一种基于弱监督学习的视频时序动作检测方法与流程
本发明涉及数字图像处理技术领域,具体为一种基于弱监学习的视频时序动作检测方法。
背景技术:
在过去的几年里,受深度学习在基于图像的分析任务方面的巨大成功的启发,许多模型具有深度学习架构,特别是卷积神经网络(cnn)或递归神经网络(rnn)已被引入到基于视频的动作分析中。karpathy等人首先在视频中采用深度学习进行动作识别,并设计处理单帧或一系列帧的各种深度学习模型。tran等人构建一个c3d模型,该模型在空间-时间视频体中执行3d卷积并整合外观和运动提示以便更好地表示。wang等人提出时间分段网络(tsn),它继承了双流特征提取结构的优点,并利用稀疏采样方案来应对更长的视频剪辑。qiu等人提出伪3d(p3d)残余网络以循环利用3dcnn的现成2d网络。除了处理动作识别之外,还有其他一些工作可以解决行动检测或候选区域生成问题。shou等人利用多级cnn检测网络进行时间动作定位。escorcia等人提出了daps模型,该模型使用rnn编码视频序列,并在单个过程中检索行动建议。lin等人跳过使用单步动作检测器(ssad)的候选区域生成步骤。shou等人设计卷积-解卷积(cdc)网络来确定精确的时序界限。
在过去的几年中,行为分析在视频理解领域引起了很多关注。根据手工特征表示或深度学习模型体系结构,对此问题进行了许多研究。大量现有工作以强监督的方式处理行动分析任务,其中无背景的行动实例的训练数据被手动注释或修剪掉。近年来,一些强监督方法取得了令人满意的结果。然而,如今在越来越大规模的视频数据集上,标注动作实例的精确时间位置是费时和费时的。此外,正如所指出的,与物体边界不同,动作的确切时间范围的定义通常是主观的,并且在不同观察者之间不一致,这可能导致额外的偏差和错误。
为了克服时序动作检测这些限制,利用弱监督方法是合理的选择。现有技术是通过精确的时间标注或剪裁的视频构建深度学习模型,而本发明的模型直接采用未修剪的视频数据进行培训,并且只需要视频级别类别标签。
技术实现要素:
本发明的目的在于一种基于弱监督学习的视频时序动作检测方法。以解决时序动作检测,本发明的模型预测了动作类别以及视频中动作实例的时间位置。在弱监督学习任务中,只有视频级分类标签作为监督信号提供,并且在训练过程中,包含与背景混合的动作实例的视频剪辑不会被修改。
为了实现本发明的目的,具体采取了如下技术方案:
一种基于弱监督学习的视频时序动作检测方法,训练的具体步骤如下:
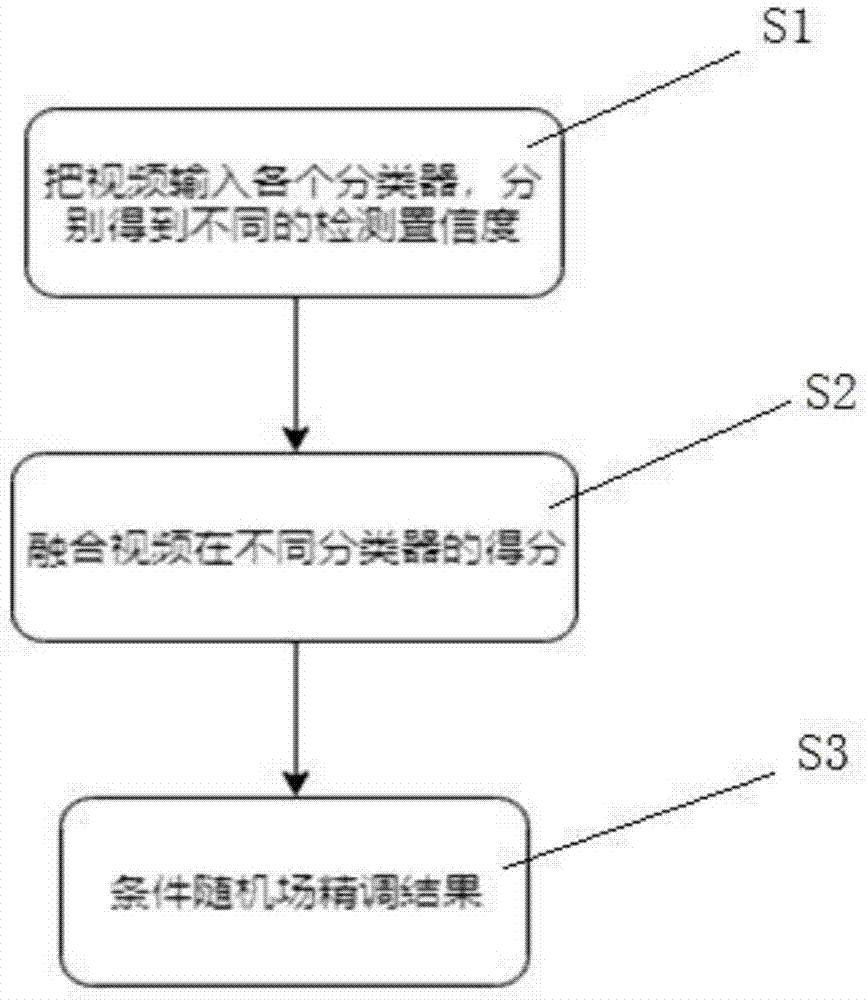
步骤1:把视频输入分类器,分别得到不同的检测置信度;
步骤2:融合视频在不同分类器的得分;
步骤3:条件随机场精调结果。
上述步骤1按照如下顺序进行:
a)把视频划分为不重合的等长片段,以片段为单位抽取特征。
b)分类器根据这些片段的特征,分别对不同的动作类别给出对应的检测置信度。
所述的步骤2按如下顺序进行:
c)给定视频片断,经过初始分类器,得到对应类别得分(详见步骤1);
d)根据得分,擦除视频片断部分内容,得到新视频片断。具体操作为:根据视频片断类别得分,算出其类别的分类概率,然后根据概率高低,随机把对应视频片段,移出训练集。
e)把训练集的所有视频遍历一次,如上述移除部分视频片段,得到新的训练集。
所述的步骤3按如下顺序进行:
f)在新训练集的视频上训练分类器;
g)训练收敛判断,判断为否时,重复步骤第二步和第三步,判断为是时,得到一系列训练好的分类器。
在训练过程中,逐步删除具有高度信任行为发生的片段。通过这样做,来获得了一系列具有各自偏好的分类器,用于不同类型的动作片段。
在使用阶段,反复根据训练出的分类器选择带动作实例的片段,并通过全连接条件随机场(fc-crf)优化融合结果。检测阶段的步骤如下:
步骤4:把待检测视频输入训练出的分类器,得到不同的检测置信度;
步骤5:通过fc-crf优化融合不同的检测置信度;
上述步骤4按照如下顺序进行:
i)把待检测视频划分为不重合的等长片段,以片段为单位抽取特征。
ii)训练好的分类器根据这些片段的特征,分别对不同的动作类别给出对应的检测置信度。
上述步骤5按照如下顺序进行:
iii)根据视频片断类别得分,算出其类别的分类概率。
iv)使用全连接条件随机场fc-crf,以概率图的形式,接受分类概率输入,并根据视频片段的时间轴位置,优化融合结果,输出最终的检测概率。
由于采取了上述的技术手段,本发明具有如下优点和积极效果:
1.本发明提出了一个弱监督模型来检测未修剪视频中的时间动作。该模型通过对视频进行逐步擦除来获得一系列分类器。在测试阶段,通过收集来自逐个分类器的检测结果来应用本发明的模型是方便的。
2.据本发明所知,这是第一个将全连接条件随机场[22](fullyconnectedconditionalramdomfiled,fc-crf)引入时间动作检测任务的工作,它被用于将人类的先验知识和神经网络的输出结合起来。实验结果表明fc-crf在activitynet上提高了20.8%map@0.5的检测性能。
3.本发明对两个具有挑战性的未修剪视频数据集进行了广泛的实验,即activitynet[11]和thumos'14[20];证明本发明方法的检测效果在平均准确率(meanaverageprecision,map)超过其他所有的弱监督时序动作检测方法,甚至比得上某些强监督方法。
为了更清楚地说明本发明的构思和技术方案,下面结合附图,通过具体实施例对本发明做进一步说明。
附图说明
图1为本发明视频时序动作检测方法的流程图;
图2为本发明的训练流程图。
具体实施方式
图1为本发明视频时序动作检测方法的流程图,如图1所示,一种基于弱监督学习的视频时序动作检测方法,包括如下步骤:1、把视频输入各个分类器s1,分别得到不同的检测置信度;2、融合视频在不同分类器的得分s2;3、条件随机场精调结果s3。
图2为本发明的训练流程图,如图2所示,训练流程图包括如下步骤:视频片断经过初始分类器,得到对应类别得分11;根据得分,擦除视频片断部分内容,得到新视频片断12;在新视频上训练分类器13;训练收敛判断,判断为否14,重复步骤12和13,判断为是进入下一步骤15;得到一系列训练好的分类器15。
本发明方法的模型训练过程具体步骤如下:
给定视频
此外,本发明定义权重因子αi,j:
其中δτ定义如下:
其中τ为衰减因子,是一个超参数。擦除概率si,j如下:
si,j(vt)=αi,j(vt)pi,j(vt)
得到第t轮擦除概率si,j(vt)后,本发明如下完成训练过程:
步骤2:模型的使用。
由得到的一系列分类器计算pi,j与αi,j,得到其平均值
其中,标签自变量li与lj由
本发明在activitynet和thumos’14上测试本发明的方法,结果如下。
以下表格中,比较的指标是不同时间轴交并比下的平均查准率,即map(meanaverageprecision),衡量检索出来的视频中在不同时间轴交并比阈值下准确的比例。该指标越大越好。
强监督学习,指的是训练样本的标注信息包括视频类别信息和时序信息。
弱监督学习,指的是训练样本的标注信息仅仅包括视频类别信息。
单阶段。级联、单分类、多分类指各自文献提出的不同方法,对其他参考文献提出其他方法不再一一列举。
表1为activitynet数据集中不同时间轴交并比阈值下的平均查准率,
表2map@tiouonthumos‘14——thumos14数据集不同时间轴交并比阈值下平均查准率。
其中:strong/weaksupervision:强监督/弱监督学习,表格第第一列中各个方法为对应文献与作者提供的方法。
根据本发明的其他实施例,针对所述的技术方案:
1.分类器,可以基于任意神经网络,也可是其与传统特征。
2.全连接条件随机场,可用任意种类的条件随机场代替。
参考文献,简称文献,方括号内为文献序号,例如:[53]为文献53,[59]为文献59,
[1]a.karpathy,g.toderici,s.shetty,t.leung,r.sukthankar,andl.fei-fei.2014.large-scalevideoclassificationwithconvolutionalneuralnetworks.incvpr.1725–1732.
[2]p.bojanowski,r.lajugie,f.r.bach,i.laptev,j.ponce,c.schmid,andj.sivic.2014.weaklysupervisedactionlabelinginvideosunderorderingconstraints.ineccv.628–643.
[3]p.bojanowski,r.lajugie,e.grave,f.bach,i.laptev,j.ponce,andc.schmid.2015.weakly-supervisedalignmentofvideowithtext.iniccv.4462–4470.
[4]a.pinzc.feichtenhoferanda.zisserman.2016.convolutionaltwo-streamnetworkfusionforvideoactionrecognition.incvpr.1933–1941.
[5]joaocarreiraandandrewzisserman.2017.quovadis,actionrecognitionanewmodelandthekineticsdataset.inieeeconferenceoncomputervisionandpatternrecognition.4724–4733.
[6]xiyangdai,bharatsingh,guyuezhang,larrys.davis,andyanqiuchen.2017.temporalcontextnetworkforactivitylocalizationinvideos.inieeeinternationalconferenceoncomputervision.5727–5736.
[7]oneatadan,jakobverbeek,andcordeliaschmid.2014.thelearsubmissionatthumos2014.computervisionandpatternrecognition[cs.cv](2014).
[8]j.donahue,l.annehendricks,s.guadarrama,m.rohrbach,s.venugopalan,k.saenko,andt.darrell.2015.long-termrecurrentconvolutionalnetworksforvisualrecognitionanddescription.incvpr.2625–2634.
[9]v.escorcia,f.c.heilbron,j.c.niebles,andb.ghanem.2016.daps:deepactionproposalsforactionunderstanding.inineuropeanconferenceoncomputervision.768–784.
[10]victorescorcia,fabiancabaheilbron,juancarlosniebles,andbernardghanem.2016.daps:deepactionproposalsforactionunderstanding.ineuropeanconferenceoncomputervision.768–784.
[11]b.ghanemf.cabaheilbron,v.escorciaandj.carlosniebles.2015.activitynet:alarge-scalevideobenchmarkforhumanactivityunderstanding.ininproceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.961–970.
[12]c.gan,c.sun,l.duan,andb.gong.2016.webly-supervisedvideorecognitionbymutuallyvotingforrelevantwebimagesandwebvideoframes.ineccv.849–866.
[13]jiyanggao,zhenhengyang,chensun,kanchen,andramnevatia.2017.turntap:temporalunitregressionnetworkfortemporalactionproposals.arxiv:1703.06189(2017).
[14]a.richardh.kuehneandj.gall.2016.weaklysupervisedlearningofactionsfromtranscripts.corr,abs/1610.02237(2016).
[15]fabiancabaheilbron,waynerbarrios,victorescorcia,andbernardghanem.2017.scc:semanticcontextcascadeforefficientactiondetection.inieeeconferenceoncomputervisionandpatternrecognition.
[16]fabiancabaheilbron,juancarlosniebles,andbernardghanem.2016.fasttem-poralactivityproposalsforefficientdetectionofhumanactionsinuntrimmedvideos.incomputervisionandpatternrecognition.1914–1923.
[17]d.huang,l.fei-fei,andj.c.niebles.2016.connectionisttemporalmodelingforweaklysupervisedactionlabeling.ineccv.137–153.
[18]dineshjayaramanandkristengrauman.2016.slowandsteadyfeatureanalysis:higherordertemporalcoherenceinvideo.incomputervisionandpatternrecognition.3852–3861.
[19]yangqingjia,evanshelhamer,jeffdonahue,sergeykarayev,jonathanlong,rossgirshick,sergioguadarrama,andtrevordarrell.2014.caffe:convolutionalarchitectureforfastfeatureembedding.arxivpreprintarxiv:1408.5093(2014).
[20]y.-g.jiang,j.liu,a.roshanzamir,g.toderici,i.laptev,m.shah,andr.suk-thankar.2014.thumoschallenge:actionrecognitionwithalargenumberofclasses.http://crcv.ucf.edu/thumos14/(2014).
[21]sveborkaraman,lorenzoseidenari,andalbertodelbimbo.[n.d.].fastsaliencybasedpoolingoffisherencodeddensetrajectories.([n.d.]).
[22]p.
[23]y.qiaol.wangandx.tang.2016.mofap:amulti-levelrepresentationforactionrecognition.ijcv119,3(2016),254–271.
[24]ivanlaptevandtonylindeberg.2003.space-timeinterestpoints.in9thinterna-tionalconferenceoncomputervision.432–439.
[25]i.laptev,m.marszalek,c.schmid,andb.rozenfeld.2008.learningrealistichumanactionsfrommovies.incvpr.1–8.
[26]colinlea,michaeld.flynn,renevidal,austinreiter,andgregoryd.hager.2017.temporalconvolutionalnetworksforactionsegmentationanddetection.inieeeconferenceoncomputervisionandpatternrecognition.1003–1012.
[27]tianweilin,xuzhao,andzhengshou.2017.singleshottemporalactiondetection.inacmonmultimediaconference.
[28]l.wang,y.xiong,d.lin,andl.v.gool.2017.untrimmednetsforweaklysuper-visedactionrecognitionanddetection.arxiv:1703.03329(2017).
[29]l.wang,y.xiong,z.wang,y.qiao,d.lin,x.tang,andl.vangool.2016.temporalsegmentnetworks:towardsgoodpracticesfordeepactionrecognition.ineccv.20–36.
[30]cordeliaschmidmarcinmarszalek,ivanlaptev.2009.actionsincontext.incvpr.2929–2936.
[31]hosseinmobahi,ronancollobert,andjasonweston.2009.deeplearningfromtemporalcoherenceinvideo..ininternationalconferenceonmachinelearning,icml2009,montreal,quebec,canada,june.93.
[32]linannan,xudan,yingzhenqiang,lizhihao,andlige.2016.searchingactionpropsoalsviaspatialactionnessestimationandtemporalpathinferenceandtracking.inasianconferenceoncomputervision.384–399.
[33]j.sivicf.r.bacho.duchenne,i.laptevandj.ponce.2009.automaticannotationofhumanactionsinvideo.iniccv.1491–1498.
[34]zhaofanqiu,tingyao,andtaomei.2017.learningspatio-temporalrepresen-tationwithpseudo-3dresidualnetworks.iniccv.
[35]alexanderrichardandjuergengall.2016.temporalactiondetectionusingastatisticallanguagemodel.incomputervisionandpatternrecognition.
[36]sumansaha,gurkirtsingh,michaelsapienza,philiph.s.torr,andfabiocuz-zolin.2016.deeplearningfordetectingmultiplespace-timeactiontubesinvideos.arxiv:1608.01529(2016).
[37]zhengshou,jonathanchan,alirezazareian,kazuyukimiyazawa,andshihfuchang.2017.cdc:convolutional-de-convolutionalnetworksforprecisetem-poralactionlocalizationinuntrimmedvideos.(2017).
[38]zhengshou,dongangwang,andshih-fuchang.2016.temporalactionlo-calizationinuntrimmedvideosviamulti-stagecnns.inproceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.1049–1058.
[39]gunnara.sigurdsson,olgarussakovsky,andabhinavgupta.2017.whatactionsareneededforunderstandinghumanactionsinvideos?corrabs/1708.02696(2017).arxiv:1708.02696http://arxiv.org/abs/1708.02696
[40]karensimonyanandandrewzisserman.2014.two-streamconvolutionalnet-worksforactionrecognitioninvideos.inadvancesinneuralinformationprocess-ingsystems.568–576.
[41]krishnakumarsinghandyongjaelee.2017.hide-and-seek:forcinganet-worktobemeticulousforweakly-supervisedobjectandactionlocalization.arxiv:1704.04232(2017).
[42]s.satkinandm.hebert.2010.modelingthetemporalextentofactions.ineccv.536–548.
[43]chensun,sankethshetty,rahulsukthankar,andramnevatia.2015.temporallocalizationoffine-grainedactionsinvideosbydomaintransferfromwebimages.inacminternationalconferenceonmultimedia.371–380.
[44]dutran,lubomirbourdev,robfergus,lorenzotorresani,andmanoharpaluri.2015.learningspatiotemporalfeatureswith3dconvolutionalnetworks.inproceedingsoftheieeeinternationalconferenceoncomputervision.4489–4497.
[45]hengwangandcordeliaschmid.2013.actionrecognitionwithimprovedtrajectories.inproceedingsoftheieeeinternationalconferenceoncomputervision.3551–3558.
[46]liminwang,yuqiao,andxiaooutang.[n.d.].actionrecognitionanddetectionbycombiningmotionandappearancefeatures.([n.d.]).
[47]l.wang,y.qiao,andx.tang.2015.actionrecognitionwithtrajectory-pooleddeep-convolutionaldescriptors.incvpr.4305–4314.
[48]liminwang,yuanjunxiong,zhewang,yuqiao,dahualin,xiaooutang,andlucvangool.2017.temporalsegmentnetworksforactionrecognitioninvideos.corrabs/1705.02953(2017).arxiv:1705.02953http://arxiv.org/abs/1705.02953
[49]xiaolongwang,rossgirshick,abhinavgupta,andkaiminghe.2017.non-localneuralnetworks.arxivpreprintarxiv:1711.07971(2017).
[50]yunchaowei,jiashifeng,xiaodanliang,ming-mingcheng,yaozhao,andshuichengyan.2017.objectregionminingwithadversarialerasing:asimpleclassificationtosemanticsegmentationapproach.arxiv:1703.08448(2017).
[51]yunchaowei,weixia,junshihuang,bingbingni,jiandong,yaozhao,andshuichengyan.2014.cnn:single-labeltomulti-label.computerscience(2014).
[52]lwiskottandtsejnowski.2002.slowfeatureanalysis:unsupervisedlearningofinvariances.neuralcomputation14,4(2002),715.
[53]yuanjunxiong,yuezhao,liminwang,dahualin,andxiaooutang.2017.apursuitoftemporalaccuracyingeneralactivitydetection.arxiv:1703.02716(2017).
[54]huijuanxu,abirdas,andkatesaenko.2017.r-c3d:regionconvolutional3dnetworkfortemporalactivitydetection.inieeeinternationalconferenceoncomputervision.5794–5803.
[55]serenayeung,olgarussakovsky,gregmori,andlifei-fei.2016.end-to-endlearningofactiondetectionfromframeglimpsesinvideos.inproceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2678–2687.
[56]junyuan,bingbingni,xiaokangyang,andashrafa.kassim.2016.temporalactionlocalizationwithpyramidofscoredistributionfeatures.incomputervisionandpatternrecognition.3093–3102.
[57]zehuanyuan,jonathanc.stroud,tonglu,andjiadeng.2017.temporalactionlocalizationbystructuredmaximalsums.inieeeconferenceoncomputervisionandpatternrecognition.3215–3223.
[58]yimengzhangandtsuhanchen.2012.efficientinferenceforfully-connectedcrfswithstationarity.2012ieeeconferenceoncomputervisionandpatternrecognition(cvpr)00(2012),582–589.
[59]yuezhao,yuanjunxiong,liminwang,zhirongwu,xiaooutang,anddahualin.2017.temporalactiondetectionwithstructuredsegmentnetworks.inieeeinternationalconferenceoncomputervision.2933–2942.
[60]yizhuandshawnnewsam.2016.efficientactiondetectioninuntrimmedvideosviamulti-tasklearning.arxiv:1612.07403(2016)。
- 还没有人留言评论。精彩留言会获得点赞!