一种裁判文书的检索方法与流程
本发明涉及一种信息检索方法,具体涉及裁判文书的检索方法,属于文本大数据的检索技术领域。
背景技术:
裁判文书,是全国法院在审理刑事、民事、行政等各类案件时得到的审判结果的文本形式,依照法律规定的程序而制作或发布的、具有法律效力或者虽无法律效力但有法律意义的书面文件。随着法律知识的普及和人民法律维权意识的增强,各级法院受理的案件数量逐年累加,截止2018年10月24日现,在中国裁判文书网公开的有裁判文书总量已经超过5400万篇,这给文书的检索工作带来了难度。
裁判文书固定结构可以分为3个部分,即首部、正文、尾部,其中首部包括制作法院、文书名称等内容,正文包括事实、证据等内容,尾部包括署名、日期等内容。但是,裁判文书有民事案件、刑事案件等不同类别,不同类别的文书在结构上略有差异;此外,由于文书撰写者的书写习惯差异、措辞用语差别等一系列因素的影响,文书不一定完全符合文书书写规范。因此,法律从业人员在阅览文书时常常受困于繁复多变的文书风格格式,阅读效率较低。
现有文书检索工具,大部分只能对文书按照标题、案号等关键节点进行检索,只有少部分可以对文书进行全文检索,但是处理的文书集总量较小,面对大规模文书集时检索速度较慢;现有的文书阅览工具,大部分是整篇文书作为一个文档整体阅览,当文书篇幅较长时,无法第一时间找到目标信息。
elasticsearch是一个基于lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于restfulweb接口。elasticsearch是用java开发的,并作为apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎;spring是一个分层的j2ee轻量级开源框架。spring通过控制反转降低模块间耦合度,使得web容器在对象初始化时,不等待对象发起请求就主动将依赖传递给它。另外,spring有着对面向切面编程的良好支持,它分离了应用的业务逻辑与底层业务实现,能够让开发人员进行内聚性的开发;hibernate是一个开源的对象关系映射框架,它对jdbc进行了轻量级的对象封装,在pojo与数据库表之间建立起映射关系。hibernate可以根据统一的hql语句自动生成符合数据库方言的sql语句,自动执行,使得开发人员可以通过面向对象的思想来访问操作数据库。
因此,受到上述现状启发,结合具体需求,本发明以elasticsearch、spring、hibernate等开源技术为基础,裁判文书为数据源,实现了一种裁判文书的检索方法。可将文书按照文书结构分层次、分节点展示,使文书段落结构可视化,提供高效的大数据量的全文检索服务,能够对检索结果进行分页、排序、高亮匹配关键字、分组统计以及筛选,提供文书的批量下载功能。本发明将极大提升法律从业人员的工作效率。
技术实现要素:
本发明是一种裁判文书的检索方法,提供一种裁判文书索引导入方法,包括根据裁判文书内容设置索引字段和类型,根据索引字段创建索引,将大数据量的裁判文书导入索引,提供高效的全文检索,支持多条件组合检索,能够对结果进行分页、排序、高亮匹配关键字、分组统计以及筛选,将文书结构分层次、分节点展示,使文书段落结构可视化,并提供文书的批量下载功能。该方法能显著降低裁判文书的检索难度和阅读难度,极大提升法律从业人员的工作效率。
本发明所述的一种裁判文书的检索方法,其特征在于包含以下步骤:
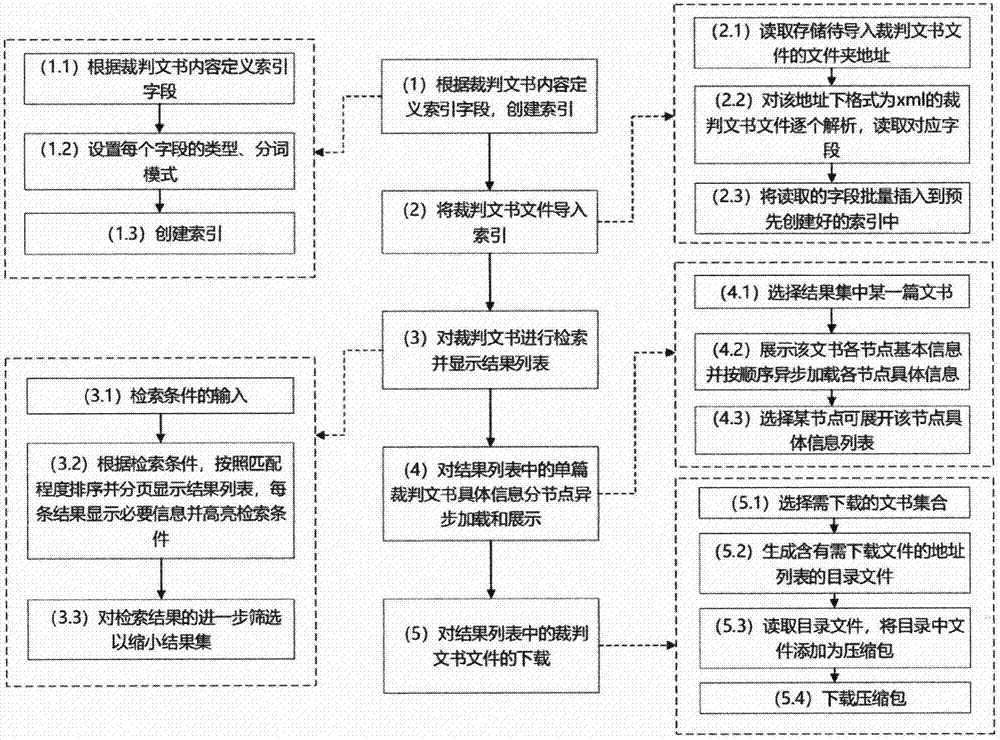
1.一种裁判文书的检索方法,其特征在于包含以下步骤:
步骤(1)根据裁判文书内容定义索引字段,创建索引;
步骤(2)将裁判文书文件导入索引;
步骤(3)对裁判文书进行检索并显示结果列表;
步骤(4)对结果列表中的单篇裁判文书具体信息分节点异步加载和展示;
步骤(5)对结果列表中的裁判文书文件的下载。
2.根据权利要求1所述的一种裁判文书的检索方法,其特征在于步骤(1)中根据裁判文书内容定义索引字段,创建索引。具体子步骤包括:
步骤(1.1)根据裁判文书内容定义索引字段;
步骤(1.2)设置每个字段的类型、分词模式;
步骤(1.3)创建索引。
3.根据权利要求1所述的一种裁判文书的检索方法,其特征在于步骤(2)中将裁判文书文件导入索引,具体子步骤包括:
步骤(2.1)读取存储待导入裁判文书文件的文件夹地址;
步骤(2.2)对该地址下格式为xml的裁判文书文件逐个解析,读取对应字段;
步骤(2.3)将读取的字段批量插入到预先创建好的索引中。
4.根据权利要求1所述的一种裁判文书的检索方法,其特征在于步骤(3)中对裁判文书进行检索并显示结果列表,具体子步骤包括:
步骤(3.1)检索条件的输入;
步骤(3.2)根据检索条件,按照匹配程度排序并分页显示结果列表,每条结果显示必要信息并高亮检索条件;
步骤(3.3)对检索结果的进一步筛选以缩小结果集。
5.根据权利要求1所述的一种裁判文书的检索方法,其特征在于步骤(4)中对结果列表中的单篇裁判文书具体信息分节点异步加载和展示,具体子步骤包括:
步骤(4.1)选择结果集中某一篇文书;
步骤(4.2)展示该文书各节点基本信息并按顺序异步加载各节点具体信息;
步骤(4.3)选择某节点可展开该节点具体信息列表。
6.根据权利要求1所述的一种裁判文书的检索方法,其特征在于步骤(5)中对结果列表中的裁判文书文件的下载,具体子步骤包括:
步骤(5.1)选择需下载的文书集合;
步骤(5.2)生成含有需下载文件的地址列表的目录文件;
步骤(5.3)读取目录文件,将目录中文件添加为压缩包;
步骤(5.4)下载压缩包。
本发明与现有技术相比,其显著优点是:采用分布式搜索引擎,可以有效避免单点故障的产生,分布式集群节点的并行查询使得查询效率大大提高,同时分布式有利于后期服务器的扩展;检索结果按照匹配程度由高到低排序,匹配关键字内容高亮显示,检索过程对用户友好;考虑到检索结果集很大,展示检索结果分页展示,并提供筛选功能,用户可以对检索结果进行更精细的筛选,缩小结果集;提供了文书单篇下载以及批量下载功能,下载格式支持xml与doc,方便检索结果的导出保存;支持用户在线查看文书内容,文书内容采用文书结构分层递进展开,符合用户阅读习惯。
附图说明
图1一种裁判文书的检索方法流程图
图2索引字段设计图
图3文书检索界面全局头部图
图4文书检索界面全局尾部图
具体实施方式
为使本发明的目的、技术方案和优点更加清晰,下面将结合附图及具体实施例对本发明进行详细描述。
本发明的目的在于解决裁判文书检索问题,提出一种裁判文书的检索方法。使用一种裁判文书索引导入方法,包括根据裁判文书内容设置索引字段和类型,根据索引字段创建索引,将大数据量的裁判文书导入索引,提供高效的全文检索,支持多条件组合检索,能够对结果进行分页、排序、高亮匹配关键字、分组统计以及筛选,将文书结构分层次、分节点展示,使文书段落结构可视化,并提供文书的批量下载功能。本发明概括来说主要包括以下步骤:
步骤(1)根据裁判文书内容定义索引字段,创建索引;
步骤(2)将裁判文书文件导入索引;
步骤(3)对裁判文书进行检索并显示结果列表;
步骤(4)对结果列表中的单篇裁判文书具体信息分节点异步加载和展示;
步骤(5)对结果列表中的裁判文书文件的下载。
上述一种裁判文书的检索方法的详细工作流程如图1所示。这里将对上述步骤进行详细描述。
1.由于数据源是裁判文书,因此需要针对裁判文书内容的规律,考虑到检索的关键字,设计相应的索引字段,并创建索引。具体步骤是:
步骤(1.1)根据裁判文书内容定义索引字段。由于裁判文书具有半结构化的特点,根据这种特点,考虑到提升检索效率的关键字,设计以下索引字段:全文、文首、当事人、案件基本情况、裁判分析过程、判决结果、文尾、案号、文书名称、法院名称、法院层级、案件类型、文书类型、审判程序、裁判日期、裁判年份、审判人员、法律依据、案由。
步骤(1.2)设置每个字段的类型、分词模式。为定义的索引字段设置存储类型,包括字符串、数字、日期等;为定义的索引字段设置分词模式,有些字段不需要进行分词,作为一整个词元存储,大部分字段需要进行中文分词后存储。索引字段具体设置情况如图2所示。
步骤(1.3)创建索引。根据字段设计,在索引服务器上输入并执行命令,创建索引。
2.索引创建好后,需要将准备好的裁判文书文件导入索引。具体步骤是:
步骤(2.1)读取存储待导入裁判文书文件的文件夹地址。将需要导入索引的裁判文书文件存放到一个文件夹中,读取该文件夹的地址。
步骤(2.2)对该地址下格式为xml的裁判文书文件逐个解析,读取对应字段。根据定义好的字段,逐个解析裁判文书文件,获取该字段内容。
步骤(2.3)将读取的字段批量插入到预先创建好的索引中。将读取好的字段按照每300篇文书提交一次,导入到索引中,提高插入的效率。
如果需要导入的文件很多,还可构造多个线程,每个线程对不同文件夹进行文书索引导入工作,多个线程并行运行,索引导入效率可以得到很大程度提升。
3.索引导入成功后,就可利用前端网页对裁判文书进行检索,并显示结果列表。具体步骤包括:
步骤(3.1)检索条件的输入。除输入关键词外,还支持用户在输入框输入键值对,如“案由:盗窃罪;文书类型:裁判文书”形式的检索字符串,或者点击高级检索按钮,在下拉框中按条目输入检索信息,然后执行全文检索。
步骤(3.2)根据检索条件,按照匹配程度排序并分页显示结果列表,每条结果显示必要信息并高亮检索条件。检索结果默认按照匹配程度由高到低排序,分页显示,每一页显示5条结果,每条结果显示必要信息,包括文书名称,法院名称,审判程序,裁判日期等,同时使用红色字体高亮显示检索条件匹配内容。用户可以通过点击按照日期排序,使检索结果按照裁判日期升序或降序排序。用户可以通过点击检索结果列表下方的分页导航栏,跳转到具体某一页。排序按钮右方显示一共检索到多少条匹配结果,分页导航栏右方显示共有多少页。
步骤(3.3)对检索结果的进一步筛选以缩小结果集。执行检索并显示检索结果后,检索结果左侧显示对检索结果的分组统计结果,包括分组条目和对应总数统计。分组条件有案由、裁判年份审判程序、法院名称和文书类型,用户可以通过点击分组结果中的条目,对检索结果进行筛选,筛选结果在原来页面上动态更新。
文书检索界面如图3、图4所示,图3中隐私信息已遮盖处理。
4.检索出结果集后,如果需要查看其中一篇文书,可点击进入,该篇裁判文书具体信息将分节点异步加载和展示。具体步骤包括:
步骤(4.1)选择结果集中某一篇文书。可点击标题或内容进入该文书页面。
步骤(4.2)展示该文书各节点基本信息并按顺序异步加载各节点具体信息。首先载入展示文书的案件基本信息,信息按照节点分层展示,然后浏览器异步加载剩余节点信息,包括当事人列表,诉讼人记录,裁判分析过程,判决结果。
步骤(4.3)选择某节点可展开该节点具体信息列表。用户可以通过点击节点首部展开节点或者折叠节点。用户可以点击节点的内部子节点,弹出框显示子节点的列表信息。
5.如果需要保存检索出的裁判文书,可对结果列表中的裁判文书文件进行下载。单篇下载直接点击列表信息里的下载链接即可,下面详细介绍批量下载,具体步骤包括:
步骤(5.1)选择需下载的文书集合。可通过点击复选框或全选链接进行多篇文书选择。
步骤(5.2)生成含有需下载文件的地址列表的目录文件。用户选择好后,服务器端会生成含有待下载文件地址的目录文件。
步骤(5.3)读取目录文件,将目录中文件添加为压缩包。服务器端会根据目录文件,将目录中裁判文书文件添加为一个压缩包。
步骤(5.4)下载压缩包。服务器端向客户端返回压缩包文件下载地址,用户开始下载压缩包。
上面已经参考附图对根据本发明实施的一种裁判文书的检索方法进行了详细描述。本发明具有如下优点:采用分布式搜索引擎,可以发生有效避免单点故障,分布式集群节点的并行查询使得查询效率大大提高,同时分布式有利于后期服务器的扩展;检索结果按照匹配程度由高到低排序,匹配关键字内容高亮显示,检索过程对用户友好;考虑到检索结果集很大,展示检索结果分页展示,并提供筛选功能,用户可以对检索结果进行更精细的筛选,缩小结果集;提供了文书单篇下载以及批量下载功能,下载格式支持xml与doc,方便检索结果的导出保存;支持用户在线查看文书内容,文书内容采用文书结构分层递进展开,符合用户阅读习惯。
需要明确,本发明并不局限于上文所描述并在图中示出的特定配置和处理。并且,为了简明起见,这里省略对已知方法技术的详细描述。当前的实施例在所有方面都被看作是示例性的而非限定性的,本发明的范围由所附权利要求而非上述描述定义,并且,落入权利要求的含义和等同物的范围内的全部改变从而都被包括在本发明的范围之中。
- 还没有人留言评论。精彩留言会获得点赞!