对应点应该是d2=p-d1。若|d1-d2|>threshold,p标记为遮挡点,threshold为设定的参数。
33)对遮挡点进行孔洞填充,即对于遮挡点p,分别在水平方向上寻找左、右的第一个非遮挡点,记作pl、pr,点p的视差值为pl和pr中视差值较小的一个,即
d(p)=min(d(pl),d(pr))
34)对填充之后的视差图进行边缘检测,在一个具体实施例中采用canny方法,目的是为了得到整个视差图像的边缘,若对原图边缘检测,深度信息不连续,得到的边缘较密,之后代价聚集的效果不是很好。而视差图的深度信息连续区域较多,边缘检测得到的区域较广,在局部区域像素进行代价聚集过程也比较方便,复杂性低。
4)根据步骤3得到的边缘图像,结合剪枝的思想对代价函数值进行进一步的聚集,即第二次迭代聚集过程。具体步骤如下。
第二次的聚集过程相当于是局部聚集,边缘将整个图像分成了很多个区域块,由于离的越近的像素点相似性越高,支撑权值也越大,所以在边缘内的区域进行代价聚集可以提高像素点的匹配率。和之前代价聚集的方法类似,只是对树结构进行剪枝,即在两次遍历的时候只有在边缘范围内的子节点和父节点提供相应的权值。
41)自下而上,即从叶节点向根节点聚合。对于任一个像素,它的代价聚集值由和它在同一边缘区域内的节点决定,具体过程如图3(a)所示。即:
其中,cd(p)是p点的匹配代价值,ch(p)代表着p的子节点,s(p,q)为两点间的相似权值,
42)自上而下,即从根节点到叶节点聚合。如图3(b)所示,根据自下而上得到的代价聚集值,当q3为根节点时,它的代价值包括q3的匹配代价值和s(p,q3)乘节点p来自其子树的总代价值,但是此时节点q3的父节点p在边缘上,对p节点以及其子树进行剪枝(即图3(b)中的灰色阴影部分),不提供相应的代价聚集值。因此,对任一个像素,它的代价聚集值由和它在同一边缘区域内的父节点决定,即:
其中,pr(p)是像素p的父节点。
接着采用和说明书3)中的wta方法求得视差值。
5)通过视差求精得到最终的稠密视差图。
51)首先,左图和右图都需要作为参考图像通过树聚集得到左右两张视差图。
52)然后,通过相互一致性检测,将像素点分为稳定点和不稳定点,稳定点能通过左右一致性检测,设dl,dr分别表示左右初始视差图,当dl(x-dp,y)≠dr(x,y)时,则认为p是不稳定点,将其视差值置为零。所以对于任一视差范围的任一像素,新的代价值为:
其中,d指视差图,d是视差范围值。
53)最后,在此代价值的基础上通过代价聚集更新值,更新的代价值是从稳定点传播到不稳定点,再用传统的wta进行视差值的选择,即得到了最后的精化视差图。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!