一种基于FPGA和深度学习的毫米波成像危险物品检测方法与流程
本发明涉及一种毫米波成像危险物品检测技术,尤其涉及的是一种基于fpga和深度学习的毫米波成像危险物品检测方法。
背景技术:
毫米波泛指频率位于红外和微波之间,在26.5-300ghz波段内的电磁波,它处于宏观电子学向微观光子学的过渡阶段。与微波相比,毫米波拥有更高的带宽特性和分辨能力;与光波相比,毫米波拥有更高的能量转换效率,可以透过一定物质的表面成像;与x射线相比,其电子能量较低,不会对人体组织造成伤害。主动式毫米波成像利用毫米波发射器件对被检人员及携带的物品进行照射,然后用接收天线收集反射或者散射的回波信号,并由信号处理系统进行成像。目前,公共安检口岸如机场、码头、地铁站、火车站等的主要安检设备有x射线人体检查仪和金属探测门等,前者透视能力强但辐射剂量大,会对人体造成极大的伤害;后者主要探测入检人员身上携带的金属物件,对其他危险物品没有响应。使用主动毫米波成像检查仪可以透过衣物对人体直接检查,检测内容不仅包括金属还包括任何会吸收毫米波的物件如毒品、爆炸物以及陶瓷刀等危险物品。
目前基于毫米波成像的安检系统一方面通过检测员的人眼识别危险品,一方面通过架设高性能服务器,利用服务器中的高性能cpu和gpu运行图像识别算法来识别危险品。通过检测员的人眼识别危险品的辨别方法一方面对安检人员的要求较高,安检人员的素质和工作状态直接影响危险物品的检出率;另一方面检测速度较慢,在客流量较大的海关、地铁等场所应用时,显现出很大的不足。依靠cpu和gpu运行图像识别算法来检测危险物品,一方面由于性能不足,无法满足实时检测的要求;另一方面架设服务器需要额外的场地空间,给安检设备的结构设计和现场部署造成麻烦。
使用图像检测来检测毫米波图像中的危险物品,可以实现自动识别,降低了人为因素的影响,提高了检测的速度。传统的图像检测方法依靠被检查物的位置特征、面积特征、颜色特征、形状特征等来实现检测,准确度较差。深度学习神经网络模模仿人类大脑的层次感知系统,通过多层网络学习到本质特征,准确度高于传统的图像检测方法。而且,传统检测方法随着数据量增大检测性能会趋于饱和,深度学习的方法则不同,当数据越来越多时,检测性能会越来越好。
技术实现要素:
本发明所要解决的技术问题在于:现有技术无法精准提取危险物品的不规则外形轮廓,提供了一种基于fpga和深度学习的毫米波成像危险物品检测方法。
本发明是通过以下技术方案解决上述技术问题的,本发明包括以下步骤:
(1)获取毫米波成像图片,标识出图片中的危险物品;
(2)构建检测危险物品的深度学习网络模型,利用标注好的毫米波成像图片进行模型训练,得到训练好的检测模型;
(3)将训练好的检测模型加载到fpga平台的检测系统中;
(4)使用fpga检测待测的毫米波图像;
(5)利用训练好的检测模型对采集的待测的毫米波图像进行检测;
(6)如果待测的图像中含有危险物品,则标记危险物品类别,进行报警,同时标记危险物品的不规则轮廓位置坐标。
所述步骤(2)包括以下步骤:
(21)标注出每张含有危险物品的图像上的危险物品的轮廓,将标注好的图像作为深度学习网络的输入;
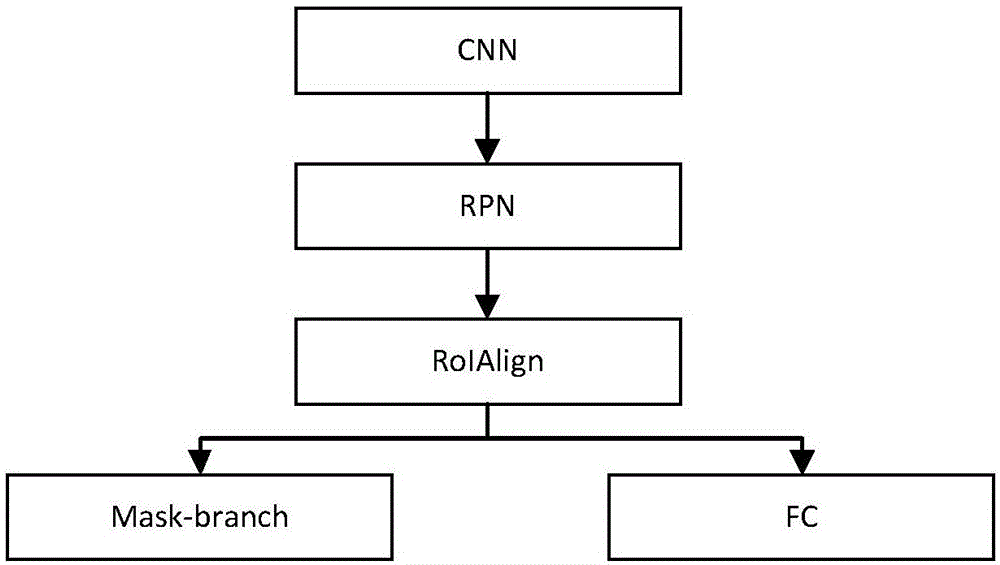
(22)对每张图像利用卷积神经网络cnn进行特征提取,卷积神经网络包括5层卷积层和3层最大池化层,得到特征图;
(23)根据区域建议网络rpn生成特征图的候选区域;
(24)对候选区域利用roialign提取出固定尺寸的特征图;
(25)对特征图利用全连接层fc进行分类和得到包围盒;
(26)对特征图利用mask分支生成掩码,最终得到危险物品在图像上所占的像素;
(27)根据图像中的危险物品标注,对特征图中的包围盒进行目标检测过程的边框回归操作,得到检测物体在图像中的位置和置信度,并相应调整异物检测模型。
所述步骤(21)中,使用图像语义分割标注工具labelme进行标注。将每一张图像里的所有危险物品的轮廓分别标注出来,作为深度学习网络的输入。
所述步骤(22)中,所述卷积神经网络对输入的图像数据做归一化处理,将图像大小调整为224*224,对每张图像利用8层卷积神经网络做特征提取:
第一层为卷积层,初始化一张224*224大小的图像,经过大小为11*11、步长为2的卷积滤波器之后,生成110*110*32,进入下一层;
第二层为最大池化层,大小为3*3、步长为2,得到55*55*32的输出,进入第三层;
第三层为卷积层,卷积核为5*5,步长为2,得到26*26*86的输出;
第四层为最大池化层,大小为3*3、步长为2,得到13*13*32的输出;
第五层为卷积层,卷积核大小为3*3、步长为1,得到13*13*128的输出;
第六层为卷积层,和第五层的卷积核大小和步长相同,得到13*13*128的输出;
第七层为卷积层,和第五层的卷积核大小和步长相同,得到13*13*128的输出;
第八层为最大池化层,大小为3*3、步长为2,得到13*13*128的特征图。
所述步骤(23)中,区域建议网络rpn采用anchor机制,原始图像经过卷积神经网络生成的特征图上,每个点都对应原图上的9个anchor,经过区域建议网络rpn生成这9个anchor的四个坐标的回归和目标的概率值。
所述步骤(24)中,roialign的流程为,遍历每一个候选区域,将候选区域分割成k*k个单元,候选区域的浮点数边界和每个单元的边界都不做量化,在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
所述步骤(26)中,生成掩码的mask分支是一个全卷积网络fcn,输入为roialign生成的固定大小的特征图,输出为它们的掩码,mask分支包括4个卷积层,最后生成大小28*28*80的二值掩码图。
所述步骤(27)中,fpga在初始化完成后,加载训练好的深度学习网络模型参数;当待检测人员进入毫米波检测区域时,毫米波成像设备对人体反射的毫米波进行成像,并进行实时数据采集,每幅图像的尺寸大小为200*512像素;fpga将图像数据作为输入,传递给fpga中的深度学习程序框架,利用已加载的网络模型参数进行危险物品检测;如果当前处理的图像中存在危险物品,则标记危险物品的类别,开始报警,同时得到图像中掩码值为1的区域,用以标识危险物品的位置坐标;如果不存在危险物品,则继续处理下一幅图像。
本发明相比现有技术具有以下优点:本发明是基于fpga平台利用maskr-cnn物体检测框架训练出来的深度神经网络模型进行实时异物检测;基于maskr-cnn物体检测框架训练出来的深度神经网络模型相较于传统的检测算法,更加精确;相较于其它模型训练出的深度神经网络可以准确的提取出危险物品的不规则外形轮廓,而不仅仅是物品的包围盒。基于fpga平台相对于传统的cpu有更好的并发性和更快的处理速度;相对于传统的gpu有更细的并发操作粒度和并发执行效率;相对于专用集成电路芯片有更好的功能可定制性优势。
附图说明
图1是maskr-cnn深度学习网络模型的结构框图;
图2是本发明的流程图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图1和图2所示,本实施例包括离线模型训练和在线检测两个部分,描述如下:
一、离线训练深度学习网络模型部分:
使用图像语义分割标注工具labelme,将每一张图像里的所有危险物品的轮廓分别标注出来,作为深度学习网络的输入。
用于提取特征的卷积神经网络共有8层,包含5个卷积层和3个最大池化层。对输入的图像数据做归一化处理,将图像大小调整为224*224,对每张图像利用8层卷积神经网络做特征提取。
初始化的一张224*224大小的图像,经过大小为11*11、步长为2的卷积滤波器之后,生成110*110*32,进入下一层。
第二层为最大池化层,大小为3*3、步长为2,得到55*55*32的输出,进入第三层。
第三层为卷积层,卷积核为5*5,步长为2,得到26*26*86的输出。
第四层为最大池化层,大小为3*3、步长为2,得到13*13*32的输出。
第五层为卷积层,卷积核大小为3*3、步长为1,得到13*13*128的输出。
第六层为卷积层,和第五层的卷积核大小和步长相同,得到13*13*128的输出。
第七层为卷积层,和第五层的卷积核大小和步长相同,得到13*13*128的输出。
第八层为最大池化层,大小为3*3、步长为2,得到13*13*128的特征图。
根据特征图生成候选区域的区域建议网络rpn包括三个卷积层,第一层的卷积核大小为3*3,输出的结果分为两路,分别进入两个卷积核大小为1*1的卷积层,生成候选区域是目标的概率和候选区域的包围盒坐标。rpn采用anchor机制,原始图像经过卷积神经网络生成的特征图上,每个点都对应原图上的9个anchor,经过区域建议网络rpn生成这9个anchor的四个坐标的回归和为目标的概率值。
由于候选区域的位置是浮点数,而池化后的特征图要求尺寸固定,因此需要采用roialign提取固定尺寸的特征图,以便进行后续的分类和包围框回归操作。roialign的流程为,遍历每一个候选区域,将候选区域分割成k*k个单元,候选区域的浮点数边界和每个单元的边界都不做量化,在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
根据固定尺寸的特征图,利用softmax对候选区域进行分别,同时再次回归计算获得包围盒的最终精确位置。
生成掩码的mask分支是一个全卷积网络fcn,输入为roialign生成的固定大小的特征图,输出为它们的掩码。mask分支包括4个卷积层,最后生成大小28*28*80的二值掩码图。掩码的小尺寸属性有助于保持掩码分支网络的轻量性。在训练过程中,我们将真实的掩码缩小为28x28来计算损失函数,在推断过程中,将预测的掩码放大为roi边框的尺寸以给出最终的掩膜结果,每个目标有一个掩膜。
二、基于fpga的在线检测部分:
基于fpga的毫米波成像危险物品检测部分主要是将离线训练生成的深度学习网络模型应用到实时危险物品检测中。fpga在初始化完成后,加载训练好的深度学习网络模型参数;当待检测人员进入毫米波检测区域时,毫米波成像设备对人体反射的毫米波进行成像,并进行实时数据采集,每幅图像的尺寸大小为200*512像素;fpga将图像数据作为输入,传递给fpga中的深度学习程序框架,利用已加载的网络模型参数进行危险物品检测;如果当前处理的图像中存在危险物品,则标记危险物品的类别,开始报警,同时得到图像中掩码值为1的区域,用以标识危险物品的位置坐标。如果不存在危险物品,则继续处理下一幅图像。
深度学习神经网络具有检出率高,检测速度快的优势,但是计算量巨大,采用嵌入式处理器或者服务器cpu无法达到实时检测的效果。为了减轻fpga的运算负荷,将毫米波成像算法部分放在独立于危险物品检测的一片fpga中进行,网络模型中的前向传递运算放在另一片fpga中进行,从而实现了深度学习网络的加速运行,使得整个危险物品的检测过程具有实时性。
用于毫米波成像的fpga经过成像算法后,向后端fpga输出固定图像尺寸的毫米波图像,图像分辨率为200*512;图像通过高速总线输出到后端fpga进行网络模型运算。所选目标检测网络的前向传递过程主要为多通道的卷积运算构成,利用fpga的并发运算优势,让每个通道的卷积运算同时进行,从而加速神经网络执行过程。
fpga平台相对于传统的cpu有更好的并发性和更快的处理速度;相对于传统的gpu有更细的并发操作粒度和并发执行效率;相对于专用集成电路芯片有更好的功能可定制性优势。
分别使用传统的图像检测算法和基于其它模型的深度学习网络进行了测试,效果均不如本发明的采用深度学习网络的技术方案。具体而言,将基于maskr-cnn深度网络模型检测危险物品替换为传统的图像检测算法,检出率明显下降;将基于maskr-cnn深度网络模型检测危险物品替换为其它深度学习网络,无法精确描述危险物品的不规则轮廓,从而增加了人工判图的工作量。
对采用fpga平台和采用传统处理器平台运行基于maskr-cnn深度网络模型检测危险物品进行了对比,使用基于传统处理器的平台,其检测时间远长于基于fpga平台。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!