一种基于GRU神经网络的中文评论情感分析法的制作方法
本发明涉及一种基于gru(循环单元)神经网络的中文评论情感分析法,属于自然语言处理及深度学习领域。
背景技术:
情感分类技术是指将用户在评论文本中表达的情感信息进行识别分类,在一般情况下将其分为正类和负类。对于赞美和肯定的情感分为正类,对于批评和否定的情感分为负类。情感分类技术主要有两种方式:第一种是利用情感词典的无监督分类方法,第二种是基于机器学习的有监督分类方法。因为基于机器学习方法的情感分类能够得到更加出色的分类效果,所以成为了主流方法。2002年,pang等科研人员首次将机器学习的方法应用于情感分类领域。他们尝试使用n-grame模型提取出特征,并且分别利用机器学习领域的3种分类模型(nb(朴素贝叶斯分类模型)、me(模幂运算分类模型)和svm(支持向量机分类模型))进行了测试。发现利用unigrams(一元模型)作为特征集合,使用svm进行最终分类,可以获得较好的分类效果。而2006年通过cui等实验表明,当语料较少时unigrams可以获得较好效果。但语料库增长,n-grams(n>3)确表现出了更好分类性能。
随着n-grams(n元模型)的n取值不断增大造成了数据量的爆炸增长,使得正常情况下n取在3左右,不能更多的提炼中间词与周边词的联系。
怎样抽取出复杂特征而非简单特征以及识别出哪种类型的特征是有价值的,是目前研究的两个主要问题。近些年来出现了许多方法,主要有single-charaxtern-grams(多特征n元模型)模型,multi-wordn-grams(多特征词n元模型)模型和词汇-句法模型等。ahmed等在2011年提出了基于规则的多元文本特征选择方法frn(featurerelationnetwork特征关系网)。yao等用统计的机器学习的方法来选择特征,降低了特征向量的维度。其他还有采用df(documentfrequency文档频率法)、ig(informationgain信息增益)、chi(chisquaredstatistic卡方统计法)和mi(mutualinformation互信息法)来选取特征。
mikolov等人于2011年提出了一种rnnlm(递归神经网络的语言模型),从而解决了变长序列的问题。但是即便是在百万量级的数据集上,即便是借助了40个cpu进行训练,耗时数周才能给出一个很好的解来。训练一个nnlm(神经网络语言模型)几乎是一个不可能的事情。2013年mikolov对nnlm进行了改进,2013年于google开源了一款用于词向量计算的工具——word2vec。
gru神经网络单元是2014年由cho等人基于lstm(长短期记忆网络)变形而来,gru与lstm的区别在于使用同一个门限来代替输入门限和遗忘门限,该做法的好处是计算得以简化,同时表达能力也得到提升,所以gru也因此越来越流行。
传统方法都限于挖掘句子中词与词之间的词汇特征及句法特征,而在语言中往往蕴含词语之间的隐含信息及语义特征,会对感情信息的识别起到很大作用。对于感情表示准确的语句来说大多方法可以精准识别,但对于一些带有反讽(过度赞扬达到批评目的)色彩的评论却无法准确识别。因为这类方法只能对不同词特征进行分类无法提取出句子中隐含的情感表达。对于现在更加个性化的年轻人而言,评论也越来越多样化。这是未来分类与处理的难题。
技术实现要素:
本发明提出了一种基于gru神经网络的中文评论情感分析法,利用word2vec(词向量生成模型)先训练语料的词语向量,计算词语间的余弦距离进行聚类,通过相似特征的聚类方法将高相似度领域词汇扩充到词典。利用扩充词典作为评论语句词向量生成器将评论语句转化为语句向量,然后word2vec进行训练生成相应的特征向量。
本发明为解决其技术问题采用如下技术方案:
一种基于gru神经网络的中文评论情感分析法,包括如下步骤:
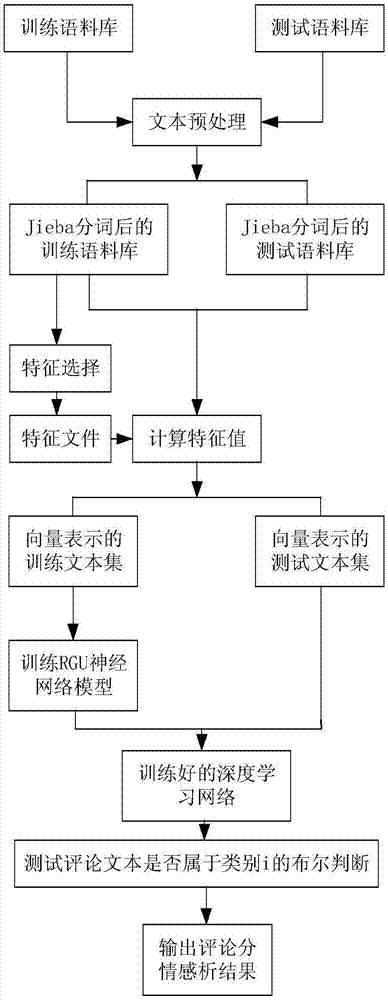
(1)先将语料数据载入,利用jieba分词工具进行分词;
(2)去除一些无用的暂停词并将语料按比例分割为训练集和测试集;
(3)利用word2vec训练语料的词语向量,对每个句子的所有词向量取均值,来生成对应句子的向量,然后利用word2vec模型网络进行反向传播训练最终计算生成相应的词向量;
(4)将word2vec生成的带有句子情感的词向量输入gru神经网络模型进行训练;
(5)测试集按照训练集方法构建,输入gru神经网络进行情感分类。
步骤(1)中所述语料数据为国内知名网站京东上的用户评论,训练语料集11w条电子、生活类评论语句。
所述语料数据分为正类和负类。
所述语料数据分割成训练集和测试集。
所述训练集和测试集比例为5:1。
本发明的有益效果如下:
1、本发明利用基于gru神经网络的分类模型来进行情感分类,在获得不错效果的同时模型速度上也有显著提升。
2、word2vec和gru可以很好地完成中文文本感情分类的任务。虽然gru模型训练的准确信不能完全超过其他深度学习方法。但是在训练测试所耗时间上有着一定的提升。所以基于gru神经网络的中文评论情感模型的方法表现出了足够优越的性能。
附图说明
图1为一种基于gru神经网络的中文评论情感分析法流程图。
图2为gru单元内部结构图。
具体实施方式
下面结合附图对本发明创造做进一步详细说明。
如图1所示方法先将语料数据载入,利用jieba(中文分词工具)分词工具进行分词,然后去除一些无用的暂停词并将语料按一定比例分割为训练集和测试集。为了提取词与词之间的语义特征,对词句分类判断能力的加强。本专利利用word2vec训练语料的词语向量,对每个句子的所有词向量取均值,来生成对应句子中词的词向量,然后利用word2vec模型网络进行反向传播训练最终计算生成相应的低维词向量。将word2vec生成的带有句子情感的词向量输入gru神经网络模型进行训练。将测试集按照上述方法构建,输入gru神经网络进行情感分类。
一种基于gru神经网络的中文评论情感分析方法。方法采用word2vec训练出每个词的词向量,计算向量之间的余弦来判断向量的相似度从而获得文本语义上的相似度。将这些相似度高的词做聚类处理。通过对训练语料集进行相似特征词处理,再将其添加进情感词典之中达到扩充情感词典的效果。再利用word2vec对训练语料集训练得到单词的向量表示,使用这个表示作为词向量特征数学化表示。这种表示揭示出特征值之间的隐性语义。通过这种方式将特征词匹配转换为向量形式的值。通过gru神经网络模型进行训练测试从而完成一个模型的设计。其具体步骤如下:
第一步:word2vec训练需要文本语料做支撑,训练语料库越丰富,其训练效果就会越好不过目前国内并没有一个相对完备的公开实验数据集给研究者做测试,因此在进行实验之前,需要从互联网上获取大量的用户评论。将训练集数据进行了分类,按星级划分4、5星评论为正类,1、2星评论为负类。本申请利用的是国内知名网站京东上的用户评论,训练语料集11w条电子、生活类评论语句,进行分类操作后,训练集大概正负比例为5:2(经过人为压缩筛选),数据相对平衡。同时将语料库分割成训练集和测试集,比例为5:1。
第二步:利用jieba分词程序对所收集的电子类、生活类商品评论语料进行分词和词性标注,去除语料中的标点各种表情符号和各种火星文等符号。加载停用词语料进行去除停用词,使用word2vec对语料进行训练,得到相应模型文件。在windows平台下利用anaconda3(开源的python发行版本)配置相应的python(程序语言)环境,安装使用gensim(文档语义结构的工具)模块调用其模块下的word2vec进行训练,相应的参数设置为:隐藏层数:1,迭代次数:400,批尺寸:20,损失函数:交叉熵,下降方式:随机梯度下降法,学习率:0.0001,权值初始方法:正交初始化,弃权系数:0.2。
训练完成,文件保存为词语与向量对应的文件。使用word2vec模块下的最大相似函数进行相似度计算,实现词语之间相似度的比较,继而达到聚类的目的。通过对训练语料集进行相似特征词处理,再将其添加进情感词典之中达到扩充情感词典。
第三步:利用word2vec对训练语料集训练得到单词的特征向量表示,使用这个表示作为词向量特征数学化表示。word2vec是利用深度学习的一种词与向量转换方法,它是一种浅层的神经网络。使用n维度的向量运算来对文本的内容进行表示,用一个三层的神经网络来对语言模型进行建模,获得单词的向量表示,使用这个表示作为特征数学化数字表示。同时揭示出特征值之间的隐性语义。通过这种方式将特征词匹配转换为向量形式的值。
第四步:将生成的词特征向量输入gru神经网络模型进行训练测试。gru是lstm中的一种变种,通过在隐藏层简单节点之间加入链接,用循环单元控制隐藏神经元的输出,可以有效建模时间序列上的变化。
传统lstm一般由多个门组成:忘记门、记忆门、忘记门和记忆门组合即成为一个更新门、输出门组成,可以使模型丢弃一些无用信息,所以得到广泛使用。如图2所示gru在此基础上将忘记和记忆窗口合并,所以由更新门和重置门组成,更新门对于时间步t,我们首先需要使用以下公式(1)计算更新门zt:
zt=σ(w(z)xt+u(z)ht-1)(1)
其中xt为第t个时间步的输入向量,即输入序列x的第t个分量,它会经过一个线性变换(与权重矩阵w(z)相乘)。ht-1保存的是前一个t-1时间步的信息。u(z)为更新矩阵,σ为重置函数。更新门将这两部分信息相加并投入到sigmoid激活函数中,因此将激活结果压缩到0到1之间。更新门帮助模型决定到底要将多少过去的信息传递到未来。重置门本质上来说决定了到底要将多少过去的信息需要遗忘,使用以下表达式计算:
rt=σ(w(r)xt+u(r)ht-1)(2)
其中:rt为重置门存储信息,w(r)为权重矩阵,u(r)为更新矩阵,
公式(2)中ht-1和xt先经过一个线性变换,再相加投入sigmoid激活函数以输出激活值。最后就是输出的问题更新门和重置门到底如何影响最终输出的。在重置门的使用中,新的记忆内容将使用重置门储存过去相关的信息,它的计算表达式为:
ht′=tanh(wxt+rt⊙uht-1)(3)
其中:ht′为当前时间信息,w为权重矩阵,u为更新矩阵,tanh为非线性变换函数,⊙为hadamard乘积,
公式(3)输入xt与上一时间步信息ht-1先经过一个线性变换,即分别右乘矩阵w和u。计算重置门r与uht-1的hadamard乘积,即rt与uht-1的对应元素乘积。因为前面计算的重置门是一个由0到1组成的向量,它会衡量门控开启的大小。该hadamard乘积将确定所要保留与遗忘的以前信息。最后一步网络需要计算ht,该向量将保留当前单元的信息并传递到下一个单元中。在这个过程中,我们需要使用更新门,它决定了当前记忆内容h′和前一时间步ht-1中需要收集的信息是什么。这一过程可以表示为:
ht=zt⊙ht-1+(1-zt)⊙ht′(4)
其中:ht为时间信息,
公式(4)zt为更新门的激活结果,它同样以门控的形式控制了信息的流入。zt与ht-1的hadamard乘积表示前一时间步保留到最终记忆的信息,该信息加上当前记忆保留至最终记忆的信息就等于最终门控循环单元输出的内容。
gru神经网络模型的超参数有:句子处理尺寸,词向量维数,隐藏层节点,dropout(丢弃率)分别为20,80,200,0.15对于输入窗口分为左右双边,左边窗口设置为0,右窗口设置为3。将t到t+4的四个字符同时输入。通过gru神经网络模型进行训练测试是模型不断完善得到一个理想的模型。
- 还没有人留言评论。精彩留言会获得点赞!