一种基于CNN优化的社交网络谣言方法与流程
本发明涉及自然语言处理和深度学习的技术领域,更具体地,涉及一种基于cnn优化的社交网络谣言方法。
背景技术:
谣言被定义为一个真实价值未经验证的故事或陈述。随着社交网络媒体的迅速发展,大量的谣言很容易在互联网上传播,比如微博、推特等平台上传播的推文,经常会有一些误导性的推文,影响公众的正确认知,甚至引起公众恐慌和社会混乱。2013年4月23日,仅因为一条关于白宫爆炸的谣言,就让美国的故事损失了1300亿美元。可见,在社交媒体上高效地检测谣言至关重要,并且应当在谣言传播之前尽可能早地检测出来。
社交网络谣言检测的相关工作有很多,有识别图片真伪的工作,也有识别维基百科上的误导性文章,有基于推文级别进行检测的,也有基于多条推文组成的事件进行的。现有的方法主要基于手工特征的挖掘与svm等传统机器学习分类器实现。典型的手工特征可以是情感词等内容特征,也可以是昵称、头像等用户特征,又或者是转发次数等传播特征。也有一些挖掘自用户反馈行为、事件传播的生命周期等更为复杂的特征。这些特征能够在一定程度上区分谣言,结合传统的有监督机器学习分类器,能够达到比较可观的检测效果。
近年来,深度学习方法一直是机器学习领域的重要热点,它一般具有多层神经网络结构,能够从更高层次表征文本的上下文特征。一些用深度学习模型进行谣言检测的工作也开始发展起来。深度学习模型整合的是所有推文的内容而不是部分特征信息,一个事件的转发次数、与评价相关的信息、用户的信誉等信息也会被整合进推文的内容当中。基于递归神经网络(rnn)和基于卷积神经网络(cnn)的深度学习模型被先后应用于社交网络谣言的检测中,并被证明效果明显优于传统手工特征结合机器学习分类器的方法。在这些方法中,cnn模型在社交网络谣言检测具有最优的准确性和时效性。
传统的提取手工特征方法虽然能挖掘出很多被证明有助于区分谣言与非谣言的重要特征,但是这些特征或多或少会对特定形式的样本数据有一些偏好性,并且无法挖掘出更深层次的特征,以至于在复杂的社交网络网络场景中常常显得乏力。
而目前基于rnn、cnn等模型的深度学习方法,通常从事件级别进行谣言检测,事件一般定义为多条描述同一事物的推文组成的集合。rnn模型因为其上一层输出会作为下一层的输入递归地进行编码的结构特点,所以会偏好于最后输入的推文,即发布时间最新的推文,但现实场景中常常不是这样,早期传播的推文往往具有重要的区分意义。而cnn的卷积层抽取特征本质上是一种n-gram的方法,倾向于提取局部特征,天然缺乏对长文本时序信息的表征能力,然而多项工作表明传播时间、传播周期等时序信息确实区分谣言与非谣言的一个重要尺度。并且这些将深度学习方法用于谣言检测的工作,本质上只是直接输入推文的内容信息,没有考虑不同的推文具有不同的重要性,并非一个事件下的所有推文对于区分事件是否为谣言具有同等作用,很多推文对于谣言检测可能是冗余的甚至可能成为噪音。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供一种基于cnn优化的社交网络谣言方法,融合了推文级别的内容信息和时序信息,基于cnn模型进行多层次训练,可提高社交网络谣言检测的准确率以及时效性。
本发明的技术方案是,一种基于cnn优化的社交网络谣言方法,其中,包括以下步骤:
s1.收集微博和推特平台的社交网络数据作为样本数据,对样本数据以事件级别进行整理,描述同一事件的所有推文作为一个样本,并将同一事件样本的推文按发布时间进行排序;
s2.对样本数据进行预处理;
s3.用paragraph2vec方法构建样本矩阵,样本矩阵的行向量为事件样本的一条推文的句向量;
s4.以分组的方式重新构建样本矩阵,根据发布时间间隔均等地将事件样本的所有推文划分为若干组,训练一个权重矩阵,通过卷积、池化提取每组推文的特征,构建组向量;
s5.根据每组的最大时间跨度构建时序向量;
s6.利用时序向量重新构建样本矩阵:将步骤s6得到的时序向量与步骤s5的样本矩阵相乘,得到新的样本矩阵;
s7.采用多层卷积神经网络对样本矩阵进行训练,构建训练模型;
s8.根据训练模型的结果对样本矩阵进行分类,得到事件样本是否为谣言的检测结果。
本发明要解决的为社交网络谣言检测问题,检测一个事件是否为谣言。
谣言被定义为一个真实价值未经验证的故事或陈述。随着社交网络媒体的迅速发展,大量的谣言很容易在互联网上传播,引起公众恐慌和社会混乱。因此,在社交媒体上高效地检测谣言至关重要,并且应当在谣言传播之前尽可能早地检测出来。多条针对同一事物发表观点的网络推文的集合被定义成一个事件,本发明对谣言的检测以事件为单位进行,一个事件可能是谣言,也可能是事实。
与现有技术相比,有益效果是:本发明主要基于cnn模型进行优化,提出了一种新的深度学习模型。该模型的优化主要在于两方面,其一是以推文级别的句向量通过特征权重矩阵训练得到组级别的句向量,从而让不同推文具有不同重要性的特点在组向量中得到充分体现,重要性高的推文将在谣言检测中更受关注,重要性低的则反之;其二是引入了时序向量,时序作为检测谣言的一个关键特征,很好地弥补了cnn天然缺乏时序编码能力的缺陷,并且时序向量能够在训练过程中不断调整,自适应数据集。在对社交网络谣言的检测中,无论是在准确性还是时效性方面,本发明都具有比较明显的优势。
附图说明
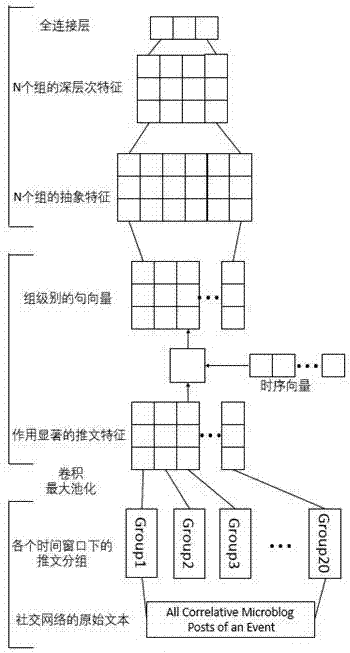
图1为本发明的基本模型结构。
图2为本发明检测社交网络谣言的流程图。
图3为早期谣言检测在微博数据集的对比。
图4为早期谣言检测在推特数据集的对比。
图5为本发明谣言检测效果对比表格。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本专利的限制。
如图1、2所示,本发明的实施包括以下步骤:
收集社交网络数据作为样本数据,对样本数据以事件级别进行整理,样本数据包括谣言样本和真实样本。
对样本数据进行预处理。
用paragraph2vec方法训练推文级别的句向量,构建样本矩阵。
根据按推文发布时间间隔分组的方式重新构建样本矩阵。
根据各个组的最大时间跨度构建时序向量。
利用时序向量重新构建样本矩阵。
采用多层卷积神经网络对样本矩阵进行训练,构建训练模型。
根据训练模型的结果对样本矩阵进行分类,得到事件样本是否为谣言的检测结果。
下面代入具体的社交网络数据对本发明进行详细说明:
从微博和推特两个平台爬取社交网络数据作为样本数据,对样本数据以事件级别进行整理,描述同一事件的所有推文作为一个样本,并将同一事件样本的推文按发布时间进行排序。微博数据集分别有2313条谣言事件和2351条事实事件,推特数据集分别有498条谣言数据和494条非谣言数据。对两个数据集均采用同样的划分方法,选取10%的样本作为验证集,在剩余样本中按3:1划分训练集和测试集。
预处理,包括分词和去除停用词。分词采用python的jieba分词工具进行,停用词主要选取一些特殊符号、无意义的英文单词、常用中文词典中不存在的生僻汉字等。
通过paragraph2vec方法训练语言模型,确定最优参数,构建样本矩阵。样本矩阵的行向量为事件样本的一条推文的句向量,样本矩阵的大小为m*d,则m为事件样本包含的推文数目,d为推文的句向量的维度,d设置为72。
以分组的方式重新构建样本矩阵:根据发布时间间隔均等地将事件样本的所有推文划分为n组,一个组由r*d矩阵表示,其中r为该组包含的推文数目,d为推文的句向量的维度。训练一个1*d的权重矩阵,将组对应的r*d矩阵与k个相同的1*d的权重矩阵进行卷积操作,并通过tanh激活函数得到卷积结果。为使结果归一化,采用池化方法选取每个卷积核卷积后的最大值作为该卷积核下的局部特征,最终得到长度为k的向量,作为该组的组向量。此时样本矩阵的大小为n*k,行向量为组向量,其中n为事件样本包含的组的数目,k为卷积操作使用的权重矩阵的数目。n设置为20,k设置为50,d设置为72。
构建时序向量,给事件样本添加时序信息:以事件样本的每个组中推文的最大时间跨度构建长度为n的时序向量,其中n(即20)为一个样本中组的个数。对向量中的每个值都进行归一化,并将每个值都与一个权重系数相乘,该权重系数会不断训练,以此调整时序向量的每个值。
利用时序向量重新构建样本矩阵:将步骤6得到的时序向量与步骤5的样本矩阵相乘,得到新的大小为n*k(即20*50)的样本矩阵。
基于cnn模型构建多层结构对样本矩阵进行训练。输入层为步骤6得到的样本矩阵,利用不同长度的卷积核对样本矩阵依次卷积,通过relu激活函数后映射后,进行最大池化操作,提取出样本深层次的抽象特征。采用keras作为实现环境。经过多次实验,最终设置cnn的层数为2,在微博数据集上,两层卷积层的卷积核大小均为3,卷积核个数均为20.在推特数据集上,两层卷积层的卷积核大小均为3,卷积核个数均为10。
根据训练模型的结果对测试集数据进行分类,预测其是否为谣言。
本发明最重要的优化在于两方面,其一是以推文级别的句向量通过特征权重矩阵训练得到组级别的句向量,从而让不同推文具有不同重要性的特点在组向量中得到充分体现,重要性高的推文将在谣言检测中更受关注,重要性低的则反之;其二是引入了时序向量,时序作为检测谣言的一个关键特征,很好地弥补了cnn天然缺乏时序编码能力的缺陷,并且时序向量能够在训练过程中不断调整,自适应数据集。目前的谣言检测方法中,cnn的效果无论在准确性还是时效性都是最优的,下面用准确率、精确率、召回率、f1值作为检测结果的评价指标,比较本发明和传统cnn的检测结果,详情参考图5的表1,其中r表示谣言,n表示非谣言,gt-cnn表示本发明用到的模型,g-cnn表示本发明去掉时序向量的一个拆除模型,仅用到了组向量的优化方式。对比可以发现,gt-cnn的效果最好,g-cnn的效果次之,表明本发明采用的优化方法确实有积极作用,组向量的优化方法能够使模型侧重于更重要的推文,时序向量的引入能够增强模型感知推文发布时间先后及时长的特征,从而对谣言的检测有更高的准确性。
图3和图4针对早期谣言检测进行对比,以此判断模型的时效性。横坐标表示推文的最大时间间隔,纵坐标表示准确率。可以看出,本发明提出的模型在时效性方面要明显优于传统cnn模型,能够在更短的时间间隔快速地达到更高的准确率。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!