一种航空发动机剩余寿命的预测方法与流程
本发明属于航空发动机的寿命预测,涉及一种航空发动机性能退化特征的相似性建模与剩余寿命预测技术,具体涉及一种航空发动机剩余寿命的预测方法。
背景技术:
航空发动机是各类航空飞行器的核心设备,其可靠性、维修性、安全性、保障性和测试性(rmsst)一直行业界的关注焦点。剩余寿命预测通过分析设备历史性能退化趋势,预测设备从当前时刻到最终失效的剩余时间。准确的寿命预测可以提高设备rmsst性能、降低维修成本,解决系统维护的经济可承受性。
航空发动机是一个复杂的机电液磁耦合系统,其性能退化是由多个状态变量动态变化且相互耦合的结果,很难获取其精确的物理失效模型。基于数据驱动的技术因其不依赖于设备的物理失效机理,只需要采集、分析发动机的历史和在线监测数据,在实际应用中颇受关注。
数据驱动的寿命预测主流技术是基于退化建模和回归预测,即直接寻找性能退化过程与剩余寿命之间的映射关系。现有技术很多采用线性退化模型建立关系,例如通过对发动机的损伤数据进行线性拟合,利用极大似然估计求解损参数估计值,用测试数据数据更损伤增长模型,然后求剩余时间的概率密度分布函数,取其中值为发动机的剩余寿命,实际上很难直接应用于具有多退化量及非线性退化过程的复杂对象。现有技术还通过多源数据融合先构建一个综合健康度指标并设定失效阈值,然后建立非线性漂移的维纳过程,通过剩余寿命分布进行寿命预测。但是,健康度指标的构建和失效阈值的设定是其中的核心和难点问题,决定了寿命预测技术的准确性和可靠性。另外,现有技术一般假定所有样本的退化特征具有一致或已知的健康初值,有些方法还假定历史样本与待测样本退化特征长度一致,这些假设都为这类技术的实际应用带来诸多困难。
技术实现要素:
发明目的:针对上述现有技术的不足,本发明提供一种航空发动机剩余寿命的预测方法,该方法根据提取航空发动机的退化特征、实现剩余寿命预测的目的。
技术方案:一种航空发动机剩余寿命的预测方法,所述方法包括根据航空发动机性能退化特征的相似性进行建模,包括如下步骤:
(1)多变量退化特征筛选:首先按照退化程度对历史寿命数据的时间序列进行归类,通过relief算法对二类数据筛选退化特征,其特征的权重越大表示该特征对退化的贡献越大,反之贡献小;
(2)退化特征提取:对经relief算法筛选出来的特征通过主成分分析进行变换,得到不含冗余信息的主成分特征,采用kernel平滑的方法对主成分时间序列拟合实际退化轨迹;
(3)相似性评估:根据退化特征表示的轨迹对待测样本和历史样本的退化轨迹进行相似性度量,以相似程度为基础,在历史参考样本中寻找与待测样本相似的退化轨迹片段集合,并计算相似退化轨迹片段的剩余寿命;
(4)模型综合:运用核密度估计的方式求取相似退化轨迹片段剩余寿命的数据分布,根据密度值对相似片段赋予相应的权重,待测样本的寿命预测结果为相似退化轨迹片段剩余寿命的加权和,最后按剩余寿命的分段模型对剩余寿命的最大值进行限制,修正预测结果。
进一步的,步骤(1)所述的归类由早期时间点数据组成退化程度低的一类,末期时间点数据组成退化程度高的作为另一类,设定总时间前5%为早期时间,该期间内的数据退化程度低,去除时间标签并为其贴上类别标签0,总时间最后5%为末期时间,该期间内数据接近失效即退化程度高,去除时间标签并为其贴上类别标签1。
进一步的,步骤(1)具体步骤如下:
(11)取出所有历史发动机退化数据集最初运行的前t0个时间点的观测数据作为性能正常数据,q0={tree0(t)|t=1,2,…,t0},t表示运行时间点;
(12)取出所有历史发动机退化数据集的性能失效数据,所述数据为每个数据集最后t1个时间点的观测数据,
(13)采用relief算法对q0∪q1数据集筛选退化特征集f'={f1,f2,…,fm}。
进一步的,所述步骤(2)具体步骤如下:
(21)对新的特征集f'={f1,f2,…,fm}数据采用主成分分析,将其中存在相关性的退化变量转换成p个线性不相关的主成分特征y=(y1,y2,…,yp)t,
(22)采用kernel平滑的方法对主成分特征的时间序列去噪,消除噪声的干扰,得到退化特征的实际退化轨迹f(t)。
进一步的,所述步骤(3)包括如下步骤:
其中,p表示第p个主成分,σp为其标准差,τ为时延参数,设定最大时延为τmax,记τ*=min(te-ti,τmax),计算待测样本对于l个历史参考样本在τ∈[0,τ*]范围内的相似度
计算待测样本和所有历史参照退化轨迹之间的相似度
r=te-ti-τ+1。
进一步的,所述步骤(4)包括:
(41)采用核密度估计求取相似样本剩余寿命rc的数据分布,核密度估计数据分布的方式为:
其中,k(·)为核函数,要求满足对称性以及∫k(r)dr=1,以均方误差最小为原则选择窗宽h,确定权重函数为概率密度函数,待测样本的剩余寿命预测结果为相似退化轨迹片段的剩余寿命密度加权:
由于这里求取相似样本的剩余寿命分布,基于数据分布的要求,相似样本的数据量应满足n≥20;
(42)采用剩余寿命的分段模型,即先经历性能正常阶段,运行一段时间后发生退化,将剩余寿命划分成两个阶段:常数阶段和线性递减阶段,对剩余寿命的最大值进行限制,假设最大的剩余寿命为rulmax,最终将预测结果修正为:
有益效果:与现有技术相比其显著的效果在于:第一、本发明是采用的是基于数据的数学建模方法,基于航空发动机可测的多变量性能参数进行退化特征筛选与提取,并在退化特征基础上拟合出退化轨迹,能有效描述发动机的退化过程;第二、本发明在样本相似性评估算法中将初始健康状态的不确定性问题转变为退化轨迹片段的时延问题,与实际发动机退化情况更相符;第三、待测样本的剩余寿命由多个最相似的退化轨迹片段的密度加权,避免由单一模型产生的有偏估计,提高预测精度与预测模型的鲁棒性;第四、本发明所提出的方法以数据为支撑,不需要建立复杂的数学模型,从样本间的相似性角度预测剩余寿命,具有一定的实用性。
附图说明
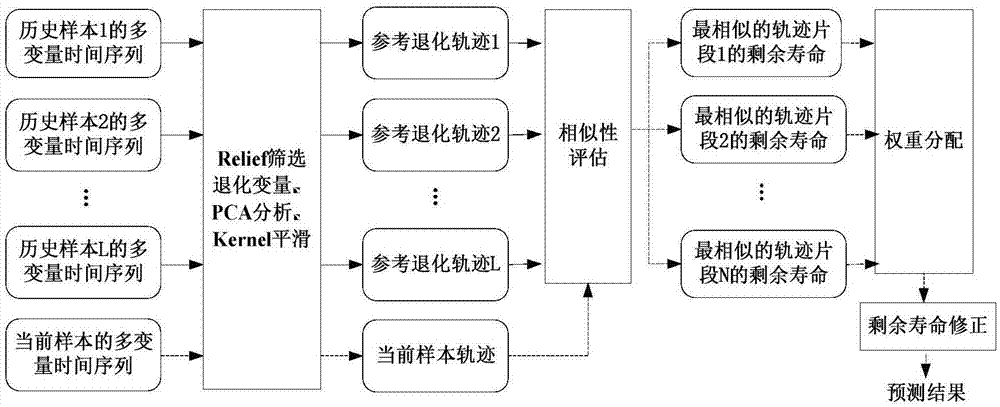
图1是本发明所述预测方法的流程图;
图2是三个历史参考样本的实际退化轨迹图;
图3是本发明相似性评估的示意图;
图4是待测样本的真实寿命与预测结果的对比结果示意图。
具体实施方式
为了详细的说明本发明公开的技术方案,下面结合说明书附图及具体实施例做进一步的阐述。
本发明的一种航空发动机剩余寿命的预测方法,属于航空发动机性能退化特征的相似性建模与剩余寿命预测技术。本发明首先通过relief算法对航空发动机的多维时间序列数据进行退化特征筛选、主成分分析(pca)、kernel平滑提取低维正交退化特征及特征的实际退化轨迹;然后进行退化轨迹相似性匹配,寻找与待测样本轨迹片段最相似的一组历史样本中的退化轨迹片段集合,采用密度加权方法得到待测样本的寿命预测估计值,其方法流程图如图1所示。
本发明结合nasa的c-mapss航空发动机仿真数据集,该数据集分为训练集和测试集,训练集,各自包括100组运行到故障状态的单元,对于每一个单元的运行模拟,经历完整的从正常(具有不同程度的初始磨损和制造变化)到故障状态,记录该过程中每个飞行周期的3个操作条件值和21个传感器测量值,如表1所示。
表1航空发动机传感器数据集描述
具体过程包括如下步骤:
步骤1、多变量退化特征筛选:首先按照退化程度对历史寿命数据的时间序列进行归类,早期时间点数据组成退化程度低的一类,末期时间点数据组成退化程度高的一类。采用relief算法对二类数据筛选退化特征,特征的权重越大,表示该特征对退化的贡献越大,反之,贡献小。
步骤2、退化特征提取:对经relief筛选出来的特征采用pca进行变换,得到不含冗余信息的主成分特征,采用kernel平滑对对主成分时间序列拟合实际退化轨迹。
步骤3、相似性评估:从退化特征表示的轨迹出发,对待测样本和历史样本的退化轨迹进行相似性度量,以相似程度为基础,在历史参考样本中寻找与待测样本相似的退化轨迹片段集合,并计算相似退化轨迹片段的剩余寿命。
步骤4、模型综合:运用核密度估计的方式求取相似退化轨迹片段剩余寿命的数据分布,根据密度值对相似片段赋予相应的权重,待测样本的寿命预测结果为相似退化轨迹片段剩余寿命的加权和,最后按剩余寿命的分段模型对预测结果修正。
1)多变量退化特征筛选:
假设现有历史发动机的退化数据样本量为l,每个样本从开始至失效发生经历e个时间观测点ti(i=1,2,…e),特征变量有m维。ti处的观测值xi由m维特征值构成,即xi=(x1,x2,…,xm)t,而每一维特征变量都是长度为te的时间序列。
首先取出所有历史发动机退化数据集最初运行的前t0个时间点的观测数据作为性能正常数据q0={tree0(t)|t=1,2,…,t0},t表示运行时间点,同理,取出每个数据集最后t1个时间点的观测数据作为性能失效数据,
(11)初始化各特征的权重wi=0;
(12)rj为x中随机抽取的一个样本,j从1循坏到k,寻找以rj为中心,同类样本中u个最近邻样本组成nearhit和不同类中u个最近邻样本组成nearmiss:
(13)对所有的特征值xi(i=1,2,…,m),分别按下面公式计算更新权重:
(14)循环结束,根据wi对特征xi按大小排序。
其中,diff(xi,rj,nearhit)表示rj和nearhit中一个实例对于特征xi的差异,可采用欧式距离,同理diff(xi,rj,nearmiss)表示rj和nearmiss中一个实例对于特征xi的差异。avg(·)表示所有这些样本之间差异的平均值。设置特征权重阈值λ=avg(w),经上述算法筛选出特征权重大于λ的m个特征,新的特征集f'={f1,f2,…,fm}。
2)退化特征提取:
经特征筛选后的数据集有m维特征变量,
(21)首先对x标准化处理(均值归0,方差归1),标准化后矩阵为x*;
(22)求x*协方差矩阵(m*m维)的特征值λj(j=1,2,…,m)和特征向量;
(23)对λj值按从大到小降序排列,即λ1≥λ2≥…≥λm,计算累计贡献率
(24)将x*在
其中,y定义为x的主成分特征,y1称为第一主成分,y2称为第二主成分,依次类推;保留的p个主成分应保留原始数据的绝大多数变化特征(一般阈值取85%以上),并且彼此之间不相关,
(25)定义fl为第l个历史样本的退化模型,fl由主成分特征关于时间的函数表示:
fl:y=f(t)+ε,0≤t≤te(3)
其中,ε为高斯白噪声,f(t)为特征随时间变化的实际退化轨迹,fl模型认为观测到的退化特征,这里为主成分特征,由实际特征退化轨迹加上噪声组成。本发明采用kernel平滑的对退化正交特征提取退化轨迹,对主成分
其中,k(·)为核函数,通常使用高斯核:
上式中ρ为宽度参数,通常采用交叉验证的方式选取合适的宽度参数。低维正交退化特征其退化轨迹的结果如图2所示。
3)相似性评估:
其中,p表示第p个主成分,σp为其标准差,τ为时延参数。基于相似性的剩余寿命预测技术示意图如图3所示,理论上τ的最大值为te-ti,但若当前样本的观测时间点结束的较早,即ti较小,导致te-ti很大。而待测样本与历史样本的初始状态不会差距很大,因此,设定最大时延为τmax,记τ*=min(te-ti,τmax),计算待测样本和第l个历史参考样本在τ∈[0,τ*]范围内的相似度
计算待测样本和所有历史参照退化轨迹之间的相似度
r=te-ti-τ+1(8)
4)模型综合:
采用核密度估计求取相似样本剩余寿命rc的数据分布,核密度估计数据分布的方式为:
k(·)为核函数,要求满足对称性以及∫k(r)dr=1,以均方误差最小为原则选择窗宽h。确定权重函数为概率密度函数,待测样本的剩余寿命预测结果为相似退化轨迹片段的剩余寿命密度加权:
由于这里求取相似样本的剩余寿命分布,基于数据分布的要求,相似样本的数据量应满足n≥20。
采用剩余寿命的分段模型,具体为先经历性能正常阶段,运行一段时间后发生退化。本发明将剩余寿命划分成两个阶段:常数阶段和线性递减阶段,对剩余寿命的最大值进行限制,假设最大的剩余寿命为rulmax,最终将预测结果修正为:
表2待测样本的预测结果
- 还没有人留言评论。精彩留言会获得点赞!