一种基于机器学习预测中暑发生的模型及方法与流程
本发明涉及一种基于机器学习预测中暑发生的模型及方法,包含基于随机森林方法的模型建立以及其模型拟合效果的评估,尤其是一种预测不同地区日均中暑发生例数的模型及方法,基于不同地区的气象以及社会经济学等参数,结合机器学习方法建立预测模型,评估未来日均中暑发生例数,属于机器学习应用于高温健康危害的智能预测的技术领域。
背景技术:
近年来,全球范围内的热浪事件形势严峻。根据联合国政府间气候变化专门委员会发布的报告,过去半个世纪中热浪的发生频率呈增加趋势,提示未来几十年中,地表温度将持续增加并伴随极端高温事件频发,其带来的严峻的不良健康效应更是不容忽视。因此,对于热浪及其相关的健康后果的有效预估可以更好的提升人群健康防护,同时减少热浪相关的健康损失。其中,中暑则是热浪事件对应的重要不良健康结局。中暑事件一般发生在机体处于高温、高湿等极端环境中,从而产生身体温度的异常升高。但由于中暑事件报道具有时间延迟性,相关变量具有潜在共线性,这些可能的因素都会影响中暑发生预测的效率。
现有的相关预测模型在可靠性等方面尚存在不足之处,并且缺乏基于实际数据的对应评估。并且,现有的对于极端炎热天气以及其相应不良健康结局的预测模型大多基于气象观测数据,如温度、相对湿度等,但是分析中缺乏社会经济学因素的加入,因而可能带来对于健康效应具有重要影响的指标贡献的缺失。大部分已建立的健康预测系统将死亡率作为健康终点,少数研究将入院率等指标作为健康终点。因此,这些预测模型的代表性受到限制,并且缺乏实际数据以验证模型的有效性。
因此,在我国构建基于多城市的中暑事件发生预测模型并应用于高温中暑事件发生的预测预警是十分必要的。
技术实现要素:
本发明的目的是提供一种基于机器学习预测中暑发生的模型及方法,以解决现有相关预测模型在可靠性较差,及缺乏基于实际数据的对应评估等方面存在的不足;以构建基于多城市的中暑事件发生预测模型并应用于高温中暑事件发生的预测预警。
本发明一种基于机器学习预测中暑发生的模型,
本发明一种基于机器学习预测中暑发生的模型及方法,包含基于随机森林方法的模型建立以及其模型拟合效果的评估。具体步骤如下,
步骤一:建立典型高温城市的高温事件发生数据库
整理中国典型城市的经济学及社会学指标,同时整理历年高温时段的气象因素以及中暑数据,建立我国典型城市的中暑事件数据库。
步骤二:对数据库进行数据匹配及清理
将步骤一建立的中暑事件数据库,进行清理和剔除,得到匹配数据库,具体为:以日均中暑事件发生数量为标准,以前一日、前三日、前五年的温度、湿度等气象因素数据以及社会经济学数据(所有数据项详见表1)为变量,建立匹配数据库。根据《防暑降温措施管理办法》,35℃以上天气定义为高温天气,因此剔除35℃以下的非高温天气对应数据,保证模型建立的代表性和可靠性。同时为保证随机森林建立的有效性,对缺失数据进行剔除。
步骤三:应用boruta算法进行变量筛选
采用boruta特征选择算法,根据特征即各变量重要性判断特征变化后的平均减少精度,以评价每个特征即变量的重要性,迭代逐步删除非重要的特征,最后给出接受或拒绝特征变量的结果,达到模型变量筛选的目的。
步骤四:建立随机森林模型的训练数据集及验证数据集
从步骤三得到的已删除非重要特征的匹配数据库即总数据库中,随机抽取90%的数据作为随机森林模型的训练数据集,将剩余10%的数据设为模型的验证数据集,以后续评估模型的预测效果。
步骤五:确定随机森林参数并建立随机森林模型
在随机森林模型建立中对需要的参数进行确定,即确定模型中特征数量以及树数量。通过十折交叉验证方法将数据随机分为十份,分别依次将九份数据进行分析并用剩余一份数据进行验证,通过r方拟合度最终确定最优的特征数量以及树数量,建立随机森林模型。
步骤六:变量重要性排序
结合步骤五建立的随机森林模型以及确定的特征数量,对模型中变量的重要性进行排序,获得模型变量对模型预测结果的贡献度。
步骤七:模型预测结果评估
应用步骤五中建立的随机森林模型,将步骤四中的验证数据集进行模型预测得到模型预测数据,并将模型预测数据与验证数据集中数据进行比较,评价其相关系数以及线性拟合效果,以评估模型预测能力。
步骤八:应用bland-altman一致性评价方法对模型结果进行评估
将模型预测数据与验证数据集中的中暑实际观测数据通过一致性评价方法进行比较,即利用原始数据的均值与差值,分别将原始数据的均值为横轴、将原始数据的差值为纵轴做散点图,计算并标注差值的均数以及差值的95%分布范围作为一致性界限,评价差值位于该一致性界限以内的点的数量占比。
步骤九:基于随机数据选择比例的敏感性分析
改变随机森林模型训练数据集所占的总数据库比例,即分别从总数据库中随机抽取80%和70%作为训练数据集,其剩余的20%及30%为验证数据集。重复步骤五至步骤八,评价模型建立数据集改变后,模型的预测结果改变的情况,以评价模型的稳健性。
本发明为一种基于机器学习预测中暑发生的模型及方法,较现有技术相比,其优势及效用在于:
1.本发明预测高温时段的中暑发生,该健康终点相较于死亡率和就诊率等指标来讲更能代表高温热浪事件的不良健康效应。
2.应用机器学习中的随机森林模型进行模型搭建,相较于传统的线性回归模型具有较好的拟合预测效果。能够较好的拟合非线性关系变量,提高模型拟合的效果。
3.模型除气象因素外,同时纳入多种经济学及社会学变量,较为全面的对中暑事件的发生进行预测。
4.本发明建立了我国典型城市的高温时段中中暑事件发生的预测模型,可提前对不良健康事件的发生进行预测,能够较好的减少人群健康损伤,降低人群健康相关的经济损失。
5.本发明基于机器学习方法建立的中暑事件发生预测模型,其模型建立方法和思路可进一步应用于其他高温相关的不良健康终点,具有良好的借鉴意义及推广价值。
附图说明
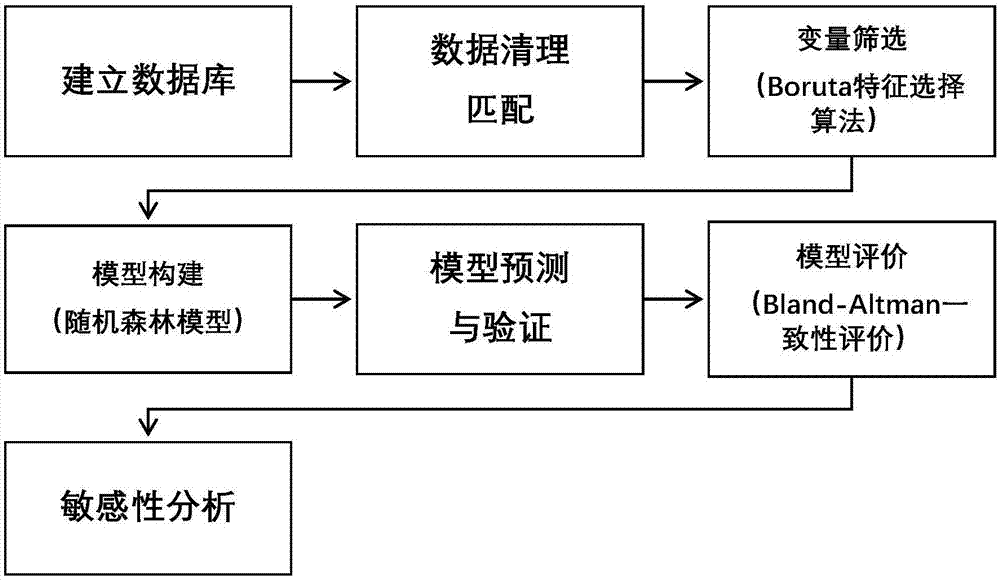
图1所示为本发明基于机器学习预测中暑发生的模型及方法的流程图。
图2所示为本发明基于boruta算法筛选变量的情况。
图3所示为随机森林模型对树数量选择的r方数值。
图4所示为随机森林模型中对特征数量选择的r方数值。
图5所示为随机森林模型各变量重要性排序图。
图6所示为模型观测数据与验证数据之间的线性比对情况。
图7所示为本发明基于bland-altman一致性评价方法对模型结果评价。
具体实施方式
下面结合附图和实施案例,对本发明的技术方案做进一步的说明。
一种基于机器学习预测中暑发生的模型及方法,具体流程如图1所示,包括如下步骤:
步骤一:建立我国历年典型高温城市的高温事件发生数据库
整理中国典型城市的经济学及社会学指标和气象数据,包括城市、日期、当日中暑数量、前一日至五日的平均温度、最高温度、相对湿度等气象因素的短期滞后数据,以及其对应的前5年等长期气象数据均值;另外包括国民生产总值、人口数量、城乡比例、空调及网络普及情况等社会经济学变量。同时加入更新较为及时的百度搜索指数,基于我国最大的百度搜索引擎,以“中暑”为关键词,获得中暑发生事件前一日至前五日的搜索指数,建立我国典型城市的中暑事件数据库。
步骤二:对已有数据进行数据匹配及清理
以匹配日期的中暑事件发生数量为标准,分别将步骤一中获得的前一日、前三日、前五年的气象因素数据以及社会经济学数据(所有数据项详见表1)进行匹配,建立匹配数据库。根据2012年,全国总工会、卫生部、人保部、安监总局联合修订并起草的《防暑降温措施管理办法》,明确规定高于35℃为高温天气,因此筛选35℃以上的高温天气数据建立数据库。基于随机森林模型建立要求,对缺失数据进行剔除,保证模型建立的代表性和可靠性。
表1
步骤三:应用boruta算法进行变量筛选,获得后续纳入模型的变量
进一步采用boruta特征选择算法,通过建立阴影特征增加数据集的随机性,之后根据特征变量改变后的平均减少精度确定变量特征的重要性,如图2所示,将变量特征重要性贡献情况与阴影变量(shadowmin,shadowmean,shadowmax)贡献进行比较,重要性贡献得分高于阴影变量的变量(位于图中虚线右侧)模型表示其通过迭代的特征筛选,将进入后续的模型进一步分析。该步骤可作为模型变量的初步筛选条件,保证进入模型变量与结果变量具有较强的贡献作用。
步骤四:通过随机方法建立随机森林模型的训练数据集及验证数据集
在步骤三得到的已删除非重要特征的匹配数据库即总数据库中,通过随机抽取的方法获得90%的数据作为随机森林模型的训练数据集,并将剩余10%的数据作为模型的验证数据集。其中训练数据集用于随机森林模型参数确定及模型建立,验证数据集用于后续评估模型的预测效果。
步骤五:通过拟合程度确定随机森林参数,基于确定参数建立随机森林模型
采用十折交叉验证方法,将数据库随机分为十等份,分别依次选择其中九份数据建立模型,并用剩余的一份数据进行模型结果评价。建立模型的过程中,分别改变特征的数量,并通过每次模型拟合的r方结果确定最优的特征数值,如图4;用十折交叉验证结合r方的评价方法确定树数量,如图3,基于最优的特征数量以及树数量建立最终的随机森林模型。
步骤六:对随机森林模型中变量进行重要性排序
结合步骤五建立/的随机森林模型,同时结合确定的特征数量,通过纯度的增量情况对随机森林模型中变量的重要性进行排序,如图5,获得纳入模型的变量对模型预测结果的贡献度排序情况。
步骤七:通过验证数据集模型预测结果评估
基于步骤五中建立的模型,应用步骤四中的验证数据集进行模型预测。将实际验证数据集中数据与模型预测数据进行比较,通过相关性评价以及线性拟合方法对模型的预测能力进行评价,如图6,以评估模型预测能力。
步骤八:采用bland-altman一致性评价方法对模型预测结果进行评估
应用bland-altman一致性评价方法,将金标准(即本发明中的实际观测数据)与待测数据(即本发明中的模型预测数值)进行比较,将模型预测数据与验证数据集中的中暑实际观测数据通过一致性评价方法进行比较,利用预测数据与观测数据的均值与差值,将预测数据与观测数据的均值为横轴,将预测数据与实际观测数据的差值为纵轴做散点图,如图7,进一步计算并标注差值的均数以及差值的95%分布范围作为虚线标注一致性界限,计量纳入该一致性界限以内的点的数量占比,以评价模型预测数据与实际观测数据之前的差异情况。
步骤九:基于随机数据选择比例进行模型结果的敏感性分析
通过改变模型训练数据集以及测试数据集所占的总数据库比例,评价模型结果对于训练数据集选择的敏感性。分别从步骤三中的总数据库随机抽取80%和70%作为训练数据集,分别将其剩余的20%及30%作为验证数据集。将上述步骤中的步骤五至步骤八进行重复运算,分别比较训练数据集改变后,模型的预测结果以及实际观测结果之间的差异情况,以评价模型对于训练数据集以及测试数据集的依赖程度和稳健性。
- 还没有人留言评论。精彩留言会获得点赞!