场所之间关联度的评估方法和评估系统与流程
本发明涉及大数据技术领域,特别涉及一种场所之间关联度的评估方法和评估系统。
背景技术:
研究不同场所之间的关联性,建立场所之间的关联网,是大数据研究领域的热门方向。然而,当前对场所之间关联度的评估主要是依据人为主观感受,没有相应的数据支撑。为此,提供一种相对客观、
能够真实反映场所之间关联度的评估方法,是本领域亟需解决的技术问题。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题之一,提出了一种场所之间关联度的评估方法和评估系统。
为实现上述目的,本发明提供了一种场所之间关联度的评估方法,包括:
获取在预设时间段内各场所对应的用户信息,所述用户信息包括:在所述预设时间段内在对应的所述场所出现过的各用户的身份信息和各用户对应的出现频数;
根据各所述场所对应的所述用户信息,评估任意两个所述场所之间的关联度。
可选地,所述预设时间段包括:若干个统计周期;
所述获取在预设时间段内各场所所对应的用户信息的步骤包括:
在每一个统计周期内,针对每一个场所,获取在该统计周期内出现于该场所的各用户的所述身份信息,并将相应用户在该统计周期内出现于该场所的出现频数记为1;
针对每一个场所,统计出在预设时间段内出现于该场所的各用户的身份信息和各用户对应的出现频数。
可选地,所述身份信息包括:相应用户所携带的移动终端的mac地址;
所述获取在该统计周期内出现于该场所的各用户的身份信息的步骤包括:
在该统计周期内,实时扫描位于该场所内的全部所述移动终端的mac地址,并将扫描到的mac地址作为相应用户的身份信息。
可选地,所述根据各所述场所对应的所述用户信息,评估任意两个所述场所之间的关联度步骤包括:
以出现频数作为特征,根据各所述场所对应的所述用户信息,生成各所述场所的特征向量;
计算待评估的两个所述场所的特征向量之间的相似度,以作为该待评估的两个所述场所之间的关联度。
可选地,所述场所的个数为j,j个所述场所对应j个所述用户信息;
所述根据各所述场所的所述用户信息,生成各所述场所的特征向量的步骤包括:
从j个所述用户信息中,剔除仅在一个所述场所中出现过的用户的所述身份信息和该用户对应的出现频数;完成数据剔除后,j个所述用户信息中总计包括i个不同用户的身份信息;
以j个不同场作为j个文件,i个用户作为i个词,采用tf-idf算法提取各场所的特征向量,具体包括:
计算各用户在各场所对应的词频:
其中,tfi,j表示第i个用户在第j个场所的词频,ni,j表示在预设时间段内第i个用户在第j个场所的出现频数,i∈[1,i]且i为整数,j∈[1,j]且j为整数;
计算各用户的逆向文件频率:
其中,idfi表示第i个用户对应的逆向文件频率,dj表示第j个场所,|j:ti∈dj|表示在预设时间段内出现过第i用户的场所的总数量;
计算各用户在各场所对应的权重评分:
tfidfi,j=tfi,j×idfi
其中,tfidfi,j表示第i个用户在第j个场所的权重评分;
生成各场所的特征向量:
aj=(tfidf1,j,tfidf2,j,...,tfidfi,j)
其中,aj表示第j个场所的特征向量。
可选地,所述计算待评估的两个所述场所的特征向量之间的相似度的步骤包括:
计算待评估的两个所述场所的特征向量之间的距离,并将计算结果作为待评估的两个所述场所的特征向量之间的相似度。
为实现上述目的,本发明还提供了一种场所之间关联度的评估系统,包括:
获取模块,用于获取在预设时间段内各场所对应的用户信息,所述用户信息包括:在所述预设时间段内在对应的所述场所出现过的各用户的身份信息和各用户对应的出现频数;
评估模块,用于根据各所述场所对应的所述用户信息,评估任意两个所述场所之间的关联度。
可选地,所述预设时间段包括:若干个统计周期;
所述获取模块包括:
获取单元,用于在每一个统计周期内,针对每一个场所,获取在该统计周期内出现于该场所的各用户的所述身份信息,并将相应用户在该统计周期内出现于该场所的出现频数记为1;
统计单元,用于针对每一个场所,统计出在预设时间段内出现于该场所的各用户的身份信息和各用户对应的出现频数。
可选地,所述身份信息包括:相应用户所携带的移动终端的mac地址;
所述获取单元包括:与所述场所一一对应的若干个扫描子单元;
所述扫描子单元用于在统计周期内实时扫描位于对应场所内的全部所述移动终端的mac地址,并将扫描到的mac地址作为相应用户的身份信息。
可选地,所述评估模块包括:
特征向量生成单元,用于以出现频数作为特征,根据各所述场所对应的所述用户信息,生成各所述场所的特征向量;
计算单元,用于计算待评估的两个所述场所的特征向量之间的相似度,以作为该待评估的两个所述场所之间的关联度。
可选地,所述场所的个数为j,j个所述场所对应j个所述用户信息;
所述特征向量生成单元包括:
数据剔除单元,用于从j个所述用户信息中,剔除仅在一个所述场所中出现过的用户的所述身份信息和该用户对应的出现频数;完成数据剔除后,j个所述用户信息中总计包括i个不同用户的身份信息;
特征向量提取单元,用于以j个不同场作为j个文件,i个用户作为i个词,采用tf-idf算法提取各场所的特征向量;
所述特征向量提取单元包括:
第一计算子单元,用于计算各用户在各场所对应的词频:
其中,tfi,j表示第i个用户在第j个场所的词频,ni,j表示在预设时间段内第i个用户在第j个场所的出现频数,i∈[1,i]且i为整数,j∈[1,j]且j为整数;
第二计算子单元,用于计算各用户的逆向文件频率:
其中,idfi表示第i个用户对应的逆向文件频率,dj表示第j个场所,|j:ti∈dj|表示在预设时间段内出现过第i用户的场所的总数量;
第三计算子单元,用于计算各用户在各场所对应的权重评分:
tfidfi,j=tfi,j×idfi
其中,tfidfi,j表示第i个用户在第j个场所的权重评分;
生成子单元,用于生成各场所的特征向量:
aj=(tfidf1,j,tfidf2,j,...,tfidfi,j)
其中,aj表示第j个场所的特征向量。
可选地,所述计算单元包括:
距离计算子单元,用于计算待评估的两个所述场所的特征向量之间的距离,并将计算结果作为待评估的两个所述场所的特征向量之间的相似度。
本发明具有以下有益效果:
本发明的提供了一种场所之间关联度的评估方法和评估系统,本发明的技术方案以场所的用户信息作为数据支撑,能够客观、准确的对场所之间关联度进行评估和量化,便于后续作进一步的分析。
附图说明
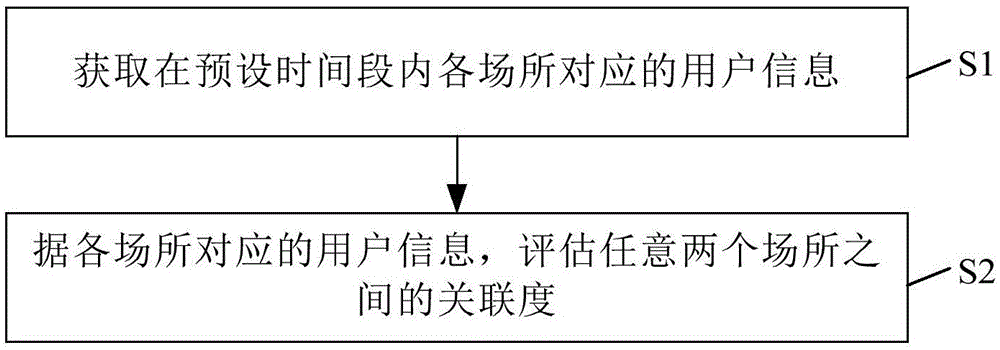
图1为本发明实施例一提供的一种场所之间关联度的评估方法的流程图;
图2为本发明实施例二提供的一种场所之间关联度的评估方法的流程图;
图3为本发明实施例三提供的一种场所之间关联度的评估系统的结构示意图。
具体实施方式
为使本领域的技术人员更好地理解本发明的技术方案,下面结合附图对本发明提供的一种场所之间关联度的评估方法和评估系统进行详细描述。
在本发明中,“场所”可以为预先定义的区域,例如将一间房子所对应的区域作为一个场所,将一个学校所对应的区域作为一个场所,将一个行政区作为一个场所。“用户”具体指代人。
若在某一段时间内,某一个用户频繁多次出现于两个不同的区域,则可在一定程度上反映出这两个区域存在一定的关联性。基于上述原理,本发明提供了一种场所之间关联度的评估方法和评估系统。
图1为本发明实施例一提供的一种场所之间关联度的评估方法的流程图,如图1所示,该场所之间的关联度的评估方法包括:
步骤s1、获取在预设时间段内各场所对应的用户信息。
其中,用户信息包括:在预设时间段内在对应的场所出现过的各用户的身份信息和各用户对应的出现频数。
在步骤s1中,在预设时间段内,针对每一个场所,获取出现于该场所的全部用户的身份信息,以及各用户对应的出现频数,从而得到该场对应的用户信息;该用户信息可在一定程度表征出对应场所的特点。
步骤s2、根据各场所对应的用户信息,评估任意两个场所之间的关联度。
在步骤s2中,由于场所对应的用户信息可表征出该场所的特点,因此基于场所对应的用户信息,可对场所之间的关联度进行评估。
本发明提供的场所之间关联度的评估方法,以用户信息作为数据支撑,能够客观、准确的对场所之间关联度进行评估。
图2为本发明实施例二提供的一种场所之间关联度的评估方法的流程图,如图2所示,本实施例为基于实施例一中所示评估方法的一种具体化方案,具体包括:
步骤s101、在每一个统计周期内,针对每一个场所,获取在该统计周期内出现于该场所的各用户的身份信息,并将相应用户在该统计周期内出现于该场所的出现频数记为1。
在步骤s101中,若在一个统计周期内检测到某个用户至少一次出现在某场所,则在该统计周期内该用户在该场所的出现频率记为1。当然,在一个统计周期内,一个用户可在不同时刻出现在两个、甚至多个不同场所,则在该统计周期内该用户在其所出现的各场所对应的出现频率均记为1。
在本实施例中,预设时间段预先划分为若干个统计周期。例如,预设时间段为180天,1天为1个统计周期,预设时间段划分为180个统计周期。需要说明的是,预设时间段的时长和统计周期的时长可根据实际需要进行设定、调整。
其中,可选地,身份信息包括:相应用户所携带的移动终端的mac地址。步骤s101具体包括:
步骤s1011、在统计周期内,实时扫描位于该场所内的全部移动终端的mac地址,并将扫描到的mac地址作为相应用户的身份信息。
通常,用户与其所携带的移动终端(例如,手机)是一一对应的,因此可利用用户所携带的移动终端的mac地址来作为用户的身份信息。
在步骤s1011中,可在每各场所内均设置对应的扫描子单元,扫描子单元(例如,mac地址查询扫描器)的扫描范围覆盖对应的场所,扫描子单元通过信号扫描技术来扫描对应场所内的全部移动终端,并获取扫描到的移动终端的mac地址。
需要说明的是,上述以用户所携带的移动终端的mac地址作为用户的身份信息,通过扫描子单元扫描移动终端的mac地址来获取用户的身份信息的情况,仅为本发明中的一种可选方案,其不会对本发明的技术方案产生限制。在本发明中,还可选用其他内容来作为用户身份信息,用户身份信息为其人脸图像,此时可在各场所设置对应的摄像头,通过实时获取场所内的图像,并经过人脸识别技术以识别出位于场所内的用户,并将人脸图像作为该用户的身份信息。本领域技术人员应该知晓的是,本发明中对用户的身份信息的具体指代以及获取用户的身份信息所使用的技术手段均不作限定,仅需保证不同用户所对应的身份信息不同即可,而获取身份信息的技术手段可采用现有技术中任意的用户识别方法,此处不再一一举例说明。
步骤s102、针对每一个场所,统计出在预设时间段内出现于该场所的各用户的身份信息和各用户对应的出现频数。
在步骤s102中,针对每一个场所,对该场所在各统计周期所获获得的各用户的身份信息以及出现频数进行统计(将同一用户在同一场所的出现频率进行累计求和),可得到在预设时间段内出现于该场所的各用户的身份信息和各用户对应的出现频数。
通过上述步骤s101和步骤s102即可获取在预设时间段内各场所对应的用户信息。在本实施例中,假定场所的总数为j,则通过步骤s101和步骤s102可获得j个用户信息。
步骤s201、以出现频数作为特征,根据各场所对应的用户信息,生成各场所的特征向量。
可选地,步骤s201包括:
步骤s2011、从j个用户信息中,剔除仅在一个场所中出现过的用户的身份信息和该用户对应的出现频数。
在步骤s2011中,在完成数据剔除后,j个用户信息中总计包括i个不同用户的身份信息。
步骤s2012、以j个不同场作为j个文件,i个用户作为i个词,采用tf-idf算法提取各场所的特征向量。
其中,步骤s2012具体包括:
步骤s2012a、计算各用户在各场所对应的词频。
在步骤s2012a中,采用如下公式计算各用户在各场所对应的词频(termfrequency,简称tf):
其中,tfi,j表示第i个用户在第j个场所的词频,ni,j表示在预设时间段内第i个用户在第j个场所的出现频数,i∈[1,i]且i为整数,j∈[1,j]且j为整数;
步骤s2012b、计算各用户的逆向文件频率。
在步骤s2012b中,采用如下公式计算各各用户的逆向文件频率(inversedocumentfrequency,简称idf):
其中,idfi表示第i个用户对应的逆向文件频率,dj表示第j个场所,|j:ti∈dj|表示在预设时间段内出现过第i用户的场所的总数量;
步骤s2012c、计算各用户在各场所对应的权重评分。
在步骤s2012b中,采用如下公式计算各用户在各场所对应的权重评分:
tfidfi,j=tfi,j×idfi
其中,tfidfi,j表示第i个用户在第j个场所的权重评分;
步骤s2012c、生成各场所的特征向量。
其中,第j个场所的特征向量aj可表示为:
aj=(tfidf1,j,tfidf2,j,...,tfidfi,j)
需要说明的是,在本发明中还可以采用其他特征向量提取算法来对各场所对应的用户信息进行处理,并得到各场所的特征向量,此处不再一一举例说明。
步骤s202、计算待评估的两个场所的特征向量之间的相似度,以作为该待评估的两个场所之间的关联度。
可选地,步骤s202包括:
步骤s2021、计算待评估的两个场所的特征向量之间的距离,并将计算结果作为待评估的两个场所的特征向量之间的相似度。
在本发明中,通过两个场所的特征向量之间的距离来表征两个场所的特征向量之间的相似度。
在步骤s2021中,可采用向量余弦距离算法、欧式距离算法、直方图交叉核(histogramofintersection)算法等能够计算两向量之间距离的算法。本领域技术人员应该知晓的是,本发明的技术方案对计算向量之间距离所使用的算法不作限定。
通过上述步骤s201和步骤s202可对任意两个场所之间的关联度进行量化,便于后续作进一步的分析。
图3为本发明实施例三提供的一种场所之间关联度的评估系统的结构示意图,如图3所示,该场所之间关联度的评估系统可用于实现上述实施例一和实施例二中提供的评估方法,该评估系统包括:获取模块1和评估模块2。
其中,获取模块1用于获取在预设时间段内各场所对应的用户信息,用户信息包括:在预设时间段内在对应的场所出现过的各用户的身份信息和各用户对应的出现频数。
评估模块2用于根据各场所对应的用户信息,评估任意两个场所之间的关联度。
需要说明的是,本实施例中的获取模块可用于执行上述实施例一中的步骤s1,评估模块可用于执行上述实施例二中的步骤s2,对于该两个模组的具体描述可参见前述实施例一中的内容。
可选地,预设时间段包括:若干个统计周期;获取模块1包括:获取单元101和统计单元102。
其中,获取单元101用于在每一个统计周期内,针对每一个场所,获取在该统计周期内出现于该场所的各用户的身份信息,并将相应用户在该统计周期内出现于该场所的出现频数记为1;
统计单元102用于针对每一个场所,统计出在预设时间段内出现于该场所的各用户的身份信息和各用户对应的出现频数。
进一步可选地,身份信息包括:相应用户所携带的移动终端的mac地址;获取单元101包括:与场所一一对应的若干个扫描子单元;扫描子单元用于在统计周期内实时扫描位于对应场所内的全部移动终端的mac地址,并将扫描到的mac地址作为相应用户的身份信息。
需要说明的是,本实施例中的获取单元101可用于执行上述实施例二中的步骤s101,统计单元102可用于执行上述实施例二中的步骤s102;扫描子单元可用于执行上述实施例二中的步骤s2011。
可选地,评估模块2包括:特征向量生成单元201和计算单元202;
特征向量生成单元201用于以出现频数作为特征,根据各场所对应的用户信息,生成各场所的特征向量。
计算单元202用于计算待评估的两个场所的特征向量之间的相似度,以作为该待评估的两个场所之间的关联度。
进一步可选地,场所的个数为j,j个场所对应j个用户信息;特征向量生成单元201包括:数据剔除单元和特征向量提取单元;
其中,数据剔除单元用于从j个用户信息中,剔除仅在一个场所中出现过的用户的身份信息和该用户对应的出现频数;完成数据剔除后,j个用户信息中总计包括i个不同用户的身份信息;
特征向量提取单元用于以j个不同场作为j个文件,i个用户作为i个词,采用tf-idf算法提取各场所的特征向量;
特征向量提取单元具体包括:第一计算子单元、第二计算子单元、第三计算子单元和生成子单元。
其中,第一计算子单元用于计算各用户在各场所对应的词频:
tfi,j表示第i个用户在第j个场所的词频,ni,j表示在预设时间段内第i个用户在第j个场所的出现频数,i∈[1,i]且i为整数,j∈[1,j]且j为整数;
第二计算子单元用于计算各用户的逆向文件频率:
其中,idfi表示第i个用户对应的逆向文件频率,dj表示第j个场所,|j:ti∈dj|表示在预设时间段内出现过第i用户的场所的总数量;
第三计算子单元用于计算各用户在各场所对应的权重评分:
tfidfi,j=tfi,j×idfi
其中,tfidfi,j表示第i个用户在第j个场所的权重评分;
生成子单元用于生成各场所的特征向量:
aj=(tfidf1,j,tfidf2,j,...,tfidfi,j)
其中,aj表示第j个场所的特征向量。
需要说明的是,本实施例中的特征向量生成单元201可用于执行上述实施例二中的步骤s201,计算单元202可用于执行上述实施例二中的步骤s202,数据剔除单元可用于执行上述实施例二中的步骤s2011,特征向量提取单元可用于执行上述实施例二中的步骤s2012。
可选地,计算单元202包括:距离计算子单元,用于计算待评估的两个场所的特征向量之间的距离,并将计算结果作为待评估的两个场所的特征向量之间的相似度。
需要说明的是,本实施例中的距离计算子单元可用于执行上述实施例二中的步骤s2021。
本发明实施例三提供了一种场所之间关联度的评估系统,以场所的用户信息作为数据支撑,能够客观、准确的对场所之间关联度进行评估和量化,便于后续作进一步的分析。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!