基于朴素贝叶斯的案件文本分类方法、系统和存储介质与流程
本发明涉及数据挖掘领域,尤其是一种基于朴素贝叶斯的案件文本分类方法、系统和存储介质。
背景技术:
文本分类方法是一种有监督的分类方法,它用一个已标好类别的文本数据集来训练分类器,然后用训练好的分类器对未标识类别的文本进行分类,常用的分类算法有朴素贝叶斯方法、k-近邻方法、支持向量机方法等,其中,朴素贝叶斯分类方法是目前公认的一种简单有效的分类方法,并且它在文本分类领域表现出令人满意的性能。但是公安的案件文本具有类别分布不均衡的特点,即训练集各个类别所包含的文本数目差异较大的特点,故本发明提出了改进的朴素贝叶斯方法进行案件文本分类。
技术实现要素:
为了解决上述技术问题,本发明提出了一种针对案件文本的基于朴素贝叶斯的案件文本分类方法、系统和存储介质。
本发明所采取的第一种技术方案是:
一种基于朴素贝叶斯的案件文本分类方法,包括以下步骤:
基于朴素贝叶斯算法构建分类器;
获取训练样本对分类器进行训练,计算各个类别的先验概率以及每个特征词属于各个类别的先验概率;
获取待分类文本;
对待分类文本进行预处理,得到待分类文本的文本向量;
将所述文本向量输入到分类器,根据各个类别的先验概率以及每个特征词属于各个类别的先验概率,计算待分类文本属于各个类别的后验概率;
以后验概率最高的类别作为分类结果输出。
进一步,所述后验概率的计算公式为:
其中,p(cj|d)表示待分类的文本d属于分类cj的后验概率;p(cj)表示分类cj的先验概率;p(wi|cj)表示特征词wi属于分类cj的先验概率,wi是文本文件d进行分词处理后特征词集合中的元素。
进一步,所述p(wi|cj)的计算公式为:
其中,|c|表示类别的总数,|d|表示分类cj总的文本数量,|dmax|表示最大的类别文档总数,b为加权系数。
进一步,所述对待分类文本进行预处理,得到待分类文本的文本向量,其具体包括:
对待分类文本进行分词处理,得到特征词集合;
用卡方检验在特征词集合中进行特征词选择;
根据特征词选择的结果,构建文本向量。
进一步,所述用卡方检验在特征词集合中进行特征词选择,其具体包括:
计算特征词集合中每个特征词的卡方统计量;
选取卡方统计量最高的前k个特征词作为特征词选择的结果;
其中,k为设定的正整数。
进一步,所述卡方统计量的计算公式为:
其中,χ2(wi,cj)表示特征词wi对于类别cj的卡方统计量;n表示所有的文本数量;a表示包含特征词wi且属于类别cj的文本数量;b表示包含特征词wi且不属于类别cj的文本数量;c表示不包含特征词wi且属于类别cj的文本数量;d表示不包含特征词wi且不属于类别cj的文本数量。
进一步,所述根据特征词选择的结果,构建文本向量,其具体包括:
将特征词选择的结果中的每一个特征词作为向量空间中的一个维度;
计算每一个维度对应的特征词的权重值,得到文本向量;
所述权重值的计算公式为:
idf=log(d1/dt);
其中,idf表示特征词的权重值;d1表示文本总数;dt表示包含该特征词的文本数量。
本发明所采取的第二种技术方案是:
一种基于朴素贝叶斯的案件文本分类系统,包括:
构建模块,用于基于朴素贝叶斯算法构建分类器;
训练模块,用于获取训练样本对分类器进行训练,计算各个类别的先验概率以及每个特征词属于各个类别的先验概率;
获取模块,用于获取待分类文本;
数据处理模块,用于对待分类文本进行预处理,得到待分类文本的文本向量;
分类模块,用于将所述文本向量输入到分类器,根据各个类别的先验概率以及每个特征词属于各个类别的先验概率,计算待分类文本属于各个类别的后验概率;并以后验概率最高的类别作为分类结果输出。
本发明所采取的第三种技术方案是:
一种基于朴素贝叶斯的案件文本分类系统,包括
存储器,用于存储程序;
处理器,用于加载所述程序以执行一种基于朴素贝叶斯的文本分类方法。
本发明所采取的第四种技术方案是:
一种存储介质,所述存储介质上存储有程序,所述程序被处理器执行时实现一种基于朴素贝叶斯的文本分类方法。
本发明的有益效果是:本发明基于朴素贝叶斯算法构建分类器,并且对分类器进行了改进,在训练过程中,先计算各个类别的先验概率以及每个特征词属于各个类别的先验概率,然后根据各个类别的先验概率以及每个特征词属于各个类别的先验概率,计算待分类文本属于各个类别的后验概率;本发明的分类器充分考虑了不同类别之间样本数量的差异性,将各个类别的先验概率以及每个特征词属于各个类别的先验概率作为分类器的计算因子,使得本发明对案件文本分类具有更好的分类效果。
附图说明
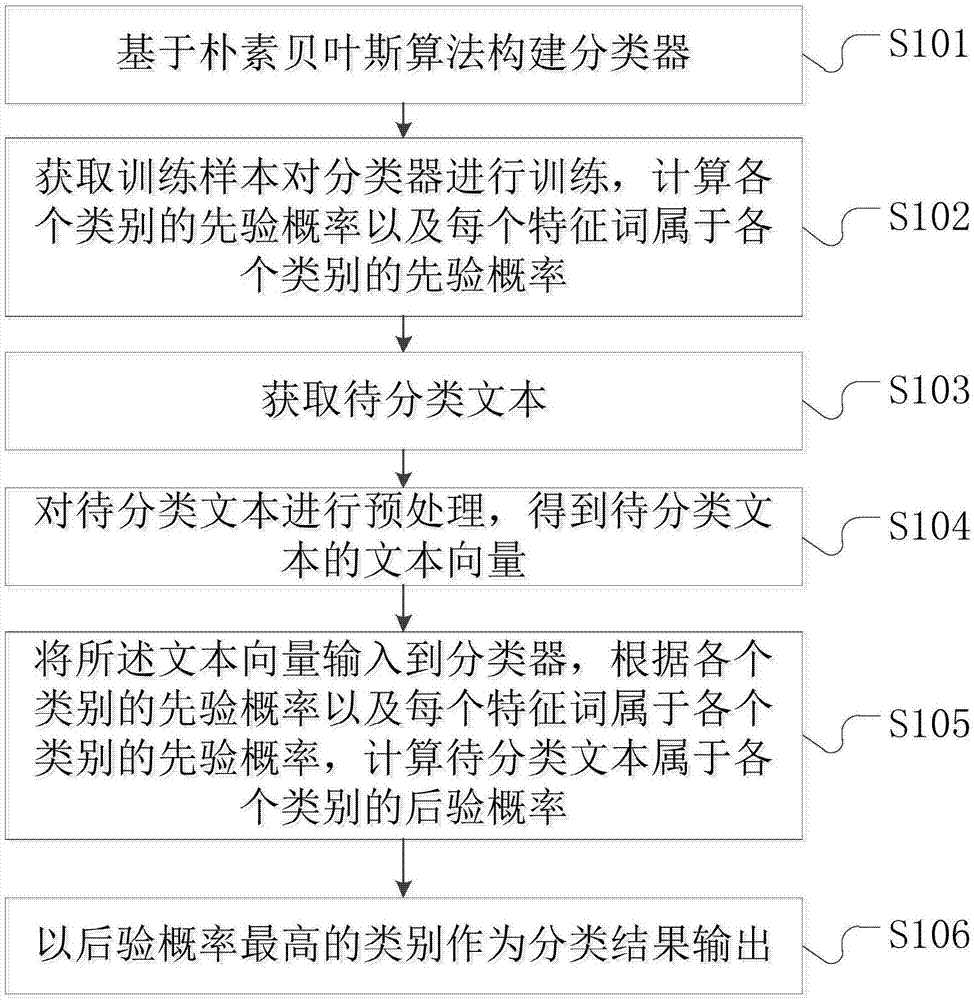
图1为本发明一种基于朴素贝叶斯的案件文本分类方法的流程图。
具体实施方式
下面结合说明书附图和具体的实施例对本发明进行进一步的说明。
参照图1,一种基于朴素贝叶斯的案件文本分类方法,包括以下步骤:
s101、基于朴素贝叶斯算法构建分类器。
s102、获取训练样本对分类器进行训练,计算各个类别的先验概率以及每个特征词属于各个类别的先验概率。训练样本可以是经过处理的训练样本,也可以是未经处理的训练样本,若采用未经处理的训练样本,则需要通过步骤s104对训练样本也进行预处理。
s103、获取待分类文本。待分类文本是原文,未经处理,因此在步骤s104需要对其进行处理。
s104、对待分类文本进行预处理,得到待分类文本的文本向量。本步骤主要对待分类文本的特征词进行提取,由于提出的特征词比较多,需要对特征词集合进行降维,筛选出比较重要的特征词。
s105、将所述文本向量输入到分类器,根据各个类别的先验概率以及每个特征词属于各个类别的先验概率,计算待分类文本属于各个类别的后验概率。
s106、以后验概率最高的类别作为分类结果输出。
作为优选的实施例,所述后验概率的计算公式为:
其中,p(cj|d)表示待分类的文本d属于分类cj的后验概率;p(cj)表示分类cj的先验概率;p(wi|cj)表示特征词wi属于分类cj的先验概率,wi是文本文件d进行分词处理后特征词集合中的元素。本实施例的计算方式充分考虑了案件文本不同类别的样本数量的差异性,将分类的先验概率作为计算因子,能够对案件文本起到更好的分类效果。
作为优选的实施例,所述p(wi|cj)的计算公式为:
其中,|c|表示类别的总数,|d|表示分类cj总的文本数量,|dmax|表示最大的类别文档总数,b为加权系数。设置加权系数b的主要作用是为了避免在运算过程中,出现p(wi|cj)为零的情况,导致程序崩溃。
所述加权系数b可以采用以下函数得到,
作为优选的实施例,所述步骤s104,具体包括:
s1041、对待分类文本进行分词处理,得到特征词集合。本步骤包括中文分词和去除停用词。本步骤可以采用中科院的ictclas分词系统实现,ictclas分词系统充分利用了词典匹配、统计分析这两种分词方法的优点,既能发挥词典匹配法分词速度快、效率高的特点,又能利用统计分析法结合上下文识别新词、消除歧义的优点。该分词系统具有词性标注功能。在本实施例中,还根据公安领域特征对加入公安专业词汇。由于公安领域的很多词汇如“故意伤害”、“使用假证”、“非法持有假币”等词在案件文本中出现频繁,具有语义特征,但是分词组件却无法精确切分出这些词。因此,可对该分词进行改进,建立针对公安领域的专业词汇的词库。将自定义词库的词加载到分词组件中去,有效地改进分词的效果。
去除停用词一般是指去除文本中出现频率很高,但实际意义又不大的词,如常见的“的”、“在”、“和”、“接着”、“了”、“还是”和“或者”等,还有一些是使用过于频繁的单词,如“我”、“就”、“啊”和“吧”等等,以及各种的标点符号,避免分词后有过多的干扰。去除这些词可以降低特征词的维度,同时可以提高文本挖掘效果。
此外,根据词性剔除对案件中无用的词;一个案件文本主要包含以下信息作案时间、作案地点、涉案人、作案手段、作案工具、损失物品和损失金额等。根据分词的词性标注信息,剔除与案件属性无关的词性,如拟声词、副词、介词和连词等。
s1042、用卡方检验在特征词集合中进行特征词选择。
案件文本具有文本短小,包含大量案件细节信息的特征。除此之外,案件文本类别具有在一定区域内的不同时期,某一案件类别所包含的文本数占该时期总文本数的比例基本接近、各类别文本数目分布比例不均衡等特点。
文本预处理后以特征词集合的形式存在,此时特征词集合中的特征词数量非常的多,需要对特征词集合进行降维处理,即特征词选择。本实施例采用卡方检验进行特征词选择。所述卡方检验为:假设特征词wi和类别cj之间符合一阶自由度的卡方分布,特征词wi对于类别cj的卡方统计量χ2越高,则特征词wi和类别cj的相关性就越强,类别区分度越大;反之,其类别区分度就越小。因此采用卡方检验,能够对案件文本提取的特征词集合进行有效的降维,提升降维处理的有效性。
s1043、根据特征词选择的结果,构建文本向量。
作为优选的实施例,所述步骤s1042包括:
s10421、计算特征词集合中每个特征词的卡方统计量;
s10422、选取卡方统计量最高的前k个特征词作为特征词选择的结果;
其中,k为设定的正整数。
作为优选的实施例,所述卡方统计量的计算公式为:
其中,χ2(wi,cj)表示特征词wi对于类别cj的卡方统计量;n表示所有的文本数量;a表示包含特征词wi且属于类别cj的文本数量;b表示包含特征词wi且不属于类别cj的文本数量;c表示不包含特征词wi且属于类别cj的文本数量;d表示不包含特征词wi且不属于类别cj的文本数量。
作为优选的实施例,所述步骤s1043具体包括:
s10431、将特征词选择的结果中的每一个特征词作为向量空间中的一个维度;
s10432、计算每一个维度对应的特征词的权重值,得到文本向量;
所述权重值的计算公式为:
idf=log(d1/dt);
其中,idf表示特征词的权重值;d1表示文本总数;dt表示包含该特征词的文本数量。
在海量公安案件情报信息中,除了规范化程度很强的数据库数据外,还有大量的案件叙述性文本描述,例如:案件卷宗、案件口供、审讯笔录、报警内容或简要案情等,采用本发明构建的一种基于朴素贝叶斯的文本分类方法,对大量的案件叙述性文本进行标签分类,实现非结构的案件文本情报信息的分析挖掘,迅速有效地从案件文本信息中发现有价值的情报信息,有效提升公安案件刑侦、精确防控和精确打击能力。
本实施例公开了一种与图1中方法对应的基于朴素贝叶斯的案件文本分类系统,包括:
构建模块,用于基于朴素贝叶斯算法构建分类器;
训练模块,用于获取训练样本对分类器进行训练,计算各个类别的先验概率以及每个特征词属于各个类别的先验概率;
获取模块,用于获取待分类文本;
数据处理模块,用于对待分类文本进行预处理,得到待分类文本的文本向量;
分类模块,用于将所述文本向量输入到分类器,根据各个类别的先验概率以及每个特征词属于各个类别的先验概率,计算待分类文本属于各个类别的后验概率;并以后验概率最高的类别作为分类结果输出。
本实施例公开了一种基于朴素贝叶斯的案件文本分类系统,包括
存储器,用于存储程序;
处理器,用于加载所述程序以执行一种与图1中方法对应的基于朴素贝叶斯的文本分类方法。
本实施例公开了一种存储介质,所述存储介质上存储有程序,所述程序被处理器执行时实现一种与图1中方法对应的基于朴素贝叶斯的文本分类方法。
对于上述方法实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
以上是对本发明的较佳实施进行了具体说明,但本发明并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!