一种复杂任务分解下多维激励契约的构建方法与流程
本发明涉及用户激励领域,具体地说是一种信息不对称情况下考虑复杂任务分解下的激励契约构建方法。
背景技术:
在任务实施过程中,委托方与代理方的信息是不对称的,代理方会基于利益考虑保留其参与任务的努力程度,另外还存在任务难度与代理方能力不匹配的问题。在此情形下,在保证委托方效用做大化的前提下,如何构建激励契约已成为委托方的难题。同时,代理方风险偏好、委托方的能力水平也会对代理方制定激励契约产生影响。
目前常用的激励契约构建方法主要有:
一是从拍卖理论出发,认为激励契约构建的过程是委托方将任务拍卖给代理方的过程,并通过建立模型推导出最优激励契约。但该方法并未考虑信息不对称性情况的情况,代理方会考虑自身利益因素保留努力水平。
二是从信息经济学的委托-代理理论出发,认为任务实施中的契约关系是企业与员工的委托代理关系。主要采用委托-代理理论中的信号传递模型和信号甄别模型,信号传递模型在考虑信息不对称性的情况下,通过契约的构建,激励代理方做出最大的努力,同时保证委托方收益最大化,但并未考虑代理方能力水平对委托方收益和代理方努力的影响;信号甄别模型弥补了信号传递模型的不足,考虑了代理方的能力水平,但并未考虑到任务难度与代理方能力不匹配的问题。
同时,以上激励契约构建方法均未考虑到任务分解情况下委托方和代理方对风险时的态度对委托方效用水平、代理方努力水平的影响,会导致理论方法不符合实际的激励环境,从而不能使激励效果达到最佳。
技术实现要素:
本发明是为了解决上述现有技术存在的不足之处,提出一种复杂任务分解下多维激励契约的构建方法,以期能帮助委托方长期激励代理方参与任务,从而实现委托方效用最大化。
本发明为解决技术问题采用如下技术方案:
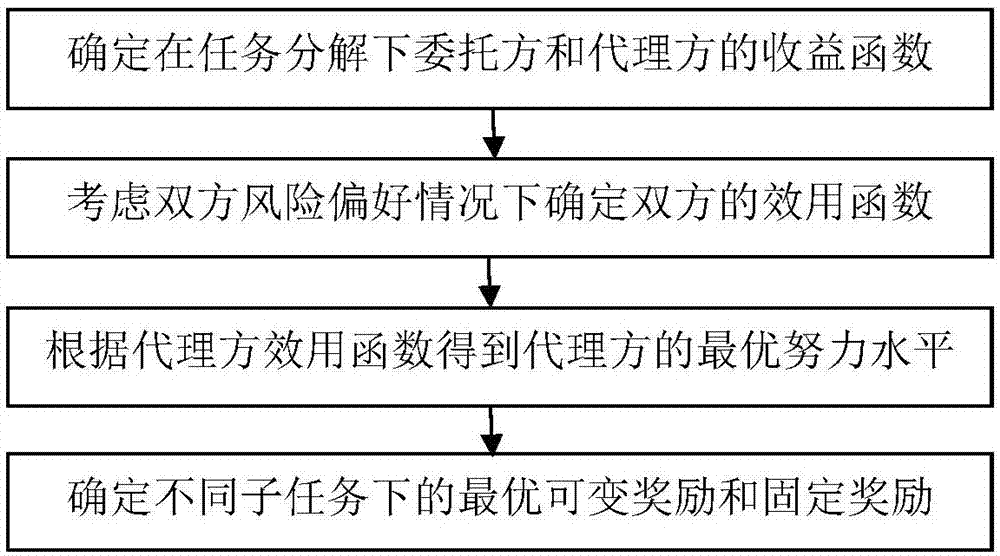
本发明一种复杂任务分解下多维激励契约的构建方法的特点是按如下步骤进行:
步骤1:按如下方式确定在任务分解情况下委托方e和代理方r的收益函数
步骤1.1:令所述委托方e的决策变量为高能力水平代理方rl的固定奖励和可变奖励以及低能力水平代理方rh的固定奖励和可变奖励;
令所述代理方r的决策变量为代理方r的努力水平;
步骤1.2:利用式(1)得到所述委托方e的收益函数πe(βh,βl,th,tl):
πe(βh,βl,th,tl)=p[(i-βht)(ehh+ε)-th]+(1-p)[(i-βlt)(ell+ε)-tl](1)
式(1)中,p为低能力水平代理方rh的比例,表示所有代理方r中受教育水平低于本科学历的代理方r的比例;代理方r的比例i为1×n的单位矩阵,其中n表示由一项任务所分解成的子任务的数量;βh为所述委托方e针对低能力水平代理方rh完成n个子任务后所给予的可变奖励向量,βl为所述委托方e针对高能力水平代理方rl完成n个子任务后所给予的可变奖励向量,th为所述委托方e给予低能力水平代理方rh的固定奖励,tl为所述委托方e给予高能力水平代理方rl的固定奖励,ehh为低能力水平代理方rh选择低水平奖励组合(th,βh)后付出的努力水平向量,ell为高能力水平代理方rl选择高水平奖励组合(tl,βl)后付出的努力水平向量,ehl为低能力水平代理方rh选择高水平奖励组合(tl,βl)后付出的努力水平向量,elh为高能力水平代理方rl选择低水平奖励组合(th,βh)后付出的努力水平向量,ε为影响代理方u努力水平的其他不确定性因素,且ε符合均值为0,方差为σ的分布;
步骤1.3:获得代理方r的收益函数
利用式(2)得到低能力水平代理方rh接受低水平奖励组合(th,βh)的收益函数
利用式(3)得到低能力水平代理方rh接受高水平奖励组合(tl,βl)的收益函数
式(2)和式(3)中,kh表示低能力水平代理方rh的成本系数矩阵;
利用式(4)得到高能力水平代理方rl接受高水平奖励组合(tl,βl)的收益函数
利用式(5)得到高能力水平代理方rl接受低水平奖励组合(th,βh)的收益函数rl(elh):
式(4)和式(5)中,kl表示高能力水平代理方rl的成本系数矩阵;
步骤2:考虑双方风险偏好情况下确定双方的效用函数
步骤2.1:利用式(6)得到风险中性的委托方效用函数ue(βh,βl,th,tl):
ue(βh,βl,th,tl)=p[(i-βht)ehh-th]+(1-p)[(i-βlt)ell-tl](6)
步骤2.2:获得代理方r的效用函数
利用式(7)得到低能力水平代理方rh接受低水平奖励组合(th,βh)的效用函数
利用式(8)得到低能力水平代理方rh接受高水平奖励组合(tl,βl)的效用函数
利用式(9)得到高能力水平代理方rl接受高水平奖励组合(tl,βl)的效用函数
利用式(10)得到高能力水平代理方ul接受低水平奖励组合(th,βh)的效用函数
式(7)、式(8)、式(9)和式(10)中,η表示代理方u的风险规避系数,η>0;
步骤3:根据代理方效用函数
步骤4:利用激励相容约束和参与约束确定不同子任务下的最优可变奖励和固定奖励
步骤4.1:利用式(12)和式(13)确定激励相容约束ic:
步骤4.2:利用式(14)和式(15)确定参与约束ir:
在式(14)和式(15)中,ur表示代理方r不参与任务时所获得的效用;
步骤4.3:利用式(16)和式(17)分别获得低能力水平代理方rh的最优分配比例
式(16)和式(17)中,e表示对角线元素为1的n×n对角阵;
步骤4.4:利用式(18)和式(19)分别获得分别获得低能力水平代理方rh的固定奖励th*和高能力水平代理方rl的固定奖励tl*:
由低水平奖励组合(th,βh)和高水平奖励组合(tl,βl)构成委托方e分别与高能力水平代理方rl和低能力水平代理方rh之间的激励契约。
与现有技术相比,本发明的有益效果在于:
1、本发明针对现有任务实施过程中存在的信息不对称性问题和任务难度与代理方能力不匹配的问题,将一个复杂的任务分解为若干个简单子任务,构建出包含固定奖励和不同子任务下的可变奖励的激励契约,实现了激励契约构建的科学合理性,为委托方提供了一种长期激励代理方参与任务的方法。
2、本发明进一步拓展了委托-代理理论,考虑到了任务难度与代理方能力不匹配的问题,基于任务分解的激励模型拓展了原有理论的应用范围,避免了原有理论未考虑任务分解而产生的局限性,使该理论在复杂任务情况下的应用更具科学性。
3、本发明考虑了代理方风险偏好η对激励契约构建的影响,并将市场上高低能力水平代理方比例p加入供应商效用函数的影响因素中,从而更准确得反映了现实环境下代理方的收益,克服了现有方法未综合考虑代理方风险偏好和代理方能力水平不同的缺陷。
4、本发明可应用于企业对员工参与复杂项目的激励、企业对消费者购买商品行为激励、复杂产品众包活动中发包方对接包方的激励等诸多领域中,应用范围广泛。
附图说明
图1为本发明方法的整体流程图;
图2为本发明激励契约实现过程图。
具体实施方式
本实施例中,参见图2,委托方e和代理方r的激励契约实现过程分为四个阶段,分别为:第一阶段为任务分解。委托方e根据任务的复杂程度,将任务分解为若干个复杂程度较低的子任务,以供代理方r选择;第二阶段为激励契约构建和建立。委托方e针对代理方r的能力水平差异和任务分解,分别构建出针对高能力水平和低能力水平代理方r的契约,契约中包括委托方给予的固定奖励和不同子任务获得市场利润后的可变奖励。代理方r根据自身的能力水平选择相应的激励契约,在期望效用不小于保留效用时选择接受契约,反之拒绝合作;第三阶段为固定奖励执行阶段。委托方e预先支付给代理方r固定奖励,代理方r根据自身效用最大化原则,确定自身努力水平,执行任务;第四阶段为可变奖励执行过程。任务完成后,委托方e根据各子任务所获得的市场利润,根据每个子任务的利润分成比例给予代理方r可变奖励。具体的说,参见图1,一种复杂任务分解下多维激励契约的构建方法是按如下步骤进行:
步骤1:按如下方式确定在任务分解情况下委托方e和代理方r的收益函数
步骤1.1:令委托方e的决策变量为高能力水平代理方rl的固定奖励和可变奖励以及低能力水平代理方rh的固定奖励和可变奖励;
令代理方r的决策变量为代理方r的努力水平;
步骤1.2:利用式(1)得到委托方e的收益函数πe(βh,βl,th,tl):
πe(βh,βl,th,tl)=p[(i-βht)(ehh+ε)-th]+(1-p)[(i-βlt)(ell+ε)-tl](1)
式(1)中,p为低能力水平代理方的比例,表示所有代理方r中受教育水平低于本科学历的代理方r的比例,可通过分析市场历史数据进行估计。代理方r的比例i为1×n的单位矩阵,其中n表示由一项任务所分解成的子任务的数量;βh为委托方e针对低能力水平代理方rh完成n个子任务后所给予的可变奖励向量,βl为委托方e针对高能力水平代理方rl完成n个子任务后所给予的可变奖励向量,且
步骤1.3:获得代理方r的收益函数
利用式(2)得到低能力水平代理方rh接受低水平奖励组合(th,βh)的收益函数
利用式(3)得到低能力水平代理方rh接受高水平奖励组合(tl,βl)的收益函数
式(2)和式(3)中,kh表示低能力水平代理方rh的成本系数矩阵;
利用式(4)得到高能力水平代理方rl接受高水平奖励组合(tl,βl)的收益函数
利用式(5)得到高能力水平代理方rl接受低水平奖励组合(th,βh)的收益函数rl(elh):
式(4)和式(5)中,kl表示高能力水平代理方rl的成本系数矩阵;
步骤2:考虑双方风险偏好情况下确定双方的效用函数
步骤2.1:利用式(6)得到风险中性的委托方效用函数ue(βh,βl,th,tl):
ue(βh,βl,th,tl)=p[(i-βht)ehh-th]+(1-p)[(i-βlt)ell-tl](6)
步骤2.2:获得代理方r的效用函数
利用式(7)得到低能力水平代理方rh接受低水平奖励组合(th,βh)的效用函数
利用式(8)得到低能力水平代理方rh接受高水平奖励组合(tl,βl)的效用函数
利用式(9)得到高能力水平代理方rl接受高水平奖励组合(tl,βl)的效用函数
利用式(10)得到高能力水平代理方ul接受低水平奖励组合(th,βh)的效用函数
式(7)、式(8)、式(9)和式(10)中,η表示代理方u的风险规避系数,η>0。
步骤3:根据代理方效用函数
步骤4:利用激励相容约束和参与约束确定不同子任务下的最优可变奖励和固定奖励
步骤4.1:利用式(12)和式(13)确定激励相容约束ic:
步骤4.2:利用式(14)和式(15)确定参与约束ir:
在式(14)和式(15)中,ur表示代理方r不参与任务时所获得的效用。
步骤4.3:根据科恩-塔克(kkt)条件的计算方法,利用式(16)和式(17)分别获得低能力水平代理方rh的最优分配比例
式(16)和式(17)中的e表示对角线元素为1的n×n对角阵。
步骤4.4:利用式(18)和式(19)分别获得分别获得低能力水平代理方rh的固定奖励th*和高能力水平代理方rl的固定奖励tl*:
由低水平奖励组合(th,βh)和高水平奖励组合(tl,βl)构成委托方e分别与高能力水平代理方rl和低能力水平代理方rh之间的激励契约。
- 还没有人留言评论。精彩留言会获得点赞!