基于FPGA的人脸识别数据处理装置及处理方法与流程
本发明涉及深度学习、卷积技术领域,特别地,涉及一种基于fpga的人脸识别数据处理装置及方法。此外,本发明还涉及一种包括上述基于fpga的人脸识别数据处理装置的处理方法。
背景技术:
随着深度学习方法的应用,基于神经网络的人脸识别技术的识别率已经得到质的提升,目前该项技术已经应用到安防、金融、社保、教育等各个领域。基于神经网络人脸识别技术由于需要大量的乘加运算,所以需要cpu、gpu、aisc等硬件芯片的支持,cpu不适合用于大量乘加运算,效率最低,专有aisc虽然性能高、功耗低但灵活性也低,不适合技术加速迭代的神经网络技术上应用。目前一般采用gpu实现硬件加速,但是gpu板卡本身周围器件多,体积大、功耗大,不适宜应用在终端设备方面,而在服务器级方面也需要有cpu的芯片配合应用。
技术实现要素:
本发明提供了一种基于fpga的人脸识别数据处理装置及数据处理方法,以解决现有的人脸识别效率低、灵活性能低并且需要的周围器件多、体积大的技术问题。
本发明采用的技术方案如下:
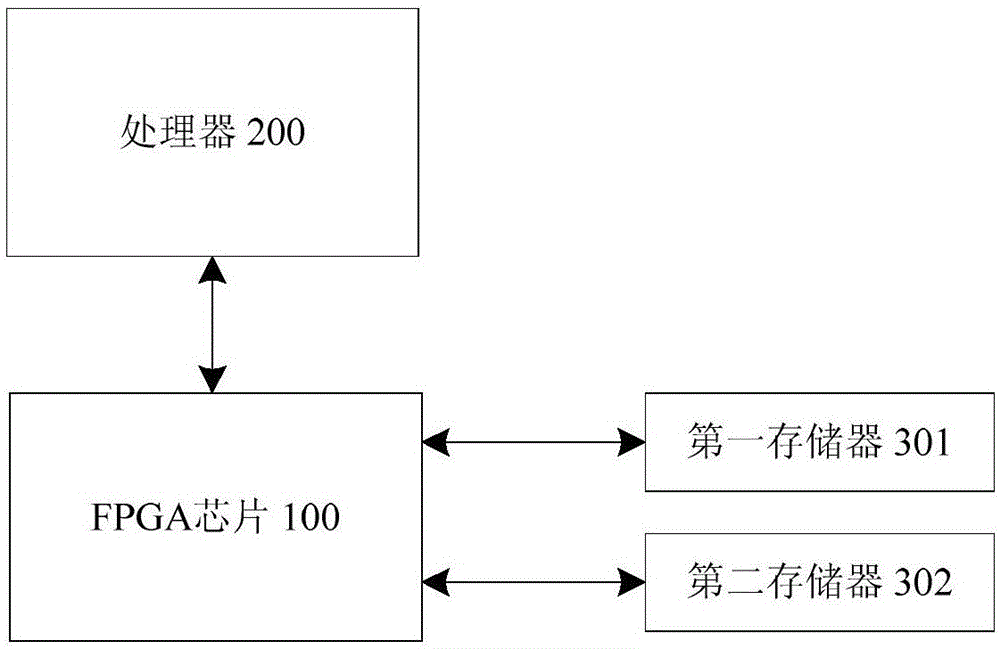
一种基于fpga的人脸识别数据处理装置,包括:第一存储器,用于存储人脸数据;第二存储器,用于存储卷积模板数据;fpga芯片,用于分别从第一存储器和第二存储器中读取数据并进行深度学习从而提取人脸特征值;处理器,与fpga芯片连接,用于将提取出的人脸特征值与预存的人脸数据库进行比对以完成人脸识别;fpga芯片搭载有卷积神经网络模型,用于对读取的数据进行运算,并将运算的中间计算结果存储至第一存储器中。
进一步地,fpga芯片包括:缓存输入模块、提频模块、计算模块、降频模块及缓存输出模块;缓存输入模块用于缓存从第一存储器读取的人脸数据及从第二存储器中读取的卷积模板数据;提频模块用于将缓存输入模块存储的数据输入计算模块,并提升输入数据的时钟频率;计算模块用于对提频模块输入的数据进行卷积和/或池化计算,并得到中间计算结果;降频模块用于输出中间计算结果,并降低输出数据的时钟频率;缓存输出模块用于缓存输出的中间计算结果,并将中间计算结果缓存至第一存储器。
进一步地,缓存输入模块包括:第一缓存输入单元、第二缓存输入单元及第三缓存输入单元;第一缓存单元和第二缓存单元为乒乓缓存结构,用于交替读取人脸数据;第三缓存输入单元用于读取卷积模板数据;缓存输出模块包括:第一缓存输出单元和第二缓存输出单元,第一缓存输出单元和第二缓存输出单元为乒乓存储结构,用于交替输出中间计算结果。
进一步地,提频模块包括:第一fifo缓存器及第二fifo缓存器,第一fifo缓存器分别与第一缓存输入单元和第二缓存输入单元连接;第二fifo缓存器与第三缓存输入单元连接;降频模块包括:第三fifo缓存器,第三缓存器分别与第一缓存输出单元和第二缓存输出单元连接。
进一步地,fpga芯片还包括控制模块,控制模块连接缓存输入模块及缓存输出模块,控制模块用于控制卷积神经网络前m层的中间计算结果存储至第一存储器中,卷积神经网络后n层中间计算结果存储至缓存输入模块。
根据本发明的另一方面,还提供了一种基于fpga的人脸识别数据处理方法,运用于上述权1至5任一项的数据处理装置中,其特征在于,该方法包括以下步骤:
s100:从第一存储器中读取人脸数据缓存到缓存输入模块,从第二存储器中读取卷积模板数据并缓存至缓存输入模块;
s200:利用卷积神经网络模型对缓存输入模块输入的人脸数据和卷积模板数据进行计算,并得到中间计算结果;
s300:将中间计算结果输出至缓存输出模块,并保存至第一存储器以供下次计算使用;
s400:重复上述步骤直至提取出人脸特征值;及
s500:将提取出的人脸特征值与预存的人脸数据库进行比对以完成人脸识别。
进一步地,步骤s200还包括以下步骤:
s201:将缓存输入模块中的人脸数据和卷积模板数据输入计算模块,并同时提升输入数据的时钟频率;
s202:对缓存输入模块输入的数据进行卷积和/或池化计算,并得到中间计算结果;
s203:输出中间计算结果,并同时降低输出数据的时钟频率。
进一步地,步骤s300还包括:将卷积神经网络计算的前面m层的中间计算结果保存至第一存储器以供下次使用;将卷积神经网络计算的后n层的中间计算结果保存至缓存输入模块供下次使用。
进一步地,步骤s100还包括:将从第一存储器中读取的人脸数据通过乒乓操作缓存到第一缓存输入单元或第二缓存输入单元;
将从第二存储器中读取的卷积模板数据缓存到第三缓存输入单元。
进一步地,步骤s300还包括:卷积神经网络的中间计算结果通过乒乓操作输出至第一缓存输出单元或第二缓存输出单元,并将中间计算结果保存至第一存储器或缓存输入模块。
本发明具有以下有益效果:
本发明的基于fpga的人脸识别数据处理装置,包括第一存储器,用于存储人脸数据第二存储器,用于存储卷积模板数据;fpga芯片,用于从第一存储器和第二存储器中读取数据并进行深度学习从而提取人脸特征值;处理器,与fpga芯片连接,用于将提取出的人脸特征值与人脸数据库进行比对以完成人脸识别的处理器;fpga芯片搭载有卷积神经网络模型,用于对读取的数据进行运算,并将运算后的中间计算结果存储至第一存储器中。本发明通过设计两路外部存储器,一路用于人脸数据和中间计算结果的存储,另一路用于卷积模板数据的存储,提高了人脸数据和卷积模板读取的速度,从而缩短了卷积计算的时间,进一步提高了人脸识别的速率。
本发明的基于fpga的人脸识别数据处理方法,通过从第一存储器中读取人脸数据,从第二存储器中读取卷积模板数据,利用fpga搭载的卷积神经网络模型对输入的数据进行计算,并将计算的中间结果存储至第一存储器以供下次利用,并循环上述步骤完成人脸特征值的提取。本发明通过将人脸数据和卷积模板分开存储和读取,提高了人脸数据和卷积模板读取的速度,从而缩短了卷积计算的时间,进一步提高了人脸识别的速率。
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照附图,对本发明作进一步详细的说明。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明优选实施例处理装置的模块示意图;
图2是本发明优选实施例处理装置中fpga芯片的模块示意图;
图3是本发明优选实施例处理装置中fpga芯片的又一模块示意图;
图4是本发明优选实施例处理方法的流程示意图。
附图标号说明:
10、缓存输入模块;20、提频模块;30、计算模块;40、降频模块;50、缓存输出模块;60、控制模块;
100、fpga芯片;200、处理器;301、第一存储器;302、第二存储器;400、运算单元。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
参照图1,本发明的优选实施例提供了一种基于fpga的人脸识别数据处理装置,包括第一存储器301,用于存储人脸数据;第二存储器302,用于存储卷积模板数据;fpga芯片100,用于分别从第一存储器301和第二存储器302中读取数据并进行深度学习从而提取人脸特征值;处理器200,与fpga芯片100连接,用于将提取出的人脸特征值与人脸数据库进行比对以完成人脸识别;fpga芯片100搭载有卷积神经网络模型,用于对读取的数据进行运算,并将运算后的中间计算结果存储至第一存储器301中。
在本实施例中,fpga具有动态可重构的特点,可以进行灵活的编程且设计能效较高,在终端设备上散热更易于设计,体积更小。服务器级别fpga板卡可以取代gpu板卡,而且可以与cpu、arm等各种处理器配合使用,适用性范围更广。本实施例采用两片外部存储器,一片用于存储人脸数据,另一片用于卷积模板数据的存储。处理器200采用cpu或arm板卡,处理器200与fpga芯片100通过pcie完成数据通讯;处理器200将卷积模板数据与需要识别的人脸图像通过pcie接口发送给与fpga连接的第一存储器301和第二存储器302进行缓存。发送完成后,fpga芯片100从第一存储器301和第二存储器302中读取数据并依据采用的卷积神经网络架构进行计算,将提取到的人脸特征值返回给处理器200。由处理器200完成与人脸数据库的比对,从而完成人脸识别。上述数据的交互不限于pcie接口,还可以由网口、usb等接口完成。另外,卷积神经网络是由dsp模块搭建的。
本实施例的基于fpga的人脸识别数据处理装置,通过设计两路存储器,一路用于存储人脸数据和中间计算结果,另一路用于存储卷积模板数据,提高了人脸数据和卷积模板读取的速度,从而缩短了卷积计算的时间,进一步提高了人脸识别的速率。
参照图2,fpga芯片100包括:
缓存输入模块10、提频模块20、计算模块30、降频模块40及缓存输出模块50;
缓存输入模块10用于缓存从第一存储器301读取的人脸数据及从第二存储器302中读取的卷积模板数据;
提频模块20用于将缓存输入模块10中的人脸数据和卷积模板数据输入计算模块30,并同时提升输入数据的时钟频率;
计算模块30用于对提频模块20输入的数据进行卷积和/或池化计算,并得到中间计算结果;
降频模块40用于输出中间计算结果,并降低输出数据的时钟频率;
缓存输出模块50用于缓存输出的中间计算结果,并将中间计算结果保存至第一存储器301。
在本实施例中,卷积神经网络模型是由dsp模块搭建的计算模型。提频模块20为fifo缓存器,用于提升写入fifo缓存器的时钟频率。降频模块40为fifo缓存器,用于降低fifo缓存器输出的时钟频率。因为采用两路存储器,为了使dsp性能跟存储器带宽匹配,对计算部分进行提频处理,从而充分利用dsp的高性能,提高卷积神经网络计算的速度。计算完成后经过fifo缓存器进行降频处理,将时钟频率降低至原始频率,从而使时钟频率与提频前的时钟频率匹配,以更好的完成中间计算结果的输出和缓存。
本实施例的处理装置,通过fifo缓存器提高了卷积和池化计算部分的时钟频率,使dsp模块的计算性能与两路存储器的带宽相匹配,从而优化fpga处理性能,进一步提高人脸识别的速率。
进一步地,缓存输入模块10包括:
第一缓存输入单元、第二缓存输入单元及第三缓存输入单元,第一缓存单元和第二缓存单元为乒乓缓存结构,用于交替读取并缓存人脸数据;第三缓存输入单元用于读取并缓存卷积模板数据;
缓存输出模块50包括:第一缓存输出单元及第二缓存输出单元;第一缓存输出单元和第二缓存输出单元为乒乓缓存结构,用于交替缓存输出卷积神经网络的计算结果;
在本实施例中,提频模块20包括:第一fifo缓存器,第二fifo缓存器,第一缓存单元与第二缓存单元均与第一fifo缓存器连接,第三缓存输入单元与第二fifo缓存器连接。
通过第一缓存单元和第二缓存单元均与第一fifo存储器连接,使第一缓存单元和第二缓存单元的数据同时输出,一方面,使传输数据连续不间断;另一方面提高了数据的传输速度,在本实施例中,为了使dsp性能更好的跟存储器的带宽匹配,通过fifo将时钟频率提升至原来的2倍。
第三缓存输入单元与第二fifo缓存器连接,用于缓存每层的卷积模板数据,卷积模板数据是一直输出,而且是不变的。在本实施例中,通过第二fifo存储器,将时钟频率也提升2倍。
可选地,降频模块40包括第三fifo存储器,经过卷积或池化计算后的结果经第三fifo缓存器使时钟频率降低至原始频率,并与第一缓存输出单元和第二缓存输出单元连接。中间计算结果经第一缓存输出单元和第二缓存输出单元交替缓存输出,然后将计算的中间结果保存至第一存储器301,以供下次计算使用。
在本实施例中,参照图2,虚线表示的运算单元400外部的时钟频率为x,运算单元400内的时钟频率为2x。在运算单元400内部计算部分的时钟频率均被提升2倍,计算完成后,将时钟频率降低至原始频率,并将计算的中间计算结果缓存至第一存储器301中。
本实施例的基于fpga的人脸识别数据处理装置,通过设置两路存储器,分别存储人脸数据和卷积模板参数,并且充分利用dsp模块的性能,使计算部分的时钟频率是其他数据操作部分的2倍,使存储器的带宽和dsp模块的计算性能达到最优匹配,从而使fpga芯片100的处理性能达到最优。
本发明基于fpga的人脸识别数据处理装置处理数据的步骤为:首先从第一存储器301中读取人脸数据经乒乓操作缓存至第一缓存输入单元和第二缓存输入单元;从第二存储器302中读取卷积模板数据,并存储至第三缓存输入单元。将第一缓存输入单元、第二缓存输入单元读取的数据经第一fifo将时钟频率提升至2倍,第三缓存输入单元的读取数据经第二fifo缓存器将时钟频率提升至2倍,然后进行卷积或池化计算;计算完成后,经第三fifo缓存器将时钟频率降低至原始频率,并将中间计算结果经乒乓操作缓存输出至第一缓存输出单元和第二缓存输出单元;然后将计算的中间结果保存至第一存储器301保存以供下一次计算使用。循环上述步骤完成整个卷积神经网络架构的计算,直至计算到最后一层提取到人脸特征值。
优选地,fpga芯片100还包括控制模块60,控制模块60连接缓存输入模块10和缓存输出模块50,用于控制数据的缓存和输出。控制模块60还用于控制卷积神经网络前m层计算的中间结果存储至第一存储器301中,卷积神经网络后n层计算的中间计算结果存储至缓存输入模块10。
在本实施例中,针对上述实现架构和通过分析人脸识别卷积神经网络结构可以对数据处理方案进一步优化。神经网络架构的特点是神经元由原始点不断向外扩散,简单概括来说就是模板参数由初始层较少到随着层数增加而翻倍增多,但是计算的数据量是逐渐减小的趋势。假设前面m层计算的中间结果数据量较大,卷积模板参数数据量较小,而后面的n层计算的中间结果数据量较小,但模板参数数据量很大。
参照图3,优化后的流程就是,因为前m层计算的中间结果数据量大,fpga芯片100片内的缓存的输入单元空间有限,所以将神经网络前m层计算的中间结果存储至第一存储器301中,后面n层因为中间计算结果数据量小,可将神经网络后n层的中间计算结果存储至fpga片内的缓存输入单元内,而不是缓存到第一存储器301内,第一存储器301和第二存储器302均用于存储卷积模板数据,所以针对后n层计算,提高了卷积中间计算结果的读取速度,而且同时从第一存储器和第二存储器读取卷积模板数据,增加了数据传输带宽,从而缩短了每次卷积计算的时间,进一步提升了人脸识别的处理速度。
本发明基于fpga的人脸识别数据处理装置优化后的处理步骤为:首先从第一存储器301中读取人脸数据,从第二存储器302中读取卷积模板数据并缓存至缓存输入模块10内,然后利用dsp搭建的卷积神经网络模型对输入的人脸数据和卷积模板数据进行计算,并将卷积神经网络计算的前m层中间计算结果存储至第一存储器301中,把卷积神经网络计算的后n层中间计算结果存储至片内的缓存输入模块10中,而卷积模板数据是从第一储存器301和第二储存器302读取,最终提取出人脸特征值。
本实施例的基于fpga的人脸识别数据处理装置,根据神经网络架构特点,充分利用外部存储器的带宽资源,将神经网络前m层和后n层分别用不同的存储方式和卷积模板数据调用方式,加快数据调度和计算能力,使基于fpga人脸识别性能得到了较大提升。另外,由于fpga的灵活重构性可以根据算法的不断优化而快速的设计实现,所以相对来说用fpga芯片100实现人脸识别相比采用其他芯片性价比更高。
参照图4,本发明还提供一种基于fpga的人脸识别数据处理方法,该方法应用与上述人脸识别数据处理装置中,该方法包括以下步骤:
s100:首先从第一存储器301中读取人脸数据,从第二存储器302中读取卷积模板数据并将读取的人脸数据和卷积模板数据缓存到缓存输入模块10,
s200:根据缓存的人脸数据和卷积模板数据,利用卷积神经网络模型进行计算,并得到中间计算结果;
s300:将中间计算结果输出至缓存输出区,并将中间计算结果保存至第一存储器301以供下次计算使用;
s400:重复上述步骤直至提取出人脸特征值;及
s500:将提取出的人脸特征值与预存的人脸数据库进行比对以完成人脸识别。
在本实施例中,卷积神经网络模型是由dsp模块搭建的模型,本实施例的基于fpga的人脸识别数据处理方法,通过重复上述步骤完成整个卷积神经网络架构的计算,最终提取出人脸特征值。将提取的人脸特征值与预存的人脸数据库进行比对完成人脸识别。本发明通过将人脸数据和卷积模板数据分开存储和读取,提高了人脸数据和卷积模板读取的速度,从而缩短了卷积计算的时间,进一步提高了人脸识别的速率。
在本发明的又一实施例中,步骤s200还包括:
s201:将缓存输入模块10中的人脸数据和卷积模板数据输入计算模块30,并同时提升输入数据的时钟频率;
s202:对输入的数据进行卷积和/或池化计算,并得到中间计算结果;
s203:输出中间计算结果,并同时降低输出数据的时钟频率。
本实施例的处理方法,通过提升输入数据的时钟频率,然后进行卷积和/或池化计算,得到中间计算结果,然后输出中间计算结果并降低输出数据的时钟频率。本实施例的处理方法,通过提升计算部分的时钟频率,提高了卷积池化计算部分的运算速度,使dsp模块的计算性能与两路存储器的带宽相匹配,从而优化fpga处理性能。
在本发明的其他实施例中,步骤s100还包括:将从第一存储器301中读取的人脸数据通过乒乓操作缓存到第一缓存输入单元或第二缓存输入单元;将从第二存储器302中读取的卷积模板数据缓存到第三缓存输入单元。步骤s300还包括:中间计算结果通过乒乓操作输出至第一缓存输出区或第二缓存输出区。
在本实施例的处理方法,通过乒乓操作来读取和缓存数据,保证了数据输入和输出的完整性,并且提高了数据的传输速率。
在本发明的又一实施例中,步骤s300还包括:将卷积神经网络计算的前面m层的中间计算结果保存至第一存储器301以供下次使用;将卷积神经网络计算的后面n层的中间计算结果保存至缓存输入模块10供下次使用。
在本实施例中,根据神经网络架构的特性,前m层计算的中间结果数据量大,fpga芯片100片内的缓存输入单元空间有限,所以将神经网络前m层计算的中间结果存储至第一存储器301中,后面n层因为中间结果数据量小,可将神经网络后m层计算的中间结果存储至fpga片内的缓存输入单元内,而不是缓存到第一存储器301内,第一存储器301和第二存储器302均用于存储卷积模板数据。所以针对后n层计算,提高了卷积中间计算结果和卷积模板数据的读取速度,从而缩短了每次卷积计算的时间,进一步提升了人脸识别的处理速度。
在本发明的又一实施例中,步骤s300还包括:中间计算结果通过乒乓操作输出至第一缓存输出区或第二缓存输出区,并将中间计算结果进一步保存至第一存储器301或缓存输入模块10中。在本实施例中,前m层的中间计算结果保存至第一存储器301中,后n层的中间计算结果保存至缓存输入模块10中。
本发明的处理方法,根据神经网络架构特点,充分利用外部存储器的带宽资源,将神经网络前m层和后n层分别用不同的存储方式和卷积模板数据调用方式,加快数据调度和计算能力,使基于fpga人脸识别性能得到了较大提升。另外,由于fpga的灵活重构性可以根据算法的不断优化而快速的设计实现,所以相对来说用fpga芯片实现人脸识别相比采用其他芯片性价比更高。经过实验得知,采用优化后的处理流程,在不增加任何在资源的情况下,处理速率可提高约40%。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!