一种通用字符串相似性度量框架的构建方法与流程
本发明属于数据挖掘技术领域,具体涉及一种通用字符串相似性度量框架的构建方法。
背景技术:
字符串相似性度量是检测数据库中重复和字面形式相似的字符串的重要技术。至今已经提出了多种类型的度量标准,但是这些度量标准或较复杂、不易灵活地扩展,或在合并其他语义特征方面(如词缀)有局限性。
字符串相似性度量,也称为字符串距离度量,或简称字符串度量,通过匹配待比较的两个字符串来度量字符串之间的相似度(或距离)。字符串相似度度量在许多应用中得到了广泛的应用,例如记录链接、实体规范化、信息集成、本体对齐等。至今已经提出了许多字符串相似度度量方法,例如dicedistance,levenshteindistance,jarodistance,monge-elkandistance等。基于上述经典度量方法衍生的许多字符串相似度度量算法会在比较过程中包含更多的字符串特性以满足某些需求,例如jaro-winklerdistance和gotohoptimizessmith-watermandistance;词缀是字符串匹配比较的重要特征;它们不在字符串中的固定位置,但也包含特定的语义信息;因此,人们设计了许多复杂的数据结构希望在度量过程中包含词缀。
技术实现要素:
针对上述背景技术中的问题,本发明提出了一种通用字符串相似性度量框架的构建方法,其基于fellegi-sunter模型,构思合理、简单,它对特定领域中需要快速和灵活地纳入大量语义特征的字符串相似度测量系统的设计提供指导。
本发明的技术方案如下:
上述的通用字符串相似性度量框架的构建方法,其具体过程如下:
(1)设定x={x0,x1,x2,...}和y={y0,y1,y2,...}为需要比较的两个字符串总体,x和y中的元素xi和yj由字符序列
(2)将匹配或相似的集合m={(xi,yj);xi=yj,xi∈x,yj∈y}与不匹配集合n={(xi,yj);xi≠yj,xi∈x,yj∈y}组成的一组字符串x×y={(xi,yj);xi∈x,yj∈y};
(3)基于匹配或相似的集合m={(xi,yj);xi=yj,xi∈x,yj∈y}和不匹配集合n={(xi,yj);xi≠yj,xi∈x,yj∈y},为每个字符串相似性度量定义一个用于比较的标准集合γ(xi,yj),γ(xi,yj)={γ1(xi,yj),γ2(xi,yj),...,γk(xi,yj)},,其中γk(xi,yj)是xi和yj之间的第k个特定比较条件;
(4)得到后验概率p((xi,yj)∈m|γ(xi,yj))即字符串相似性度量的实际或准确结果后,再基于最大似然估计方法,使用p(γ(xi,yj)|(xi,yj)∈m)来估计后验概率,即:
sim(xi,yj)=p((xi,yj)∈m|γ(xi,yj))
∝p(γ(xi,yj)|(xi,yj)∈m)
设定γ(xi,yj)中的比较标准是i.i.d.,进一步得
其中
(5)最后得到一个结合附加特征的字符串相似性度量框架:
sim(xi,yj)=simgen(xi,yj)+α·(1-simgen(xi,yj)).。
所述通用字符串相似性度量框架的构建方法,其中:所述步骤(3)中的γk(xi,yj)可表示dice距离中xi和yj中的共同字符,也可表示在levenshtein距离和jaro距离中变换xi到yj的最小成本删除操作,还可表示在monge-elkan距离中的xi和yj的共同前缀。
所述通用字符串相似性度量框架的构建方法,其中:所述步骤(5)中为了包含词缀信息到字符串相似度度量中,可修改α为
有益效果:
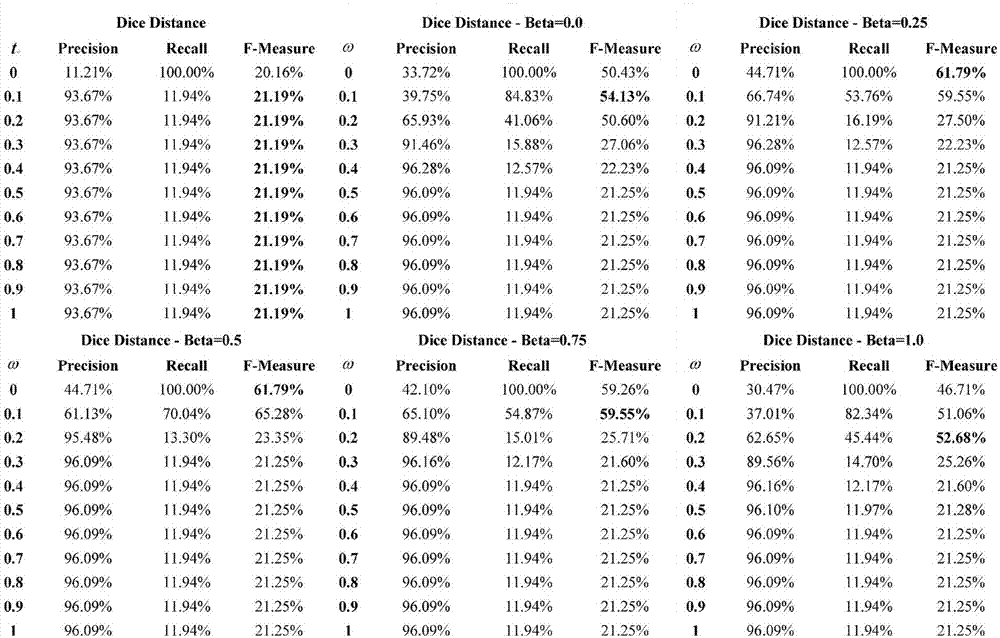
本发明通用字符串相似性度量框架的构建方法构思合理、简单,构建的通用字符串相似性度量框架可以对这些特征进行加权以满足特定的需求。图1至4显示了在不同的参数设置下,在通用字符串相似性度量框架中使用不同的字符串相似度度量所得到的结果;首先,它表明前缀和后缀是这种规范化任务的有用特征;其次,本发明可以将这些附加特征有效地结合到字符串相似性度量中;最后,图1至4也表明,由于本发明对调整所包含的词缀特征的权重(β和η)的灵活性,我们可以找到用于并入附加的词缀特征的最合适的加权策略,并且因此达到最佳归一化结果。
本发明通用字符串相似性度量框架的构建方法基于fellegi-sunter模型的简单灵活的概率框架,并通过一系列实验进行了仔细的验证,结果证明了框架的有效性,将对需要快速和灵活地纳入大量语义特征的字符串相似度测量系统的设计提供指导。
附图说明
图1为本发明一种通用字符串相似性度量框架的构建方法在不同的β(beta),η=(1-β),t和ω参数设置下,将dice距离放置在本发明通用字符串相似性度量方法的框架中得到的归一化结果图;
图2为本发明一种通用字符串相似性度量框架的构建方法在不同的β(beta),η=(1-β),t和ω参数设置下,将levenshtein距离放置在本发明通用字符串相似性度量方法的框架中得到的归一化结果;
图3为本发明一种通用字符串相似性度量框架的构建方法在不同的β(beta),η=(1-β),t和ω参数设置下,将jaro距离放置在本发明通用字符串相似性度量方法的框架中得到的归一化结果;
图4为本发明一种通用字符串相似性度量框架的构建方法在不同的β(beta),η=(1-β),t和ω参数设置下,将monge-elkan距离放置在本发明通用字符串相似性度量方法的框架中得到的归一化结果。
具体实施方式
本发明一种通用字符串相似性度量框架的构建方法,具体过程为:
(1)首先设定x={x0,x1,x2,...}和y={y0,y1,y2,...}为需要比较的两个字符串群,x和y中的元素xi和yj由字符序列
(2)其次,将匹配或相似的集合m={(xi,yj);xi=yj,xi∈x,yj∈y}与不匹配集合n={(xi,yj);xi≠yj,xi∈x,yj∈y}集合组成的一组字符串x×y={(xi,yj);xi∈x,yj∈y}。
(3)接着基于匹配或相似的集合m={(xi,yj);xi=yj,xi∈x,yj∈y}及不匹配集合n={(xi,yj);xi≠yj,xi∈x,yj∈y}集合,为每个字符串相似性度量定义一个用于比较的标准集合γ(xi,yj),γ(xi,yj)={γ1(xi,yj),γ2(xi,yj),...,γk(xi,yj)},,其中γk(xi,yj)是xi和yj之间的第k个特定相似性比较条件;
上述步骤(3)中γk(xi,yj)可表示dice距离中xi和yj中的共同字符,还可表示在levenshtein距离和jaro距离中变换xi到yj的最小成本删除操作,还表示在monge-elkan距离中的xi和yj的共同前缀等等,使γ(xi,yj)所有可能的实现可以形成比较标准空间γ。
(4)得到后验概率p((xi,yj)∈m|γ(xi,yj))即字符串相似性度量的实际或准确结果后,再基于最大似然估计方法(最大似然估计方法是写在专业教科书中已经公布的技术),使用p(γ(xi,yj)|(xi,yj)∈m)来估计后验概率,即:
sim(xi,yj)=p((xi,yj)∈m|γ(xi,yj))
∝p(γ(xi,yj)|(xi,yj)∈m)
假设γ(xi,yj)中的比较标准是i.i.d.,可以进一步得
其中
(5)将附加的特征合并到字符串相似性度量中
sim(xi,yj)=simgen(xi,yj)+α·(1-simgen(xi,yj)).
上述步骤(5)为了包含词缀信息(例如前缀特征和后缀特征)到字符串相似度度量中,可以简单地修改α为
在图1至4中,可以看到,将相似度阈值t从0改为1,通过使用不同的一般字符串相似度量度而获得的归一化结果的降序是monge-elkandistance>jarodistance>levenshteindistance>dicedistance;试验结果表明更多的附加语义特征被纳入将取得更好的结果。
通过在每个一般字符串相似性度量的最佳t设置下改变β、η=(1-β)和ω设置,当将上述dicedistance等四个字符串相似度度量方法放入所提出的框架中时,结果总是好于仅使用一般字符串相似性度量来进行临床症状名称归一化。
首先,表明前缀和后缀是这种规范化任务的有用特征;其次,所提出的框架可以将这些附加特征有效地结合到一般的字符串相似性度量中;最后,图1至4也表明,由于所提出的框架对调整所包含的词缀特征的权重(β和η)的灵活性,可以找到用于并入附加的词缀特征的最合适的加权策略,并且因此达到最佳归一化结果。
为了评估所提出的框架,根据四个字符串相似性度量的优点和缺点,我们直接将它们放入公式sim(xi,yj)=simgen(xi,yj)+α·(1-simgen(xi,yj)).中,并将α修改为公式
然后将其应用于临床症状名称归一化任务。根据行业知识,前缀和后缀是这个任务的有用特性。我们使用的实验数据集包含4465个独特的临床症状名称和947个独特的标准症状名称。任务是用947个标准症状名称标准化每个临床症状名称。我们使用精度(precnorm),召回率(recnorm)和f-measure(fmnorm)三个指标评估标准化结果:
precnorm=|cns|/|ns|,;
recnorm=|cns|/|csn|,;
上述公式中,|cns|是临床症状名称正确标准化的数量,|ns|是标准化的临床症状的总数。|csn|是将要标准化的临床症状名称的数量。
本发明基于fellegi-sunter模型,构思合理,能将对需要快速和灵活地纳入大量语义特征的字符串相似度测量系统的设计提供指导。
- 还没有人留言评论。精彩留言会获得点赞!