一种基于博弈神经网络的PM2.5浓度值预测方法与流程
本发明涉及空气颗粒物pm2.5浓度值的预测技术领域,尤其涉及一种基于博弈神经网络的pm2.5浓度值预测方法。
背景技术:
pm2.5是指大气中直径小于或等于2.5微米的颗粒物,富含大量的有毒、有害物质且在大气中的停留时间长、输送距离远,因而对人体健康和大气环境质量的影响更大,pm2.5超标还带来了另外一个影响——灰霾天气。空气污染如今已经成为人们关注的焦点,而在空气污染指标中,pm2.5浓度值已经成为衡量空气质量的标志性检测指标。现如今,根据历史数据对未来时间段pm2.5浓度值的预测已经成为具有较强学术意义和应用价值的研究问题。
为了解决上述问题,张怡文等人在论文《基于神经网络的pm2.5预测模型》中,通过选择神经网络方法进行pm2.5的浓度值预测。王敏等人在论文《基于bp人工神经网络的城市pm2.5浓度空间预测》中,采用bp人工神经网络模型,预测研究区空气中pm2.5浓度的空间变异。郑毅等人在论文《基于深度信念网络的pm2.5预测》中,提出一种基于深度信念网络的区域pm2.5日均值预测方法。杨云等人在论文《关于空气中pm2.5质量浓度预测研究》中,提出了采用遗传算法优化的bp神经网络的预测方法实现了pm2.5浓度值的预测。马天成等人在论文《基于改进型pso的模糊神经网络pm2.5浓度预测》中,采用一种改进型pso优化的模糊神经网络,将粒子群算法与模糊神经网络进行融合来预测pm2.5颗粒物浓度的变化规律。杨云等人在论文《基于t-s模型模糊神经网络的pm2.5质量浓度预测》中,提出了基于t-s模糊神经网络的pm2.5质量浓度预测方法。苏盈盈等人在专利《基于无迹卡尔曼神经网络的pm2.5浓度预测方法》中,提供了一种基于无迹卡尔曼神经网络的pm2.5浓度预测方法。
经文献调研分析,目前已提出的pm2.5浓度值预测方法均以神经网络为核心架构,对pm2.5浓度值以及其他相关指标(比如aqi、pm10、no2、co、so2、o3)进行非线性回归分析。神经网络模型包含ann,dnn,fnn和bpnn等,以及结合遗传算法、随机森林等优化算法优化后的混合方法。但是,经文献调研,现有pm2.5浓度值神经网络预测方法中都需要积累大量的历史数据用以训练,最终的预测精度与原始样本数据的大小也有一定关系,而对于无大量数据积累的小样本集,现有的神经网络预测方法就失去了其优势。其次,现有的神经网络预测模型都是定义已知模型对数据进行训练,即学习目标的分布类型已经既定,实际工作主要为学习并调整该分布的具体参数。
技术实现要素:
为了克服已有pm2.5浓度值预测方式无法训练小数据集以及目标模型需要事先定义的不足,本发明在对pm2.5浓度值历史数据、pm2.5浓度值相关指标历史数据和气象历史数据进行非线性相关分析之外,还引入一个生成网络将原始数据与噪声混合输出模拟数据,并将模拟数据送入判别网络进行判别,根据判别结果进行交次迭代与调整,提供一种针对小数据集,无需预设目标模型,可以准确描述pm2.5浓度值时间变化规律的基于博弈神经网络的pm2.5浓度值预测方法。
本发明解决其技术问题所采用的技术方案是:
一种基于博弈神经网络的pm2.5浓度值预测方法,所述方法包括如下步骤:
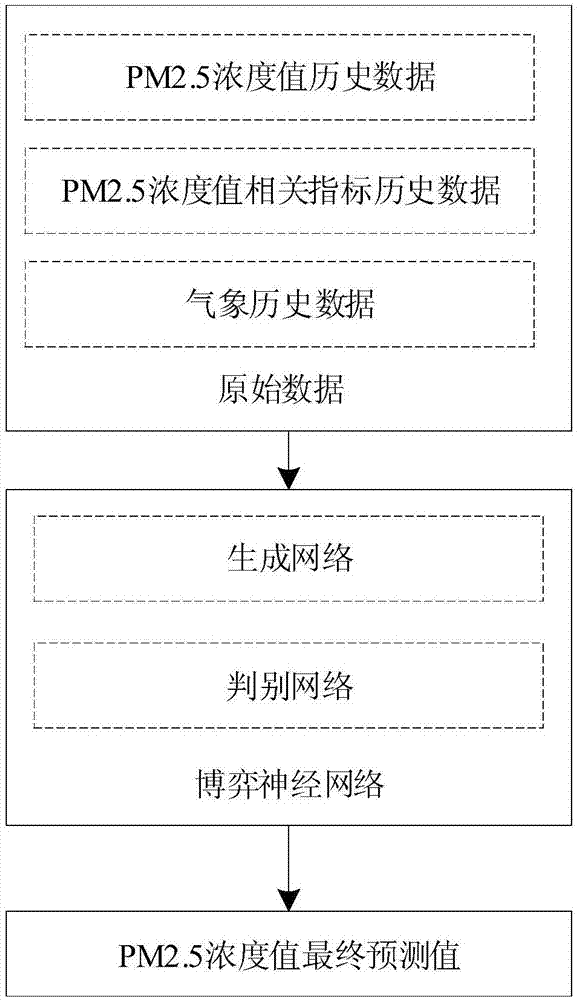
步骤1、原始数据采集。原始数据包括pm2.5浓度值历史数据、pm2.5浓度值指标历史数据和气象历史数据;
步骤2、采用生成网络生成模拟数据,过程如下:
步骤2.1、创建一个包含输入层、隐含层和输出层的三层神经网络,设定隐含层和输出层的节点个数,所述隐含层的节点个数采用经验公式给出估计值,所述经验公式如下:
上式中,a和b分别为输入层和输出层的神经元个数,c是[0,10]之间的常数;
步骤2.2、分别设定输入层、输出层数据的维度,隐含层、连接层和输出层的训练函数、连接函数和输出函数,设定网络的期望误差最小值、最大迭代次数和学习率;
步骤2.3、随机产生一组随机数据作为生成模型的输入层数据,然后经过生成模型后在输出层产生一组新的pm2.5预测数据,作为fakedata,记作d(m);
步骤3、采用判别网络判断模拟数据的真伪,过程如下:
步骤3.1、创建一个包含输入层、隐含层和输出层的三层神经网络,设定隐含层和输出层的节点个数;所述隐含层的节点个数采用经验公式给出估计值,所述经验公式如下:
上式中,a和b分别为输入层和输出层的神经元个数,c是[0,10]之间的常数;
步骤3.2、在输出层之后连接一层softmax函数,将多分类的输出数值转化为相对概率;
其中,vi是分类器前级输出单元的输出。i表示类别索引,总的类别个数为c,si表示的是当前元素的指数与所有元素指数和的比值;
步骤3.3、从数据集中随机选择一组数据作为realdata,记作x;
步骤3.4、将d(m)和作为x输入数据输入判别网络中,经过判别网络后输出值为一个0到1之间的数,用于表示输入数据为realdata的概率,real为1,fake为0;
步骤4、采用博弈神经网络预测pm2.5浓度值,过程如下:
步骤4.1、将生成网络中生成的模拟数据与原始数据输入判别神经网络,建立博弈神经网络并训练;
步骤4.2、计算判别网络损失函数:
ld=-((1-y)log(1-d(g(m)))+ylogd(x))⑷
y为输入数据的类型,当输入数据为realdata数据时,y=1,损失函数公式的前半部分为0。d(x)为判别模型的输出,表示输入x为real数据的概率,训练目标要使得判别网络的输出d(x)的输出趋向于1;
当输入数据为fakedata数据时,y=0,损失函数公式的后半部分为0,g(m)是生成模型的输出,此时的训练目标要使得d(g(m))的输出趋向于0;
步骤4.3、计算生成网络损失函数:
lg=(1-y)log(1-d(g(m)))⑸
生成网络的训练目标是要使得g(m)产生的数据与真实数据具备同样的数据分布;
步骤4.4、计算博弈神经网络的损失函数:
其中,
步骤4.5、根据损失函数的误差进行反向传播,调整循环神经网络的各层权值,调整方式如下:
调整规则为:最大化d的区分度,最小化g和real数据集的数据分布;
步骤4.6、判断博弈神经网络是否收敛,当误差小于期望误差最小值时,算法收敛,在达到最大迭代次数时结束算法,所述博弈神经网络训练完成;
步骤4.7、将待测数据输入到所述训练完成的博弈神经网络中,输出pm2.5浓度值的最终预测值。
进一步,所述pm2.5浓度值指标包括aqi、pm10、no2、co、so2和o3浓度。
本发明中,所述步骤3中,使用了判别网络对原始数据和生成网络的模拟数据进行判别,得到生成网络模拟数据的真实性。
所述步骤4中,通过对生成网络和判别网络分别计算损失函数,得到博弈神经网络总的损失函数,并依据经由损失函数计算得到的损失值定义了反向传播的权值调整规则。
本发明的技术构思为:在对pm2.5浓度值历史数据,pm2.5浓度值相关指标的历史数据(aqi、pm10、no2、co、so2、o3)和气象历史数据(气温、相对湿度、气压、风速、降水量等)数据进行非线性相关分析之外,还引入一个生成网络将原始数据与噪声混合输出模拟数据,并将模拟数据送入判别网络进行判别,根据判别结果进行交次迭代与调整,提供一种基于博弈神经网络的pm2.5浓度值预测方法。
本发明的有益效果主要表现在:本发明的技术方案不仅能够准确地处理具备大量历史数据积累的完备样本集,同样可以高效高精度地处理无大量数据积累的小样本集,并且不需要定义已知模型对数据进行训练,即无需预设学习目标的分布类型,有效地提高当前pm2.5浓度值的预测精度与训练速度,拓宽了神经网络训练的局限性,能够实现小样本集的精准预测。
附图说明
图1是一种基于博弈神经网络的pm2.5浓度值预测方法示意图。
图2是生成网络的模拟流程图。
图3是判别网络的判别流程图。
图4是博弈神经网络的训练流程图
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图4,一种基于博弈神经网络的pm2.5浓度值预测方法,所述方法包括如下步骤:
步骤1、原始数据采集。原始数据包括pm2.5浓度值历史数据、pm2.5浓度值指标(比如aqi、pm10、no2、co、so2、o3)历史数据和气象历史数据;
步骤2、采用生成网络生成模拟数据,过程如下:
步骤2.1、创建一个包含输入层、隐含层和输出层的三层神经网络,设定隐含层和输出层的节点个数。所述隐含层的节点个数采用经验公式给出估计值,所述经验公式如下:
上式中,a和b分别为输入层和输出层的神经元个数,c是[0,10]之间的常数;
步骤2.2、分别设定输入层、输出层数据的维度,隐含层、连接层和输出层的训练函数、连接函数和输出函数,设定网络的期望误差最小值、最大迭代次数和学习率;
步骤2.3、随机产生一组随机数据作为生成模型的输入层数据,然后经过生成模型后在输出层产生一组新的pm2.5预测数据,作为fakedata,记作d(m);
步骤3、采用判别网络判断模拟数据的真伪,过程如下:
步骤3.1、创建一个包含输入层、隐含层和输出层的三层神经网络,设定隐含层和输出层的节点个数,所述隐含层的节点个数采用经验公式给出估计值,所述经验公式如下:
上式中,a和b分别为输入层和输出层的神经元个数,c是[0,10]之间的常数;
步骤3.2、在输出层之后连接一层softmax函数,将多分类的输出数值转化为相对概率;
其中,vi是分类器前级输出单元的输出。i表示类别索引,总的类别个数为c,si表示的是当前元素的指数与所有元素指数和的比值;
步骤3.3、从数据集中随机选择一组数据作为realdata,记作x;
步骤3.4、将d(m)和作为x输入数据输入判别网络中,经过判别网络后输出值为一个0到1之间的数,用于表示输入数据为realdata的概率,real为1,fake为0;
步骤4、采用博弈神经网络预测pm2.5浓度值,过程如下:
步骤4.1、将生成网络中生成的模拟数据与原始数据输入判别神经网络,建立博弈神经网络并训练;
步骤4.2、计算判别网络损失函数:
ld=-((1-y)log(1-d(g(m)))+ylogd(x))⑷
y为输入数据的类型,当输入数据为realdata数据时,y=1,损失函数公式的前半部分为0,d(x)为判别模型的输出,表示输入x为real数据(y=1,代表是real数据)的概率,训练目标要使得判别网络的输出d(x)的输出趋向于1;
当输入数据为fakedata数据时,y=0,损失函数公式的后半部分为0,g(m)是生成模型的输出,此时的训练目标要使得d(g(m))的输出趋向于0;
步骤4.3、计算生成网络损失函数:
lg=(1-y)log(1-d(g(m)))⑸
生成网络的训练目标是要使得g(m)产生的数据与真实数据具备同样的数据分布;
步骤4.4、计算博弈神经网络的损失函数:
其中,
步骤4.5、根据损失函数的误差进行反向传播,调整循环神经网络的各层权值,调整方式如下:
调整规则为:最大化d的区分度,最小化g和real数据集的数据分布;
步骤4.6、判断博弈神经网络是否收敛,当误差小于期望误差最小值时,算法收敛;在达到最大迭代次数时结束算法,所述博弈神经网络训练完成;
步骤4.7、将待测数据输入到所述训练完成的博弈神经网络中,输出pm2.5浓度值的最终预测值。
- 还没有人留言评论。精彩留言会获得点赞!
- 图像属性识别方法和系统以及相关网络训练方法和系统与制造工艺
- 一种基于增量式神经网络模型的甲亢预测方法和预测系统与制造工艺
- 一种基于增量式神经网络模型的冠心病预测方法和预测系统与制造工艺
- 一种基于增量式神经网络模型的慢性疲劳综合症预测方法和预测系统与制造工艺
- 一种基于增量式神经网络模型的痱子预测方法和预测系统与制造工艺
- 一种基于增量式神经网络模型的焦虑症预测方法和预测系统与制造工艺
- 一种基于增量式神经网络模型的神经衰弱预测方法和预测系统与制造工艺
- 一种基于增量式神经网络模型的乙肝预测方法和预测系统与制造工艺
- 一种基于遗传神经网络的BMS系统的SOC的估算方法与制造工艺
- 一种基于bp神经网络改善的室内惯性导航方法与制造工艺