适应输配电网一体化规划的高压配网变电站负荷预测方法与流程
本发明涉及变电站供区负荷预测领域,具体地说是一种适应输配电网一体化规划的高压配网变电站负荷预测方法。
背景技术:
目前,用电量预测的方法主要分两大类:传统预测方法和智能预测方法。
传统预测方法主要包括:弹性系数法、回归分析法、时间序列预测法、产值单耗法及它们的衍化方法。智能预测方法主要包括神经网络、模糊逻辑、专家系统等。上述方法均具有比较强的针对性,适合整体地区的预测方式较难合理分割负荷,配电网的预测方式难以对整个地市发展情况进行适应,较难用一种方法贯穿输配电网负荷预测。
技术实现要素:
为解决上述现有技术存在的问题,本发明提供一种能适应输配电网一体化规划需求,针对高压配电网中变电站供区负荷的预测方法。
本发明采用的技术方案如下:一种适应输配电网一体化规划的高压配网变电站负荷预测方法,其包括:
结合输配网一体化规划需求特点,采用elman神经网络模型和空间负荷预测相结合的高压配网负荷预测方法,以高压配网变电站供区为预测单位,从历史负荷和空间预测相结合对高压配网中长期负荷进行预测,引入基于网格开发度的供区负荷计算模型。
本发明引入网格开发度概念,突破了传统采用固定负荷与网格对应的模式,衔接了变电站供区历史负荷趋势与细化网格负荷情况,满足了区域配电网变电站负荷预测的需求。
作为上述技术方案的补充,基于网格开发度的供区负荷计算模型的具体内容如下:
高压配电网通过运行方式与上级电压等级负荷分配进行有效联系,通过站点供区内空间地理划分与下级配电网负荷分布预测相适应;设地市根据市政规划共分为m个网格,总面积为sm,范围内共有k个110千伏变电站,以110千伏变电站供区为分析区域,第i年变电站供区内共ei个网格,网格区块面积的向量集为si={s(1i),s(2i),…,s(ei)},有
计算网格区块负荷时,仅记及10千伏及以下大用户,最大负荷密度向量集为pimax={pmax(1i),pmax(2i),…,pmax(ei)},网格内部最大容积率向量集为βimax={βmax(1i),βmax(2i),…,βmax(ei)},引入区域开发度向量γi={γ(1i),γ(2i),…,γ(ei)}表示网格内负荷开发度,其中γ(ei)∈[0,1],引入网格土地利用度θi={θ(1i),θ(2i),…,θ(ei)}代表某时期内网格容积率与目标建设规模的比例,其中θ(ei)∈[0,1];
网格内35千伏及以上电压等级直供大用户负荷由于无法用负荷密度乘算得到,依靠报装数据统计有yi={y(1i),y(2i),…,y(ei)},非工业类值为0,当年新增报装量为δyi,有:
式中,ui为同时率;wi为第i年该110千伏供区内网格化综合负荷;由于一般土地利用建设进度与负荷发展进度有一定的正向关系,为加速计算收敛,设|θ(ei)-γ(ei)|∈[0,0.2];pi,βi分别为第i年的实际负荷密度向量及实际容积率向量。
本发明采用开发度来描述逐年网格与地区经济-负荷网格规划最大值比例情况,通过对开发度特征限制和预测,来拟合实际地区发展情况下经济增长情况对网格区域负荷的影响。
作为上述技术方案的补充,所述变电站供区负荷预测方法在采用改进elman网络模型对历史样本进行训练:
对于历史网格化负荷数据采用下面各式计算修正权值:
对于“s”型曲线修正样本,采用以下方法计算修正权值:
上述各式中,k表示计算序列号,i、j分别表示矩阵的第i行、第j列;
计算得到的修正权值
作为上述技术方案的补充,所述elman神经网络模型的计算逻辑如下:
对于该神经网络模型,输入向量
xh(k)=f[wh·xc(k)+wc·sin(k-1)],
xc(k)=xh(k-1),
sout(k)=g(wout·xh(k)),
式中,k表示计算序列号,f[wh·xc(k)+wc·sin(k-1)]为隐含层单元激励函数,g(wout·xh(k))为输出层单元的激励函数;样本训练时,误差目标函数如下:
作为上述技术方案的补充,在采用历史样本进行训练的同时,采用“s”型曲线学习样本作为修正样本;
历史样本:
对于过去i年整个县市地区进行网格化分解和计算,地区划分为m个分区,网格区块面积的向量集为s={s(1),s(2),…,s(m)},对于网格s(m),有:
βim=si(m)/s(m),
其中,βim为第i年m网格的容积率,
计算第i年网格开发度γi(m),有:
同时满足涵盖第m网格的110千伏变电站供区有:
γ'i={γ'(1i),γ'(2i),…,γ'(ei)},
若|γ'i(m)-γi(m)|>ζ,
γi(m)=|γ'i(m)+γi(m)|/2,
其中,wim是m网格第i年关口负荷,w'im是m网格上一年对第i年关口负荷的预测值,yim是该网格内大用户负荷量,γ'i为包含第m网格的110千伏变电站供区在第i年供区内网格开发度向量集合,w'i为该110千伏变电站在第i年负荷实测数据,γ'i(m)为通过第i年负荷实测计算得到的m网格开发度,ζ为差异门槛,对开发度进行核对和修正;
“s”型曲线学习样本:
考虑经济和用电量发展情况,规划2040年为用电饱和年,以1991年为统计初始年,期间50年用电负荷经历“s”型曲线达到饱和水平;
将“s”型曲线加入样本中共同训练,促进开发度样本训练的拟合程度,对于辅助样本,有拟合曲线:
将其与区域网格开发度结合描述为:
其中,i为年份,cm为m网格的土地性质,cm={居住,商务,市政,金融,工业,娱乐}对应cm={1,2,3,4,5,6},随着用地性质不同对曲线进行修正,学习样本采用历史实际网格化数值及拟合曲线共同学习。
作为上述技术方案的补充,输入、输出值针对开发度及土地开发度进行计算:
单次输入采用过去五年历史数据、土地性质进行,第i年,第m网格输入为:
xm(i)={cm,sm,γi-4,γi-3,γi-2,γi-1,γi,θi,εi-4,εi-3,εi-2,εi-1,εi};
其中,xm(i)为第i年m网格的输入量,cm,sm分别为m网格的土地性质和面积,通过上一小节计算得到网格5年(含当年)的开发度情况γi-4~γi,通过统计数据得到本地市五年内经济增长率εi-4~εi;
输出量ym(i)=(γi+1,θi+1);
采用历史数据及拟合曲线作为学习样本,对elman神经网络模型进行训练,得到函数承接层、输入层到中间层以及中间层到输出层的连接权值
本发明采用开发度概念将网格时空负荷密度与规划最大网格负荷密度联系,抽取了负荷发展过程中,具有连续趋势性变量(开发度),形成数据可推算的历史数据库,以“s”型曲线作为辅助样本,采用改进eman神经网络进行网格开发度的预测计算;得到预测值后,以110千伏供区为统计范围,计算在未来网格开发度及未来供区范围下供区内负荷预测值情况。
本发明将充分适应网格固化,变电供区变化的特性进行建模设计,综合了空间规划中具有的远景最大负荷密度数据优势,同时在计算样本中动态引入历年变电站实测数据对网格开发度进行修正;预测得到网格开发度后,考虑未来年变电供区划分变化重新计算得到高压配网供区负荷情况。
附图说明
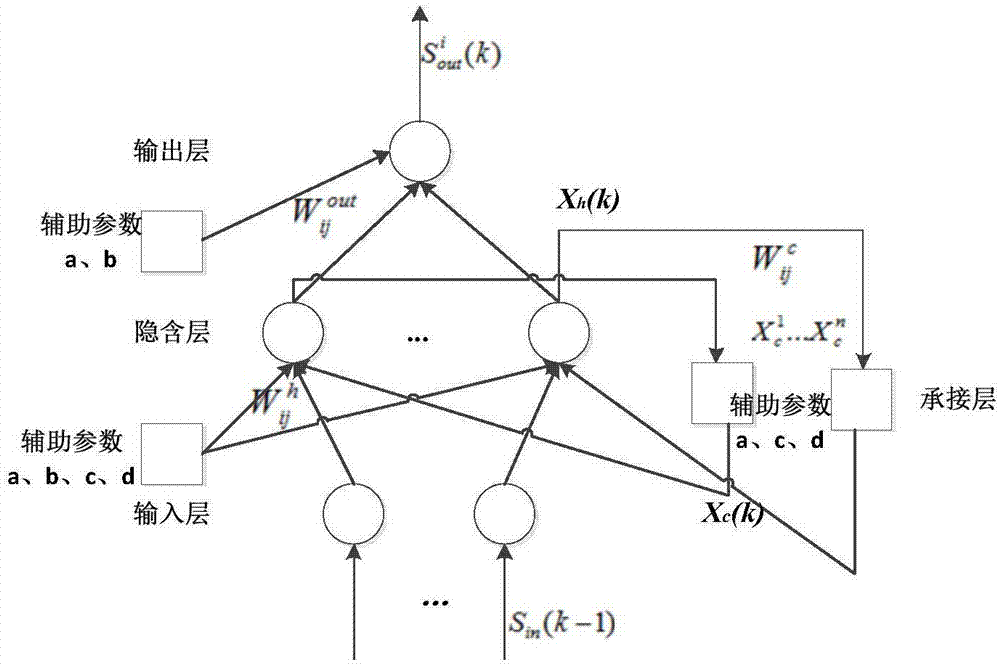
图1为本发明实施例中改进的elman神经网络模型结构形式图;
图2为传统配电网网格化负荷预测方法的流程图;
图3为本发明实施例中开发度发展曲线图;
图4为本发明实施例中负荷预测方法的流程图。
具体实施方式
下面结合说明书附图及具体实施方式对本发明进一步说明。
1.elman神经网络模型
由输入层、隐含层、承接层、输出层组成,其隐含层采用非线性激励函数,承接层获取隐含层第n次输出,反馈作用于隐含层第n+1次计算。结合本发明需要,网络输入层向量维度为n,考虑隐含层级承接层维度为n+1,出于计算精度及算法逻辑考虑,此处针对性的把输出层元素数量设为1。
对于该神经网络,输入向量
xh(k)=f[wh·xc(k)+wc·sin(k-1)],
xc(k)=xh(k-1),
sout(k)=g(wout·xh(k)),
式中,k表示计算序列号,f[wh·xc(k)+wc·sin(k-1)]为隐含层单元激励函数,g(wout·xh(k))为输出层单元的激励函数f(k)为隐含层单元激励函数。样本训练时,误差目标函数ep如下:
2.网格化分析法
分类分区预测法是基于分类分区原则的空间负荷预测法,很多文献中又称为负荷密度指标法,该方法是依据城市控制性详细规划图(以下简称控规图)将规划地区不同的用电性质进行分类,再对规划地区进行分区,即将规划地区按照控规图进行分类分区。在完成分类分区的基础上,收集各分区负荷历史数据,结合国内外发达城市或地区的负荷密度指标,选择不同用电性质以及不同分区的负荷密度指标,从而预测出规划地区的负荷分布情况以及饱和负荷。传统网格化负荷预测方法如图2所示。
3.颗粒度选择
负荷网格颗粒度主要分为大、中、小三类,适应不用口径的分析计算。其中,大颗粒数以行政片区作为一个大区,或以主干道、国道、绿化带等公共设施或河流等自然地形作为边界;中等颗粒度一般为3-5km2,一般以用地性质、街道、绿化、河道等为边界;小颗粒度以城市控规图为标准,一般每块区域面积在1km2以下。考虑本发明主要针对高压配电网开展计算,需要考虑供区内细化发展情况,故采用小颗粒度。
由于城市控规图对每个功能区有详细的规划,规划人员可以较为轻松的确定不同的分区的负荷类型。各小区负荷变化受电力设备或变电站供电范围变化影响较小。由于各小区的用电负荷性质不会随着电力设备和变电站供电范围变化而改变,因此各小区的历史负荷数据依然是分析其负荷发展规律的可靠依据之一。
实施例
本实施例提供一种适应输配电网一体化规划的高压配网变电站负荷预测方法,其包括:结合输配网一体化规划需求特点,采用elman神经网络模型和空间负荷预测相结合的高压配网负荷预测方法,以高压配网变电站供区为预测单位,从历史负荷和空间预测相结合对高压配网中长期负荷进行预测,引入基于网格开发度的供区负荷计算模型。上述高压配网变电站负荷预测方法的具体流程详见图4。
考虑一体化规划过程中,变电站供区及区、县范围是重要的基层范围,并且在电网分层分区基本完成的情况下,高压网(如110千伏)站点供区一般位于区县范围内,跨区转供负荷在配电网架基本理顺后对整体影响较小。传统省、市及网格化负荷预测以空间及行政区划范围进行,预测后与规划所需的对于电网、站点的平衡、计算等较难有效衔接。
基于网格开发度的供区负荷计算模型的具体内容如下:
高压配电网通过运行方式与上级电压等级负荷分配进行有效联系,通过站点供区内空间地理划分与下级配电网负荷分布预测相适应;设地市根据市政规划共分为m个网格,总面积为sm,范围内共有k个110千伏变电站,以110千伏变电站供区为分析区域,第i年变电站供区内共ei个网格,网格区块面积的向量集为si={s(1i),s(2i),…,s(ei)},有
考虑35千伏及以上电压等级入网直供大用户直接接入220千伏及以上电压等级变电站,计算网格区块负荷时,仅记及10千伏及以下大用户(35千伏及以上等压等级直供用户在后续计算中单独考虑),最大负荷密度向量集为pimax={pmax(1i),pmax(2i),…,pmax(ei)},网格内部最大容积率向量集为βimax={βmax(1i),βmax(2i),…,βmax(ei)},引入区域开发度向量γi={γ(1i),γ(2i),…,γ(ei)}表示网格内负荷开发度,其中γ(ei)∈[0,1],引入网格土地利用度θi={θ(1i),θ(2i),…,θ(ei)}代表某时期内网格容积率与目标建设规模的比例,其中θ(ei)∈[0,1];
网格内35千伏及以上电压等级直供大用户负荷由于无法用负荷密度乘算得到,依靠报装数据统计有yi={y(1i),y(2i),…,y(ei)}(非工业类值为0),当年新增报装量为δyi,有:
式中,ui为同时率(所有网格并非同时达到负荷最大值,以同时率代表整体负荷最大时,平均网格负荷占自身最大值的比例);wi为第i年该110千伏供区内网格化综合负荷;由于一般土地利用建设进度与负荷发展进度有一定的正向关系,为加速计算收敛,设|θ(ei)-γ(ei)|∈[0,0.2];pi,βi分别为第i年的实际负荷密度向量及实际容积率向量。
本发明采用开发度来描述逐年网格与地区经济-负荷网格规划最大值比例情况,通过对开发度特征限制和预测,来拟合实际地区发展情况下经济增长情况对网格区域负荷的影响。
所述变电站供区负荷预测方法在采用改进elman网络模型对历史样本进行训练:
对于历史网格化负荷数据采用下面各式计算修正权值:
对于“s”型曲线修正样本,采用以下方法计算修正权值:
上述各式中,k表示计算序列号,i、j分别表示矩阵的第i行、第j列;
计算得到的修正权值
所述elman神经网络模型的计算逻辑如下:
对于该神经网络模型,输入向量
xh(k)=f[wh·xc(k)+wc·sin(k-1)],
xc(k)=xh(k-1),
sout(k)=g(wout·xh(k)),
式中,k表示计算序列号,f[wh·xc(k)+wc·sin(k-1)]为隐含层单元激励函数,g(wout·xh(k))为输出层单元的激励函数;样本训练时,误差目标函数如下:
在采用历史样本进行训练的同时,采用“s”型曲线学习样本作为修正样本;
历史样本:
对于过去i年整个县市地区进行网格化分解和计算,地区划分为m个分区,网格区块面积的向量集为s={s(1),s(2),…,s(m)},对于网格s(m),有:
βim=si(m)/s(m),
其中,βim为第i年m网格的容积率,
计算第i年网格开发度γi(m),有:
同时满足涵盖第m网格的110千伏变电站供区有:
γ'i={γ'(1i),γ'(2i),…,γ'(ei)},
若|γ'i(m)-γi(m)|>ζ,
γi(m)=|γ'i(m)+γi(m)|/2,
其中,wim是m网格第i年关口负荷,w'im是m网格上一年对第i年关口负荷的预测值,yim是该网格内大用户负荷量,γ'i为包含第m网格的110千伏变电站供区在第i年供区内网格开发度向量集合,w'i为该110千伏变电站在第i年负荷实测数据,γ'i(m)为通过第i年负荷实测计算得到的m网格开发度,ζ为差异门槛,对开发度进行核对和修正;
“s”型曲线学习样本:
考虑经济和用电量发展情况,规划2040年为用电饱和年,以1991年为统计初始年,期间50年用电负荷经历“s”型曲线达到饱和水平,如图3所示。
将“s”型曲线加入样本中共同训练,促进开发度样本训练的拟合程度,对于辅助样本,有拟合曲线:
将其与区域网格开发度结合描述为:
其中,i为年份,cm为m网格的土地性质,cm={居住,商务,市政,金融,工业,娱乐}对应cm={1,2,3,4,5,6},随着用地性质不同对曲线进行修正,学习样本采用历史实际网格化数值及拟合曲线共同学习。
对于cm={1,2,3,4,5,6}情况下,分别将i∈[0,50](步长取0.2)代入fm(i),计算得到集合数组f{i,fm(i),cm},其在二维坐标上呈现“s”型,故“s”型学习样本指的就是数组f{i,fm(i),cm}。举例当i=10.2,cm=3情况下,计算fm(i)=0.085,则{10.2,0.085,3}就是数组中的一个元素。
输入、输出值针对开发度及土地开发度进行计算:
单次输入采用过去五年历史数据、土地性质进行,第i年,第m网格输入为:
xm(i)={cm,sm,γi-4,γi-3,γi-2,γi-1,γi,θi,εi-4,εi-3,εi-2,εi-1,εi};
其中,xm(i)为第i年m网格的输入量,cm,sm分别为m网格的土地性质和面积,通过上一小节计算得到网格5年(含当年)的开发度情况γi-4~γi,通过统计数据得到本地市五年内经济增长率εi-4~εi;
输出量ym(i)=(γi+1,θi+1);
采用历史数据及拟合曲线作为学习样本,对elman神经网络模型进行训练,得到函数承接层、输入层到中间层以及中间层到输出层的连接权值
应用例
相关计算及实现步骤如下:
1.将地市范围进行网格化分割,分为m个网格,可依据城市规划进行网格的分割和制定。
2.调取地市范围内电网历史数据,查询对应网格所属变电站第i年的负荷以及m网格关口数据。
3.采用网格开发度的供区负荷计算模型,计算每个网格第i年的开发度历史数据。
4.计算所有网格及所有年份历史开发度及土地利用度,完成历史样本获取。
5.对地区所有网格进行性质分类,并采用”s”型函数拟合修正样本。
6.将历史样本和修正样本按照输入输出格式导入elman神经网络进行学习,获得网格开发度的连接权值。
7.将历史数据导入elman神经网络,采用上述权值进行计算,得到第i+1年的开发度预测值。
8.采用新预测值迭代计算,得到后3年的网格开发度及土地利用度。
9.导入需要计算的变电站供区范围信息,采用网格开发度的供区负荷计算模型计算得到后3年的变电站供区负荷预测值。
- 还没有人留言评论。精彩留言会获得点赞!