一种神经网络机器学习模型的训练方法及装置与流程
本申请涉及但不限于计算机技术,尤指一种神经网络机器学习模型的训练方法及装置。
背景技术:
神经网络机器翻译(nmt,neuralmachinetranslation)模型提出后,由于翻译效果获得明显提升,近年来得到了不断发展。目前在某些语种和场景下,译文质量甚至可以达到人工翻译的水平。
但是,由于nmt模型的结构复杂,且深度神经网络模型本身的训练过程一般会涉及大量的计算,因此,nmt系统往往需要较长的训练周期,比如,使用3000万的训练数据在处理器如单块图形处理单元(gpu)卡上训练,需要训练20天以上才能得到一个初步可用的模型。
已有的神经网络并行训练加速方案主要是基于数据并行(dataparallel)的同步随机梯度下降(sgd)算法,即:使用多个worker进程均摊一个小批量(mini-batch)训练数据的计算量,把求得的梯度加和求平均的方法。标准的同步sgd算法的每次迭代都分为三个步骤,首先,从参数服务器(ps,parameterserver)中将模型参数拉(pull)到本地;接着,利用得到的新的模型参数计算本地训练数据的梯度;最后,将计算出的梯度推(push)到参数服务器。参数服务器需要收集所有workers进程返回的梯度,再统一处理更新模型参数。其中,mini-batch是神经网络模型训练中的训练数据一次批处理的规模。
上述基于梯度平均的方案,一方面,对于跨节点并行,由于受限于网卡性能,模型训练的计算加速比很快会达到上限,而且,随着机器数的增多,不但没有带来加速的效果,反而比单卡更慢。最坏的情况甚至一开始就由于计算通信比较小而不能进行多卡扩展。另一方面,如果为了提高计算通信比,成倍增大mini-batch尺寸(size),当其高于最优经验值时,会大大降低模型收敛精度。再则,随着并行规模的增加,单个gpu的计算性能不能被充分利用,从而也造成了浪费。其中,mini-batchsize是随机梯度下降法中最重要的超参数之一,mini-batchsize直接关系到训练的计算速度和收敛速度。
其中,收敛加速比是指,单卡方案下模型训练至收敛的绝对时间和分布式方案下模型训练至收敛的绝对时间之间的倍数关系。计算加速比是指,单卡方案下完成一个单位训练数据的训练时间和分布式方案下完成同样大小的训练数据的训练时间之间的倍数关系。
技术实现要素:
为了解决上述技术问题,本发明提供一种神经网络机器学习模型的训练方法及装置,能够大大缩短模型训练的周期。
为了达到本发明目的,本发明提供了一种神经网络机器学习模型的训练方法,应用于分布式计算框架中,该分布式计算框架包括多个计算节点,预先将训练数据切分成训练数据切片,且切分的切片数量和参与计算的计算节点的数量相同;包括:
计算节点获取训练数据切片,对本地模型参数进行训练;
计算节点将训练好的本地模型参数传输给参数服务器;
计算节点根据参数服务器返回的全局模型参数更新本地的本地模型参数,并继续对本地模型参数进行训练。
可选地,所述更新本地的本地模型参数之后,所述继续对本地模型参数的训练之前,还包括:
利用牛顿动量方法更新所述本地模型参数中已知的历史梯度。
可选地,当到达预先设置的更新周期时,所述计算节点执行所述将训练好的本地模型参数传输给参数服务器的步骤。
可选地,所述对本地模型参数进行训练包括:
所述计算节点采用独立的进程,利用所述训练数据切片对所述本地模型参数进行训练。
可选地,所述每个所述进程采用相同或不同的优化算法训练所述本地模型参数。
本申请还提供了一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述的神经网络机器学习模型的训练方法。
本申请又提供了一种用于实现神经网络机器学习模型的训练的装置,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:获取训练数据切片,对本地模型参数进行训练;将训练好的本地模型参数传输给参数服务器;根据参数服务器返回的全局模型参数更新本地的本地模型参数,并继续对本地模型参数进行训练。
本申请再提供了一种神经网络机器学习模型的训练方法,包括:
参数服务器获取来自不同计算节点上报的本地模型参数;
利用获得的本地模型参数计算梯度冲量并更新全局模型参数;
将更新后的全局模型参数传输给各计算节点。
可选地,当到达预先设置的更新周期时,执行所述参数服务器获取来自不同计算节点上报的本地模型参数的步骤。
可选地,所述参数服务器使用队列收集来自所述计算节点的若干进程的本地模型参数。
可选地,所述利用获得的本地模型参数计算梯度冲量并更新全局模型参数包括:
利用逐块模型更新滤波分布式算法,对队列中来自不同进程的所有本地模型参数求平均,获得当前更新周期内所有进程共同训练出的平均模型参数;
计算所述参数服务器自身存储的全局模型参数和获得的平均模型参数的差值,作为周期梯度;
将梯度冲量以周期冲量率为权重累加到周期梯度上;
以周期学习率为步长,将得到的周期梯度更新至全局模型参数,并将周期梯度累加在梯度冲量中。
可选地,所述周期学习率问为1;所述周期冲量率为1-1/n,其中,n为所述进程的个数。
本申请又提供了一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述的神经网络机器学习模型的训练方法。
本申请再提供了一种用于实现神经网络机器学习模型的训练的装置,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:获取来自不同计算节点上报的本地模型参数;利用获得的本地模型参数计算梯度冲量并更新全局模型参数;将更新后的全局模型参数传输给各计算节点。
与现有技术相比,本申请技术方案至少包括:应用于分布式计算框架中,该分布式计算框架包括多个计算节点,预先将训练数据切分成训练数据切片,且切分的切片数量和参与计算的计算节点的数量相同;包括:计算节点获取训练数据切片,对本地模型参数进行训练;计算节点将训练好的本地模型参数传输给参数服务器;计算节点根据参数服务器返回的全局模型参数更新本地的本地模型参数,并继续对本地模型参数进行训练。本申请使得其在多节点的计算加速比几乎可达线性理想值,大大缩短了模型训练的周期。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
附图用来提供对本申请技术方案的进一步理解,并且构成说明书的一部分,与本申请的实施例一起用于解释本申请的技术方案,并不构成对本申请技术方案的限制。
图1为本申请神经网络机器学习模型的训练方法第一实施例的流程图;
图2为本申请神经网络机器学习模型的训练方法第二实施例的流程图;
图3为本申请分布式神经网络机器学习模型的训练系统的组成结构示意图;
图4为本申请计算节点的组成结构示意图;
图5为本申请参数服务器的组成结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚明白,下文中将结合附图对本申请的实施例进行详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。
在本申请一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flashram)。内存是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括非暂存电脑可读媒体(transitorymedia),如调制的数据信号和载波。
在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行。并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
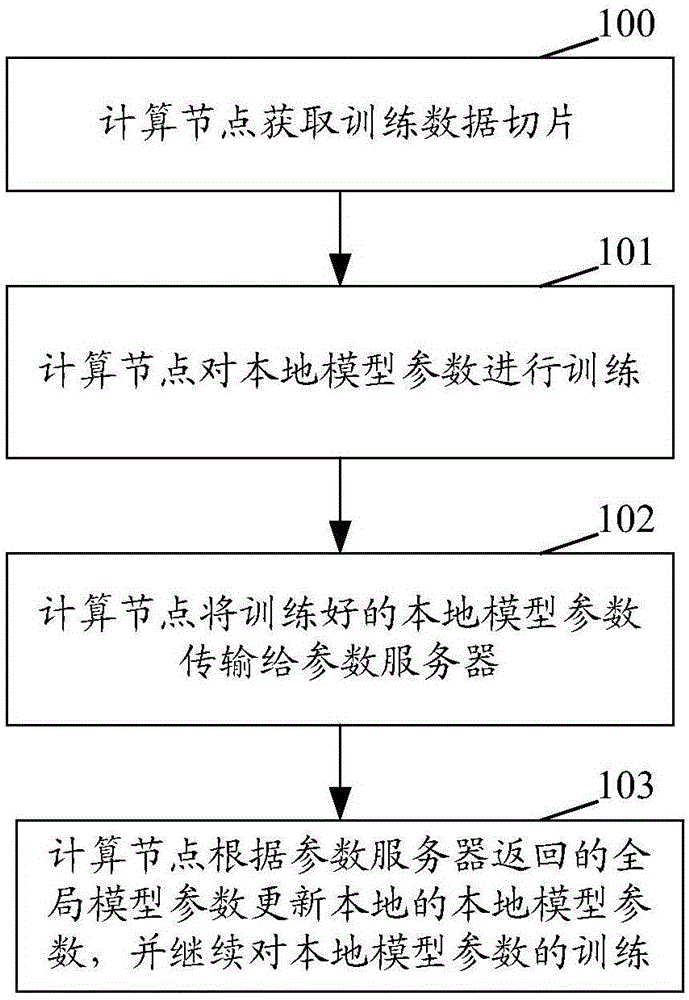
为了缩短模型训练的周期,本申请发明人提出一种基于逐块模型更新滤波(bmuf,blockwisemodel-updatefiltering)的分布式神经网络训练方法,图1为本申请神经网络机器学习模型的训练方法第一实施例的流程图,应用于分布式计算框架中,该分布式计算框架包括多个计算节点,预先将训练数据切分成训练数据切片,且切分的切片数量和参与计算的计算节点的数量相同;如图1所示,包括:
步骤100:计算节点获取训练数据切片。
每个计算节点分别获取训练数据切片。
计算节点指的是分布式框架下的一个计算节点,在分布式模型训练中承担计算任务,一般为一个计算机进程(process),表示应用程序在内存环境中基本执行单元的概念。
训练数据指的是用于训练模型的数据样本集合。
本步骤之前还包括:按照计算节点个数对训练数据进行等量切片;将每一个训练数据切片分别设置到不同的计算节点上,以完成对训练数据的配置。具体实现属于本领域技术人员的常用技术手段,具体实现并不用于限定本申请的保护范围,这里不再赘述。
步骤101:对本地模型参数进行训练。
可选地,对本地模型参数进行训练包括:
每个计算节点采用独立的进程,利用获得的训练数据切片对本地模型参数进行训练。
在每个计算节点上,都会启动一个worker进程进行计算,以独立地对本地模型参数(即全局模型参数的副本)进行训练。
不同计算节点上的每个worker进程可以采用相同或不同的优化算法训练本地模型参数。这里,可以采用机器学习领域常用的优化算法进行单机训练,比如sgd、adagrad、adam等。
需要说明的是,在本申请神经网络机器学习模型的训练装置初始化时,会直接拷贝全局模型参数作为本地模型参数即全局模型参数的副本,但是,在周期内的训练中,每个worker进程的本地参数模型可以是不一样的。
神经网络模型中的神经元的连接权重称为模型参数,模型参数(modelparameter)是训练过程中学习到的模型参数或权重,全局模型参数指在分布式系统中,存储在参数服务器上的模型参数,被所有计算节点上的worker进程共享;本地模型参数是指分布式系统中,分别存储在各计算节点本地的模型参数,只对当前worker进程可见。
本申请实施例中,每个计算节点分配一个worker进程承担计算任务。也就是说,每个worker进程具有一个独立完整的本地模型参数。
步骤102:计算节点将训练好的本地模型参数传输给参数服务器。
可选地,当到达预先设置的更新周期时,计算节点执行所述将训练好的本地模型参数传输给参数服务器的步骤。
参数服务器在分布式模型训练中存储有全局模型参数。
每个worker进程训练预先设置数量m个mini-batch,也就是完成一个训练周期后即到达模型更新点,会将本地模型参数传输给ps,并进入等待状态。
其中,预先设置数量m表示一个更新周期中的mini-batch的个数,可以根据模型参数的量以及网卡带宽来设置。
步骤103:计算节点根据参数服务器返回的全局模型参数更新本地的本地模型参数,并继续对本地模型参数的训练。
本步骤中,每个worker进程等待全局模型参数更新完毕后,下载新的全局模型参数更新本地模型参数,并返回步骤101继续下一个周期的训练,直至全局模型收敛即当翻译质量的指标稳定不再波动即为收敛。
可选地,在更新本地的本地模型参数之后,返回步骤101继续下一个周期的训练之前,还包括:
结合相关技术中的牛顿动量(nesterov)方法更新本地模型参数中已知的历史梯度。这样,实现了进一步加速收敛。nestorov是对传统动量(momentum)方法的一项改进,momentum模拟了物体运动时的惯性。
可选地,每个worker进程在向ps上传完本地模型参数后,会等待接收来自ps一个指示信号,只有接收到这个指示信号才下载新的全局模型参数。该指示信号表示ps已完成对全局模型参数的更新。
本申请上述bmuf周期性更新模型参数的方式,使得其在多计算节点的计算加速比几乎可达线性理想值,大大缩短了模型训练的周期。
图2为本申请神经网络机器学习模型的训练方法第二实施例的流程图,如图2所示,包括:
步骤200:参数服务器获取来自不同计算节点上报的本地模型参数。
可选地,当到达预先设置的更新周期时,执行本步骤的参数服务器获取来自不同计算节点上报的本地模型参数。
可选地,ps可以使用队列(queue)收集来自各计算节点的若干worker进程的本地模型参数。
步骤201:利用获得的本地模型参数计算梯度冲量并更新全局模型参数。
本步骤中,可以采用逐块模型更新滤波(bmuf,blockwisemodel-updatefiltering)分布式算法实现对全局模型参数的更新。经过试验证明,bmuf算法中训练数据切片对收敛速度的影响显著。
bmuf算法是一种以若干迭代为一个模型更新周期的模型训练方法,通过引入梯度的历史量,对modelaverage进行优化,可以在灵活的模型更新周期上运用多种优化策略,如梯度冲量(momentum)、nesterov等。
其中,momentum模拟了物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向(梯度冲量),同时利用当前mini-batch的梯度微调最终的更新方向。可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力。nestorov是对传统momentum方法的一项改进,因为在训练之前已经提前知道模型的部分更新方向momentum,因此,可以提前按照原来的更新方向更新一步,然后在该位置计算梯度值,最后再用这个梯度值修正最终的更新方向。
可选地,本步骤具体包括:
对队列中来自不同worker进程的所有本地模型参数求平均,获得当前更新周期内所有worker进程共同训练出的平均模型参数;
计算ps自身存储的全局模型参数和获得的平均模型参数的差值,作为周期梯度(blockgradients);
将momentum以周期冲量率(blockmomentumrate)为权重累加到blockgradients上;其中,梯度冲量的初始值在训练开始之初为0。
以周期学习率(blocklearningrate)为步长,将得到的blockgradients更新至全局模型参数,并将blockgradients累加在momentum中。
可选地,blocklearningrate可以设置为1.0;
可选地,blockmomentumrate可以设置为1-1/n,其中,n为worker进程的个数;学习率(learningrate)、momentumrate和单卡baseline保持一致。其中,learningrate代表一次mini-batch计算出的梯度在模型参数上的更新权重。
计算加速比是训练数据吞吐量的加速比,却不完全等价于收敛加速比,提高收敛加速比才是分布式加速的最重要指标。由于计算加速比通常小于收敛加速比,计算加速比由分布式系统的消息传输行为特点来决定,但是收敛极速比才能体现分布式系统的质量。本申请中上述对周期学习率、周期冲量率等超参数的设置使得收敛加速比与像计算加速比一样高,很好地促使了分布式训练收敛的加速完成。
通过实验证明,在单机单卡基础上,采用本申请提供的神经网络机器学习模型的训练方法,在2机4张gpu卡上,达到了相对于单机单卡3倍以上的收敛加速比;在4机8张gpu卡上,达到了相对于单机单卡5倍以上的收敛加速比;在8机16张gpu卡上,达到了相对于单机单卡9倍以上的收敛加速比。也就是说,通过不断累加gpu卡数,收敛加速比预期还会继续提升。
步骤202:将更新后的全局模型参数传输给各计算节点。
本申请基于bmuf的分布式训练方法,可以通过灵活调整模型参数的更新周期ui模型对模型参数进行更新,而不像同步sgd分布式算法基于gradientaverage,每步都需要更新模型参数,因此,本申请的神经网络机器学习模型的训练方法不会受限于网卡性能,实现了计算加速比在现有资源上接近理想值。
本申请基于bmuf的分布式训练方法,在两次模型参数更新之间,在worker进程的本地模型参数上训练,mini-batchsize可以设置为经验最优值,无需根据worker进程数量同比例缩小,对最后的收敛效果影响很小。
随着计算规模的增加,应用本申请基于bmuf的分布式训练方法,只需调整模型参数的更新周期来适应并行环境即可,单个worker进程的计算量可以和单卡训练时保持一致,对计算节点上处理器的利用率无影响。
本申请发明人通过实验得到:对于使用3000万的训练数据的神经网络训练,利用本申请基于bmuf的分布式神经网络训练方法,大大提高了训练速度,使模型参数训练时间从20天缩短到了4天,为项目整体迭代和推进节省大量时间成本。以在4张gpu卡上进行训练为例,相比于相关技术达到了3倍以上的收敛加速比,以在8张gpu卡上进行训练为例,相比于相关技术达到了5倍以上的收敛加速比,以在16张gpu卡上进行训练为例,相比于相关技术达到了9倍以上的收敛加速比。并且,由于本申请基于分布式系统,增强了系统的可扩展性,保证了在通过不断累加gpu卡数的基础上,收敛加速比预期还会继续提升。
本申请还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述的神经网络机器学习模型的训练方法。
本申请还提供一种用于实现神经网络机器学习模型的训练的装置,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:获取训练数据切片,对本地模型参数进行训练;将训练好的本地模型参数传输给参数服务器;根据参数服务器返回的全局模型参数更新本地的本地模型参数,并继续对本地模型参数进行训练。
本申请再提供一种用于实现神经网络机器学习模型的训练的装置,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:获取来自不同节点上报的本地模型参数;利用获得的本地模型参数计算梯度冲量并更新全局模型参数;将更新后的全局模型参数传输给各节点。
下面结合具体实例对本申请进行详细描述。
图3为本申请分布式神经网络机器学习模型的训练系统的组成结构示意图。如图3所示,图中,每个计算节点采用一个独立的worker进程,如第一worker进程、第二worker进程…第nworker进程,其中,n为计算节点数量即worker进程数量。
在本申请的基于bmuf分布式训练框架中,作为状态变量的模型参数x被复制n份,n为worker进程的个数。每个worker进程在两次全局模型更新之间独立训练本地模型参数,无需和其他worker进程之间通信,这样,显著加速了整个分布式框架的训练数据吞吐量。在本申请的基于bmuf分布式训练框架中,ps上保存有全局模型参数,对全局模型参数的周期性的更新,相比于相关技术中基于dataparalle的同步sgd算法,支持了多个worker进程的本地多步训练、ps上全局周期性更新的bmuf分布式算法,因此,计算通信比实现了灵活调整,而且,每个worker进程上的mini-batchsize也实现了保持单卡的规模。
图4为本申请计算节点的组成结构示意图,如图4所示,至少包括:获取模块、训练模块,以及第一传输模块;其中,
获取模块,用于获取训练数据切片;
训练模块,用于对本地模型参数进行训练;将训练好的本地模型参数输出给传输模块;根据来自传输模块的全局模型参数更新本地的本地模型参数,并继续对本地模型参数的训练,直至本地模型收敛。
第一传输模块,用于将训练好的本地模型参数传输给参数服务器;接收来自参数服务器的全局模型参数并输出给训练模块。
可选地,还包括:判断模块,用于判断出到达预先设置的更新周期时,通知训练模块;相应地,训练模块还用于:接收到来自判断模块的通知,执行所述将训练好的本地模型参数输出给传输模块。
可选地,在下载新的全局模型参数作为本地模型参数之后,继续对本地模型参数的训练之前,训练模块还用于:结合相关技术中的nesterov方法更新本地模型参数中已知的历史梯度。
图5为本申请参数服务器的组成结构示意图,如图5所示,至少包括:第二传输模块、处理模块;其中,
第二传输模块,用于获取来自不同计算节点上报的本地模型参数;将更新后的全局模型参数传输给各计算节点。
处理模块,用于利用获得的本地模型参数计算梯度冲量并更新全局模型参数。
可选地,处理模块具体用于:
采用bmuf分布式算法对队列中来自不同worker进程的所有本地模型参数求平均,获得当前更新周期内所有worker进程共同训练出的平均模型参数;
计算ps自身存储的全局模型参数和获得的平均模型参数的差值,作为周期梯度(blockgradients);
将梯度冲量momentum以周期冲量率(blockmomentumrate)为权重累加到blockgradients上;其中,梯度冲量的初始值在训练开始之初为0;
以周期学习率(blocklearningrate)为步长,将得到的blockgradients更新至全局模型参数,并将blockgradients累加在momentum中。
虽然本申请所揭露的实施方式如上,但所述的内容仅为便于理解本申请而采用的实施方式,并非用以限定本申请。任何本申请所属领域内的技术人员,在不脱离本申请所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本申请的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!