用于学习低精度神经网络的方法及装置与流程
本申请主张在2017年11月7日以及2017年11月8日在美国专利与商标局提出申请且被授予序列号62/582,848及62/583,390的美国临时专利申请的优先权、以及在2018年3月7日在美国专利与商标局提出申请且被授予序列号15/914,229的美国非临时专利申请的优先权,所述申请中的每一者的全部内容并入本申请供参考。
本公开大体来说涉及神经网络,且更具体来说,涉及将权重量化与激活量化进行组合的用于学习低精度神经网络的方法及装置。
背景技术:
深度神经网络近来在许多计算机视觉任务(例如,图像分类、对象检测、语义分割(semanticsegmentation)及超分辨率(superresolution))中实现了主要的性能突破。最先进的神经网络的性能得益于非常深的及过度参数化的多层架构。目前,通常在多于一百个层中存在数百万或数千万个参数。然而,在大量层中增加网络参数的数目需要使用高性能矢量计算处理器,例如配备有大量存储器的图形处理单元(graphicsprocessingunit,gpu)。此外,当对高分辨率图像及尺寸增大的视频进行处理时,对计算能力及存储器资源的需求迅速增长。
近来,深度神经网络的低精度实施方式受到极大的关注,特别是对于资源受限器件(例如,由电池供电的移动器件或便携式器件)上的深度神经网络的部署而言。在这种平台中,存储器及能力是有限的。此外,可能不支持基本浮点算术运算(floating-pointarithmeticoperation)。低精度权重(例如,参数)及激活(例如,特征图)降低了计算成本并且降低了存储器要求。由此,当计算预算和电力预算有限时,低精度权重及激活是优选的,且有时需要以降低的功耗进行高效处理。通过使用较小位宽度的低精度权重及激活而不使用较大位宽度的全精度值也可减少存储器负担。
技术实现要素:
根据一个实施例,一种用于学习低精度神经网络的方法包括:选择神经网络模型,其中所述神经网络模型包括多个层,且其中所述多个层中的每一者包括权重及激活;通过将多个量化层插入到所述神经网络模型内来修改所述神经网络模型;将成本函数与经修改的所述神经网络模型进行关联,其中所述成本函数包括与第一正则化项对应的第一系数,且其中所述第一系数的初始值是预定义的;以及训练经修改的所述神经网络模型,以通过增大所述第一系数来产生层的量化权重,直到所有权重均被量化且所述第一系数满足预定义的阈值为止,还包括优化所述量化权重的权重缩放因数以及优化量化激活的激活缩放因数,且其中所述量化权重是使用经优化的所述权重缩放因数进行量化。
根据一个实施例,一种用于学习低精度神经网络的装置包括:选择器,被配置成选择神经网络模型,其中所述神经网络模型包括多个层,且其中所述多个层中的每一者包括权重及激活;插入器件,被配置成通过将多个量化层插入到所述神经网络模型内来修改所述神经网络模型;关联器件,被配置成将成本函数与经修改的所述神经网络模型进行关联,其中所述成本函数包括与第一正则化项对应的第一系数,且其中所述第一系数的初始值是预定义的;以及训练器件,被配置成训练经修改的所述神经网络模型,以通过增大所述第一系数来产生层的量化权重,直到所有权重均被量化且所述第一系数满足预定义的阈值为止,且优化所述量化权重的权重缩放因数以及优化量化激活的激活缩放因数,其中所述量化权重是使用经优化的所述权重缩放因数进行量化。
附图说明
结合附图阅读以下详细说明,以上及其他方面、特征及本公开某些实施例的优点将更显而易见,在附图中:
图1示出根据本公开实施例的将权重量化与激活量化进行组合的用于一般非线性激活函数的低精度卷积层的方法的示例性流程图。
图2示出根据本公开实施例的将权重量化与激活量化进行组合的用于修正线性单元(rectifiedlinearunit,relu)激活函数的低精度卷积层的方法的示例性流程图。
图3示出根据本公开实施例的对低精度神经网络进行权重量化及激活量化的方法的示例性流程图。
图4示出根据本公开实施例的将权重量化与激活量化进行组合的训练低精度神经网络的方法的示例性流程图。
[符号的说明]
100、200:低精度卷积层;
101、201:卷积运算;
103、203:偏置加法运算;
105:第一比例因数乘法运算;
107:非线性激活运算/第一非线性激活运算/激活运算;
109:第二比例因数乘法运算;
111、209:量化运算;
113、211:运算;
205:relu运算;
207:比例因数乘法运算;
301、303、305、307、309、311、401、403、405、407、409、411:步骤。
具体实施方式
在下文中,参照附图详细阐述本公开的实施例。应注意,相同的元件将由相同的参考编号指示,尽管它们示出在不同的附图中。在以下说明中,提供例如详细配置及组件等具体细节仅是为了帮助全面理解本公开的实施例。因此,对所属领域中的技术人员应显而易见,在不背离本公开的范围的条件下可对本文所述的实施例作出各种改变及修改。另外,为清晰及简洁起见,省略对众所周知的功能及构造的说明。以下所述的用语是考虑到本公开中的功能而定义的用语,且可根据使用者、使用者的意图或习惯而有所不同。因此,这些用语的定义应基于本说明书通篇的内容来确定。
本公开可具有各种修改及各种实施例,以下参照附图详细阐述其中的一些实施例。然而应理解,本公开并非仅限于所述实施例,而是包括处于本公开的范围内的所有修改、等效形式及替代形式。
尽管可能使用包括例如“第一(first)”、“第二(second)”等序数词的用语来阐述各种元件,但结构元件不受这些用语限制。这些用语仅用于区分各个元件。举例来说,在不背离本公开的范围的条件下,“第一结构元件”可被称为“第二结构元件”。相似地,“第二结构元件”也可被称为“第一结构元件”。本文中所用的用语“和/或(and/or)”包括一个或多个相关项的任意及所有组合。
本文中所用的用语仅用于阐述本公开的各种实施例,而并非旨在限制本公开。除非上下文清楚地另外指明,否则单数形式旨在包括复数形式。在本公开中,应理解,用语“包括(include)”或“具有(have)”指示特征、数目、步骤、操作、结构元件、部件或其组合的存在,而不排除一个或多个其他特征、数字、步骤、操作、结构元件、部件或其组合的存在或添加的可能。
除非进行不同地定义,否则本文中所用的所有用语具有与本公开所属领域中的技术人员所理解的含意相同的含意。例如在常用字典中所定义的用语等用语应被解释为具有与相关技术领域中的上下文含意相同的含意,且除非在本公开中进行清楚定义,否则不应将其解释为具有理想化或过于正式的含意。
根据一个实施例,本系统及方法获得具有量化权重及量化激活(例如,特征图)的低精度神经网络。量化权重及量化激活由低精度(例如,较低位宽度)的固定点数表示。在神经网络的每一个层中分别为权重及激活定义共用缩放因数(commonscalingfactor)以涵盖权重及激活的对于每一个层均发生变化的动态范围。本系统及方法提供权重量化及激活量化。
对于权重量化而言,本系统在神经网络的每一个层中以权重的均方量化误差(meansquarequantizationerror,msqe)的正则化系数对神经网络进行训练。根据一个实施例,正则化系数是可学习参数。在初始时,可将正则化系数设定成小的且对高精度(例如,较大位宽度)模型进行训练。随着训练继续进行,本系统逐渐增大正则化系数以使正则化系数迫使权重越来越被量化。本系统在正则化系数变得足够大而使开始时为高精度模型的经训练模型收敛到仅具有量化权重的低精度模型时完成网络训练。在训练期间,每一个层中的权重的缩放因数也是可学习的以使本系统对缩放因数进行优化来将msqe最小化。
对于激活(例如,特征图)量化而言,本系统包括量化层。量化层是输出输入的量化值的非线性层。类似于权重量化,在每一个层中定义激活的可学习缩放因数,且在训练期间优化所述可学习缩放因数。将每一个层中的激活的msqe最小化以进行优化。量化层在训练期间产生量化激活且权重是基于量化激活进行优化。相反,权重不在训练迭代期间被量化,而是随着由于msqe正则化及增大的正则化系数继续进行训练,每一权重会逐渐收敛到量化值。
通过将权重量化过程与激活量化过程进行组合,本系统提供用于学习低精度神经网络的统一训练方法。根据一个实施例,除了用于低精度神经网络的本训练过程之外,本系统及方法还提供对可应用的权重及激活的2的幂缩放因数进行的正则化。当2的幂缩放由位移来实施而非由标量乘法来实施时,2的幂缩放在计算上可为有利的。
根据一个实施例,本系统关注具有量化权重及量化激活(例如,特征图)的低精度神经网络。每一个层中的量化权重及量化激活分别由相似位宽度的低精度固定点数(low-precisionfixed-pointnumber)表示。在神经网络的每一个层中分别另外地定义权重及激活的共用缩放因数以涵盖权重及激活的对于每一个层均发生变化的动态范围。缩放因数是量化单元大小(quantizationcellsize),其对于线性量化而言是固定的。
低精度神经网络可由低精度固定点算术运算来实施。
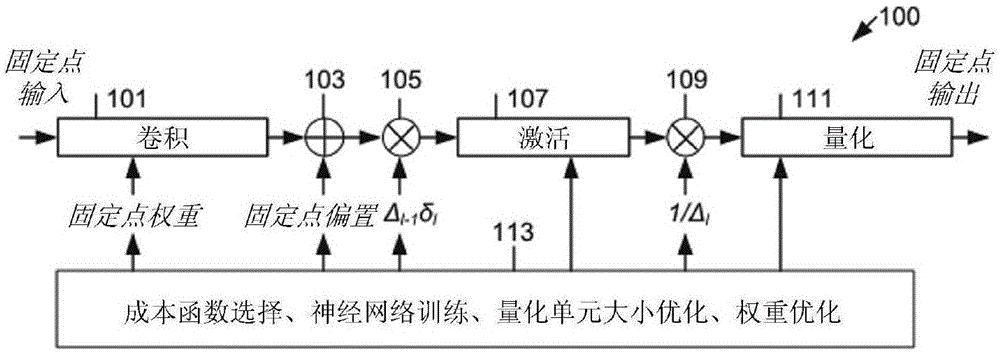
图1示出根据本公开实施例的将权重量化与激活量化进行组合的用于一般非线性激活函数的低精度卷积层100的方法的示例性流程图。
参照图1,低精度卷积层100的固定点设计包括卷积运算101、偏置加法运算103、第一比例因数乘法运算105、非线性激活运算107、第二比例因数乘法运算109、量化运算111及用于成本函数选择、神经网络训练、量化单元大小优化及权重优化的运算113。
图1所示方法包括选择神经网络模型,其中神经网络模型包括多个层。在实施例中,可使用选择器来选择神经网络模型。所述多个层中的每一者可包括权重及激活。可通过将多个量化层插入到神经网络模型内来修改神经网络模型。在实施例中,可使用插入装置来插入所述多个量化层。将成本函数与经修改的神经网络模型进行关联,其中所述成本函数包括与第一正则化项对应的第一系数,且第一系数的初始值是预定义的。在实施例中,可使用关联装置来将成本函数与经修改的神经网络模型进行关联。训练经修改的神经网络模型以通过增大第一系数来产生层的量化权重直到所有权重均被量化且第一系数满足预定义的阈值为止,并且优化量化权重的权重缩放因数以及优化量化激活的激活缩放因数,其中量化权重是使用经优化的权重缩放因数进行量化。在实施例中,可使用训练装置来提供训练。
权重缩放因数及激活缩放因数可基于将均方量化误差(msqe)最小化来进行优化。
可将所述多个量化层中的每一量化层插入到神经网络模型内每一个层中的每一激活输出之后。
成本函数可包括与第二正则化项对应的第二系数,第二正则化项基于权重缩放因数及激活缩放因数为2的幂数字。
可将量化权重、权重缩放因数及激活缩放因数应用于固定点神经网络,其中固定点神经网络包括多个卷积层,其中所述多个卷积层中的每一者包括卷积运算,所述卷积运算被配置成接收特征图及量化权重。偏置加法运算可被配置成接收卷积运算的输出、及偏置。第一乘法运算可被配置成接收偏置加法运算的输出、及第一比例因数。激活运算可被配置成接收第一乘法运算的输出。第二乘法运算可被配置成接收激活运算的输出及第二比例因数,且量化运算可被配置成接收第二乘法运算的输出。
可通过以下方式训练神经网络:通过随机梯度下降方法来更新权重;通过随机梯度下降方法来更新权重缩放因数;通过随机梯度下降方法来更新激活缩放因数;如果权重缩放因数及激活缩放因数是2的幂,则包括随机梯度下降方法的附加梯度;通过随机梯度下降方法来更新正则化系数;以及如果正则化系数大于预定常数或者所述随机梯度下降方法的迭代次数大于预定限值,则结束训练。
权重可为固定点权重。第一比例因数可为权重缩放因数与激活缩放因数的乘积。激活运算可为非线性激活函数。
量化权重、权重缩放因数及激活缩放因数可应用于固定点神经网络,其中固定点神经网络包括多个卷积层,且其中所述多个卷积层中的每一者包括卷积运算,所述卷积运算被配置成接收特征图及量化权重。偏置加法运算可被配置成接收卷积运算的输出、及偏置。修正线性单元(relu)激活运算可被配置成接收偏置加法运算的输出。比例因数乘法运算可被配置成接收relu激活运算的输出及比例因数,且量化运算可被配置成接收比例因数乘法运算的输出。
比例因数可为权重缩放因数与激活缩放因数的乘积。
卷积运算101接收特征图(例如,固定点(fixed-point,fxp)输入)及固定点权重(例如,fxp权重)。在一个实施例中,卷积运算101是利用低精度固定点乘法器及累加器实施的。
偏置加法运算103接收卷积运算101的输出、及偏置,并对卷积运算101的输出与偏置求和。
对于层l,可以权重缩放因数δl及输入特征图缩放因数δl-1来对固定点权重及输入特征图进行缩放。举例来说,可由第一比例因数乘法运算105以权重缩放因数δl与输入特征图缩放因数δl-1的乘积(例如,δl-1δl)来对偏置加法运算103的输出进行缩放,第一比例因数乘法运算105接收偏置加法运算103的输出、及缩放因数δl-1δl并从偏置加法运算103的输出与缩放因数δl-1δl产生乘积。在一个实施例中,可通过以缩放因数δl-1δl对偏置进行缩放来避免对偏置加法运算103的输出进行缩放。
第一非线性激活运算107接收第一比例因数乘法运算105的输出。
非线性激活运算107的输出以缩放因数1/δl进行缩放。举例来说,第二比例因数乘法运算109接收激活运算107的输出、及缩放因数(例如,1/δl)并产生激活运算107的输出与缩放因数的乘积。
量化运算111将第二比例因数乘法运算109的输出量化(例如,fxp输出)。
运算113选择成本函数,训练神经网络,优化量化单元大小并优化权重。
图2示出根据本公开实施例的将权重量化与激活量化进行组合的用于relu激活函数的低精度卷积层200的方法的示例性流程图。
参照图2,低精度卷积层200包括卷积运算201、偏置加法运算203、relu运算205、比例因数乘法运算207、量化运算209及用于成本函数选择、神经网络训练、量化单元大小优化及权重优化的运算211。
卷积运算201接收特征图(例如,fxp输入)及固定点权重(例如,fxp权重)。在一个实施例中,卷积运算201是利用低精度固定点乘法器及累加器实施的。
偏置加法运算203接收卷积运算201的输出、及偏置,并对卷积运算201的输出与偏置求和。
relu运算205接收偏置加法运算203的输出。
对于层l,可分别以缩放因数δl及δl-1来对固定点权重及输入特征图进行缩放。举例来说,可由比例因数乘法运算207以权重缩放因数δl与输入特征图缩放因数δl-1的乘积除以δl(例如,(δl-1δl)/δl)来对relu运算205的输出进行缩放,比例因数乘法运算207接收relu运算205的输出及缩放因数δl-1δl/δl,并从relu运算205的输出与缩放因数δl-1δl/δl产生乘积。也就是说,图1中所示的两个缩放运算在图2中被组合成一个缩放运算。如果缩放因数是2的幂数字,则可通过位移来实施缩放。相似地,可通过利用简单矩阵乘法取代卷积来实施全连接层(fully-connectedlayer)。
量化运算209将比例因数乘法运算207的输出量化(例如,fxp输出)。
运算211选择成本函数,训练神经网络,优化量化单元大小并优化权重。
在低精度神经网络中,可提供并固定权重及激活的位宽度。可选择用于固定点权重及激活的缩放因数。在确定最优缩放因数的同时,本系统对低精度固定点权重进行优化。根据一个实施例,本系统及方法同时学习量化参数及量化固定点权重。
根据一个实施例,本系统及方法提供包括权重量化及激活量化的低精度神经网络量化。
可定义量化函数。可提供用于表示每一量化值的位数。对于位宽度n而言(其中n是整数),量化函数输出如以下方程式(1)中所示:
qn(x;δ)=δ·clip(round(2/δ),[-2n-1,2n-1-1]),…(1)
其中x是输入且δ是量化单元大小(例如,共用缩放因数);且舍入函数(roundingfunction)及裁减函数(clippingfunction)如以下方程式(2)及方程式(3)中所示:
clip(x,[a,b])=min(max(x,a),b),…(3)
其中x、a、及b是输入。
对于具有l个层的一般非线性神经网络而言,w1,w2,...,wl分别为层1到层l中的权重集合,其中l是整数。为使标注简明起见,对于任何符号a而言,方程式(4)均如下:
对于权重量化而言,本系统提供所有l个层中的权重的msqe的平均值的正则化项,即,如以下方程式(5)中所示:
其中n是低精度权重的位宽度,δl是量化单元大小(即,层l中的权重的共用缩放因数),且n是所有l个层中的权重的总数目,即
根据一个实施例,本系统提供可学习正则化系数以利用以上msqe正则化逐渐获得量化权重。正则化系数可为另一个可学习参数。本系统从小的正则化系数(例如,预定义的正则化系数)开始,以小的性能损失来学习高精度模型。随着训练继续进行,本系统增大正则化系数直到在训练完成时存在量化权重为止。包括小的正则化系数的附加惩罚项(additionalpenaltyterm),例如,-logα,其中α是正则化系数。权重量化的成本函数如以下方程式(6)中所示:
其中
本系统对网络训练中的成本函数进行优化并更新权重、量化单元大小及可学习正则化系数。由于存在对小的α值的惩罚项即-logα(其中α使正则化项rn的重要性在训练期间连续增大),此使用于权重量化的正则化增大且使权重能够通过完成训练而得到量化。正则化系数逐渐增大,只要网络损失函数不明显降低即可。
对于激活量化而言,本系统提供量化层。对于原始全精度模型而言,在需要对低精度模型进行激活量化的任何位置(例如,在每一激活函数之后)插入用于激活的量化层。本系统可在从1到l的每一现存的层之后插入量化层。对于来自层l的激活x而言,量化层输出qm(x;δl),其中qm是位宽度m的量化函数,且δl是层l的输出激活的可学习量化单元大小(例如,共用缩放因数)。
本系统通过将层l的输出激活的msqe最小化来对δl进行优化,如以下方程式(7)中所示:
其中xl是层l的输出激活值的集合,条件是1≤l≤l。此外,通过假设量化层是紧挨在第一层之前插入以对网络输入进行量化(即,其中x0是网络输入值的集合且δ0是网络输入的量化单元大小),l可包括l=0。
在训练中将量化层激活以产生量化激活来针对量化激活对权重进行优化。相反,权重量化方法实际上不会在训练期间一次将权重全部量化。权重是在训练期间逐渐被量化的,其中由于msqe正则化,每一个权重会随着训练以增大的正则化系数进行而逐渐收敛到量化值。
2的幂量化单元大小(例如,共用缩放因数)当由位移实施而非由标量乘法实施时会在计算方面提供有益之处。可如以下在方程式(8)中所示来引入附加正则化项:
其中roundpow2是舍入到最接近的2的幂值的舍入函数,即,如以下方程式(9)中所示:
利用可学习正则化系数,本系统在训练期间将量化单元大小逐渐收敛到最优的2的幂值。举例来说,可通过对以下方程式(10)所示的成本函数进行优化来获得以2的幂的量化单元大小进行的权重量化:
其中λ及ζ是为进行训练而选择及固定的超参数。相似地,可通过
图3示出根据本公开实施例对低精度神经网络进行权重量化及激活量化的方法的示例性流程图。
参照图3,在301处,本系统选择具有位宽度n及m的神经网络模型,其中n及m是整数。低精度神经网络的量化方法包括分别针对低精度权重及低精度激活来选择具有位宽度n及m的原始神经网络模型(例如,位宽度可针对不同层而为不同的或者针对所有层为固定的)。
在303处,本系统通过插入量化层对所选择的神经网络模型进行修改。举例来说,在每一激活输出之后及第一层输入之前插入量化层。
在305处,本系统选择成本函数。举例来说,成本函数如以下方程式(11)中所示:
其中λ及η是在训练之前选择及固定的超参数。
在307处,如果量化单元大小是2的幂,则本系统在成本函数中包括附加正则化项,如以下方程式(12)中所示:
其中ζ1及ζ2是在训练之前选择及固定的超参数。
在309处,本系统对网络进行训练以产生经优化的量化单元大小。
在311处,本系统利用经优化的量化单元大小对权重进行优化。在训练结束之后,本系统可利用经优化的量化单元大小
图4示出根据本公开实施例的将权重量化与激活量化进行组合的训练低精度神经网络的方法的示例性流程图。根据一个实施例,图4可如由图3中的309所表示的一样来实施。
利用以迷你批(mini-batch)进行的随机梯度下降,通过随机梯度下降方法的一种来更新每一可学习参数p(例如,权重、量化单元大小、正则化系数),例如如以下方程式(13)中所示:
参照图4,在401处,本系统利用如以下方程式(14)中所示梯度来更新w1l中的权重:
其中bn(δl)是线性量化单元边界的集合,即,如以下方程式(15)中所示:
第一项
在403处,本系统利用以下方程式(16)所示梯度来更新权重量化单元大小
其中
在405处,本系统更新权重正则化系数α。并非直接更新α,本系统利用如以下方程式(17)中所示的梯度来更新γ=logα:
在407处,本系统利用以下方程式(18)所示梯度来更新激活量化单元大小
其中
在409处,如果需要2的幂量化单元大小,则如以下方程式(19)及方程式(20)所示包括附加梯度:
在训练期间,利用以下方程式(21)及方程式(22)的梯度更新ω1=logβ1及ω2=logβ2。
在411处,如果对于足够大的预定常数a而言α>a或如果迭代次数大于预定数目,则训练结束。
为能够通过量化层进行反向传播,当输入处于裁剪边界内时,本系统使用将梯度从上层传递到下层的直通估算器(straight-throughestimator)。在裁剪边界外部,梯度被确定成零。在量化中可使用随机舍入而非确定性舍入来实现更好的收敛。
梯度的附加计算成本并不昂贵,且附加复杂度仅以o(n)增长,其中n是权重的数目。因此,上述方法适用于具有数百万或数千万个参数的深度神经网络。
根据一个实施例,权重量化方法可扩展到包括权重修剪。也就是说,对于阈值θ而言,用于权重量化与权重修剪两者的函数可如以下方程式(23)中一样进行定义:
如果输入小于阈值θ,则以上方程式(23)输出零。否则,方程式(23)输出输入的量化值。接着,为了除实现权重量化之外还实现权重修剪,将以上方程式(5)中的权重正则化修改为以下方程式(24):
其中θl是预定常数或每一训练迭代中的权重值的函数。
举例来说,对于每一层l中的目标权重修剪速率rl而言,可从每一个层中的权重的绝对值的第r个百分位获得阈值θl,阈值θl可在每一训练迭代中更新。正则化接着迫使低于阈值θl的权重朝零逼近,同时将其他权重量化成它们最近的单元中心。经量化的低精度权重的大小可通过可变速率编码(例如,赫夫曼编码(huffmancoding)或算术编码)得到进一步压缩。
举例来说,对于权重修剪而言,修剪函数可如以下方程式(25)中所示:
权重修剪正则化项可如以下方程式(26)中所示:
其中θl是预定常数或每一训练迭代中的权重值的函数。
类似于以上方程式(24),对于每一层l中的目标权重修剪速率rl而言,可从每一个层中的权重的绝对值的第r个百分位获得阈值θl,且阈值θl可在每一训练迭代中更新。正则化接着使低于阈值θl的权重朝零移动。
根据一个实施例,本系统提供具有量化权重及量化特征图的低精度神经网络。举例来说,假设分别对每一个层中的权重及特征图应用共用缩放因数(即,固定量化单元大小),则经量化的权重及特征图由低精度的固定点数表示。由于固定点权重及特征图为低精度,因此本系统会降低存储/存储器要求及降低计算成本;可使用固定点算术运算而非全精度浮点算术运算。
尽管已在本公开的详细说明中阐述了本公开的某些实施例,然而在不背离本公开的范围的条件下可以各种形式对本公开进行修改。因此,本公开的范围不应仅基于所阐述的实施例来确定,而是应基于随附权利要求及其等效范围来确定。
- 还没有人留言评论。精彩留言会获得点赞!