一种快速精确的单阶段目标检测方法及装置与流程
本发明属于目标检测技术领域,具体涉及一种快速精确的单阶段目标检测方法及装置。
背景技术:
目标检测作为计算机视觉领域的关键技术,一直是具有挑战性的研究热点。viola和jone于2001年提出的viola-jones算法首次在计算资源有限的情况下实现了实时的人脸检测。2005年,dalal与triggs提出的hog行人检测器拓展了viola-jones算法的检测领域。felzenszwalb等人提出的可变形部件模型dmp(deformablepartbasedmodel)以及其后续优化算法连续三年获得voc目标检测挑战赛(thepascalvisualobjectclasseschallenge)的冠军,代表了当时基于手工设计特征的检测器的最高水平。然而,基于手工设计特征的目标检测器在目标区域选择上策略针对性差,窗口计算冗余量大,尤其针对环境多样性变化和遮挡问题没有很好的鲁棒性。因此,早期的目标检测算法难以达到实用的要求,陷入发展停滞期。
得益于卷积神经网络的迅速发展,girshick于2014年提出了区域卷积网络结构(r-cnn:regionswithcnnfeatures),标志着目标检测摆脱了缓慢发展的困境,进入了新的发展阶段。此后涌现出的基于深度学习的目标检测算法大致可分为两类:两阶段分类回归系列算法与单阶段回归系列算法。
r-cnn主要计算流程由两部分组成,分别是类别分类和位置回归。此后,在r-cnn基础上提出的spp-net、fastrcnn、fasterrcnn、fpn等算法均将检测任务分成分类问题和位置回归两类问题。因此,这类算法统称为两阶段分类回归系列算法。随着目标检测数据集的逐渐丰富和网络训练技巧的不断优化,该类系列算法的平均检测准确度得到迅速提升。两阶段分类回归系列算法虽然能取得70%以上的平均准确率,但其网络结构过于复杂,不仅导致前期的网络训练时间较长,也致使网络参数量较大,难以保证实时性。为获得较高的检测帧率,两阶段分类回归系列算法需要苛刻的gpu硬件配置条件,且不利于将算法移植到移动终端。提高检测准确度的同时,保证检测速度日益成为工业界的实际需求。为兼顾精度与速度,单阶段回归系列算法应运而生。
redmon等人于2016年提出的端到端一体化网络yolov1在voc07(pascalvoc2007)上取得66.4%的平均准确度,虽然平均检测精度低于大部分两阶段分类回归算法,但检测处理速度最高可达155fps。此后,为提高检测精度,陆续出现yolo9000、ssd、yolov3等单阶段算法。这类算法将类别分类问题与位置回归问题统一成一个回归计算问题,与r-cnn等算法形成鲜明对比。为进一步提高平均准确度,liu等人在ssd的基础上先后提出dssd、dosd等优化的ssd类算法。在检测流程中,ssd类算法采用锚箱在多层特征图上以不同比例与尺寸的建议框进行回归计算,一次性检测物体的类别与位置。ssd类算法相对两阶段算法计算简单且参数量较少,能够在一定程度上兼顾检测精度与速度。
ssd中的多层次回归计算思想优于单一特征图上的目标检测,利于消除yolov1中存在的近邻目标检测“竞争”现象,dssd等算法继承了ssd多层回归计算的特点,通过改进高层框架结构以提升平均准确度。然而,ssd多层回归计算在结构上存在回归特征图(检测所基于的多层特征图层)层与层之间相对独立的情况。虽然通过高层结构改造可在一定程度上提升平均准确率,但改造后的复杂结构又影响了检测速度,难以保证实时性。
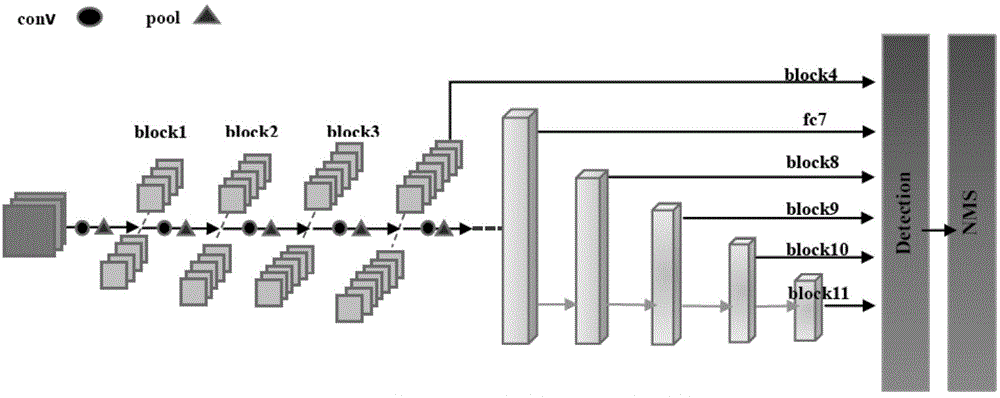
现有底层网络为vgg结构的ssd网络框架示意图如图1所示,其高层网络结构中的多层回归特征图分别为block4、fc7、block8、block9、block10、block11,其中block4、fc7、block8、block9、block10、block11分别表示神经网络中每个卷积命名区域中最后的特征图层。图1中,圆表示卷积(conv),采用大小为“3×3”、步长为(1,1)的两层卷积核,即2kernal3×3_s1;三角形表示池化(pool),采用大小为“2×2”、步长为(2,2)的一层最大池化,即pool2×2_s2。上述六层特征图层共生成多个特定比例与尺寸的建议框,每个框架检测出的结果经过nms(非极大值抑制)筛选,得出最终检测的位置和类别。ssd可通过各种复杂交叉的底层网络改善处理过程中容易丢失空间相关信息的问题以提高特征的多样性。然而,复杂的高层模型可以提高精度却难以保证实时的处理速度。由图1可见,ssd高层网络结构的回归特征图中层与层之间相对独立,致使多层回归计算难于统一,例如图1中block8与block10之间仅用单链的四层卷积层间接地通过block9进行联系,各自通过回归计算出类别与位置,无法直接建立两层之间的有效联系,不利于目标检测在网络中的协调统一。
技术实现要素:
本发明所要解决的技术问题是:为解决ssd系列算法存在的层间回归计算相对独立的问题,在保证目标检测实时性的同时,进一步提高检测精度,基于ssd构造了一种快速精确的单阶段目标检测方法及装置,摒弃复杂的底层与高层网络结构的改进方法,仅通过优化主流结构和增加一种轻量级的分流结构(即shunt结构)增强高层网络多层回归特征图之间的协调性与统一性。
本发明解决上述技术问题所采用的技术方案为:一种快速精确的单阶段目标检测方法,包括:
搭建fa-ssd网络,该fa-ssd网络包括底层网络和高层网络;
使用所述的底层网络提取输入图像的特征;
使用所述的高层网络对所述的底层网络输出的特征进行最大池化和异步卷积分解操作,得到多个卷积特征;
合并得到的多个卷积特征并在回归特征图上计算出类别与位置;
通过nms进行阈值筛选,得出置信度最高的目标。
进一步地,该方法中,所述的底层网络为单链无分支的卷积神经网络结构,所述的高层网络包括主流结构、分流结构一、分流结构二、分流结构三和分流结构四,所述的分流结构一、分流结构二、分流结构三和分流结构四分别基于不同方向上不同步长的异步卷积策略进行两次异步卷积分解构造得到两层异步卷积分解的卷积层,每次异步卷积分解操作过程为:首先采用在b方向上大小为3步长为2、a方向上大小为1步长为1的异步卷积核对输入特征图进行卷积处理,在b方向实现降维;之后采用在a方向上大小为3步长为2、b方向上大小为1步长为1的异步卷积核对上一步卷积处理的输出结果进行卷积处理,提取特征的同时在两个方向上实现降维。
进一步地,该方法中:
所述的主流结构包括依次连接且结构相同的通道一、通道二、通道三、通道四和通道五,所述的通道一、通道二、通道三、通道四和通道五均包括沿通道方向依次连接的卷积层一、卷积层二、池化层和卷积层三,所述的卷积层一的大小为1×1、步长为1,所述的卷积层二的大小为3×3、步长为1,所述的池化层的大小为2×2、步长为2,所述的卷积层三的大小为1×1、步长为1;
所述的通道一的卷积层一的输入端和所述的分流结构一的输入端分别与所述的底层网络的输出端连接,所述的底层网络的输出端输出卷积特征一,所述的通道一的池化层的输出端与所述的分流结构一的输出端交融后与所述的通道一的卷积层三的输入端连接,所述的通道一的卷积层三的输出端输出卷积特征二;
所述的通道二的卷积层一的输入端和所述的分流结构二的输入端分别与所述的通道一的卷积层三的输出端连接,所述的通道二的卷积层三的输出端输出卷积特征三,所述的分流结构二的输出端与所述的通道三的池化层的输出端交融后与所述的通道三的卷积层三的输入端连接,所述的通道三的卷积层三的输出端输出卷积特征四;
所述的通道三的卷积层一的输入端和所述的分流结构三的输入端分别与所述的通道二的卷积层三的输出端连接,所述的分流结构三的输出端与所述的通道四的池化层的输出端交融后与所述的通道四的卷积层三的输入端连接,所述的通道四的卷积层三的输出端输出卷积特征五;
所述的通道四的卷积层一的输入端和所述的分流结构四的输入端分别与所述的通道三的卷积层三的输出端连接,所述的分流结构四的输出端与所述的通道五的池化层的输出端交融后与所述的通道五的卷积层三的输入端连接,所述的通道五的卷积层三的输出端输出卷积特征六;
所述的卷积特征一、卷积特征二、卷积特征三、卷积特征四、卷积特征五和卷积特征六在通道方向上合并后,在回归特征图上计算出类别与位置,通过nms进行阈值筛选,得出置信度最高的目标。
本发明使用高层网络对底层网络输出的特征进行最大池化和异步卷积分解操作,在降低特征图维度的同时,有利于空间相关信息的传递,可改善空间相关信息缺失的问题,提升特征的多样性和差异性。
进一步地,本发明搭建的fa-ssd网络,采用优化的高层网络主流结构,并在主流结构中增加分流结构(即shunt结构)。该高层网络基于异步卷积分解与分流结构得到,在其主流结构中用最大池化对特征图进行降维,在其分流结构中用异步卷积分解对特征图进行降维,通过这两种降维方式降维,在保留空间相关信息的同时提高了特征的多样性。
本发明摒弃复杂的底层与高层网络结构的改进方法,仅通过优化主流结构和增加一种轻量级的分流结构(即shunt结构)增强高层网络多层回归特征图之间的协调性与统一性。增加分流结构并优化主流结构后,目标检测结果的平均准确度达到80.5%,相比ssd提高3.3%,相比dssd321提高了1.9%,同时在一块1080ti显卡上取得30fps的平均处理速度。
fa-ssd在保证实时性检测的同时,其平均准确度在未采用mscoco数据库扩充训练数据的情况下,便超过ssd类算法。
一种快速精确的单阶段目标检测装置,包括:
fa-ssd网络模块,该fa-ssd网络模块包括底层网络模块和高层网络模块,其中,
底层网络模块,用于提取输入图像的特征;
高层网络模块,用于对所述的底层网络模块输出的特征进行最大池化和异步卷积分解操作,得到多个卷积特征;
特征处理模块,用于合并得到的多个卷积特征并在回归特征图上计算出类别与位置;
nms阈值筛选模块,用于对在回归特征图上计算得到的类别与位置进行阈值筛选,得出置信度最高的目标。
进一步地,该装置中,所述的底层网络模块为单链无分支的卷积神经网络结构,所述的高层网络模块包括主流结构、分流结构一、分流结构二、分流结构三和分流结构四,所述的分流结构一、分流结构二、分流结构三和分流结构四分别基于不同方向上不同步长的异步卷积策略进行两次异步卷积分解构造得到两层异步卷积分解的卷积层,每次异步卷积分解操作过程为:首先采用在b方向上大小为3步长为2、a方向上大小为1步长为1的异步卷积核对输入特征图进行卷积处理,在b方向实现降维;之后采用在a方向上大小为3步长为2、b方向上大小为1步长为1的异步卷积核对上一步卷积处理的输出结果进行卷积处理,提取特征的同时在两个方向上实现降维。
进一步地,该装置中:
所述的主流结构包括依次连接且结构相同的通道一、通道二、通道三、通道四和通道五,所述的通道一、通道二、通道三、通道四和通道五均包括沿通道方向依次连接的卷积层一、卷积层二、池化层和卷积层三,所述的卷积层一的大小为1×1、步长为1,所述的卷积层二的大小为3×3、步长为1,所述的池化层的大小为2×2、步长为2,所述的卷积层三的大小为1×1、步长为1;
所述的通道一的卷积层一的输入端和所述的分流结构一的输入端分别与所述的底层网络模块的输出端连接,所述的底层网络模块的输出端输出卷积特征一,所述的通道一的池化层的输出端与所述的分流结构一的输出端交融后与所述的通道一的卷积层三的输入端连接,所述的通道一的卷积层三的输出端输出卷积特征二;
所述的通道二的卷积层一的输入端和所述的分流结构二的输入端分别与所述的通道一的卷积层三的输出端连接,所述的通道二的卷积层三的输出端输出卷积特征三,所述的分流结构二的输出端与所述的通道三的池化层的输出端交融后与所述的通道三的卷积层三的输入端连接,所述的通道三的卷积层三的输出端输出卷积特征四;
所述的通道三的卷积层一的输入端和所述的分流结构三的输入端分别与所述的通道二的卷积层三的输出端连接,所述的分流结构三的输出端与所述的通道四的池化层的输出端交融后与所述的通道四的卷积层三的输入端连接,所述的通道四的卷积层三的输出端输出卷积特征五;
所述的通道四的卷积层一的输入端和所述的分流结构四的输入端分别与所述的通道三的卷积层三的输出端连接,所述的分流结构四的输出端与所述的通道五的池化层的输出端交融后与所述的通道五的卷积层三的输入端连接,所述的通道五的卷积层三的输出端输出卷积特征六;
所述的卷积特征一、卷积特征二、卷积特征三、卷积特征四、卷积特征五和卷积特征六在通道方向上由所述的特征处理模块合并后,在回归特征图上计算出类别与位置,通过所述的nms阈值筛选模块进行阈值筛选,得出置信度最高的目标。
一种快速精确的单阶段目标检测装置,包括:
处理器;
存储器,其上存储有计算机程序,所述的计算机程序被所述的处理器运行时执行本发明的任一项快速精确的单阶段目标检测方法。
与现有技术相比,本发明的优点在于:
(1)使用高层网络对底层网络输出的特征进行最大池化和异步卷积分解操作,在降低特征图维度的同时,有利于空间相关信息的传递,可改善空间相关信息缺失的问题,提升特征的多样性和差异性。
(2)基于不同方向上不同步长的异步卷积策略,通过两次异步卷积分解构造得到两层异步卷积分解的卷积层,与ssd采用一层卷积对特征图降维相比,可在不增加计算量的情况下,提高提取特征的非线性表达能力。
(3)基于异步卷积策略构造了一种分流结构,从主流结构中分出包含两层采用异步卷积分解的卷积层组成的分流结构,同时该分流结构与主流结构实现特征交融,解决了各层回归计算相对独立的问题,增强了多层回归计算之间的统一性与协调性。在分流结构中采用异步卷积分解构造的卷积层可在降低特征图维度的同时,增加特征图之间的交融过程,改善空间相关信息缺失的问题。
(4)优化了高层网络的主流结构,首先在主流结构各通道上大小为3×3、步长为1的卷积层(即卷积层二)与大小为1×1、步长为1的卷积层(即卷积层三)之间增加一层大小为2×2、步长为2的池化层,从而在主流结构中使用池化降维方式,同时在分流结构中使用卷积降维方式,提升特征的多样性;然后在每次交融的特征图后增加一层大小为1×1、步长为1的卷积层(即卷积层三)以提升回归特征图之间的卷积深度,扩大各层回归特征图间的特征差异性。
(5)本发明摒弃复杂的底层与高层网络结构的改进方法,仅通过优化主流结构和增加一种轻量级的分流结构(即shunt结构)增强高层网络多层回归特征图之间的协调性与统一性。增加分流结构并优化主流结构后,目标检测结果的平均准确度达到80.5%,相比ssd提高3.3%,相比dssd321提高了1.9%,同时在一块1080ti显卡上取得30fps的平均处理速度。
(6)fa-ssd在保证实时性检测的同时,其平均准确度在未采用mscoco数据库扩充训练数据的情况下,便超过ssd类算法。
附图说明
图1为现有底层网络为vgg结构的ssd网络框架示意图;
图2为本发明中fa-ssd网络框架示意图;
图3为本发明异步卷积分解操作中的一层的操作过程示意图;
图4为本发明中回归特征图层间的shunt结构连接示意图;
图5为本发明中优化后的主流结构中单个通道的结构示意图;
图6为对本发明搭建的fa-ssd网络结构训练时增广产生的数据实例;
图7(a)和图7(b)为对本发明搭建的fa-ssd网络结构训练过程中的损失变化曲线;
图8为不同迭代次数下的平均准确度的变化对比图;
图9为不同数目的shunt结构对检测精度的影响对比图;
图10(a)~图10(c)为搭建的三种高层网络结构的局部图;
图11为在相同条件下对图10所示三种网络进行训练后,在voc2007test上的检测结果对比图;
图12(a)~图12(h)为fa-ssd300在voc07test上的部分结果展示。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明中fa-ssd网络的底层网络基于卷积神经网络(即vgg),高层网络为多层次的回归计算结构。本发明中fa-ssd网络框架示意图如图2所示。图2中,虚线框为高层网络的主流结构,虚线框左侧为底层网络,虚线框内有依次连接且结构相同的通道一、通道二、通道三、通道四和通道五。图2中,圆、三角形和高度大于宽度的棱形分别表示卷积操作(conv)、池化操作(pool)和回归特征图层之间的网络结构(nn),高度小于宽度的棱形和对立三角表示shunt结构和特征图层通道方向上的交融操作(concat)。图2中特征图层的命名方式与图1相同,高层网络的回归特征图分别为block4、fc7、block8、block9、block10、block11,其中block4、fc7、block8、block9、block10、block11分别表示神经网络中每个卷积命名区域中最后的特征图层。通道一位于底层网络的输出端与fc7之间,通道二位于fc7与block8之间,通道三位于block8与block9之间,通道四位于block9与block10之间,通道五位于block10与block11之间。高层网络结构用两种方式对特征图进行降维,分别是shunt结构中的异步卷积分解和主流结构中的最大池化。fa-ssd网络中共有4个shunt结构,分别是shunt0、shunt1、shunt2和shunt3(即分别是分流结构一、分流结构二、分流结构三和分流结构四),用两种连接方式增加回归特征图层之间的联系。四个shunt结构的整体连接方式如图2所示。最后在六个回归特征图上计算出类别与位置,通过nms进行一定阈值的筛选,得出置信度最高的目标。
一、搭建的fa-ssd网络结构包含以下三部分内容
(1)异步卷积分解
本发明基于不同方向上不同步长的异步卷积策略,通过两次异步卷积分解构造得到两层异步卷积分解的卷积层,图3为本发明异步卷积分解操作中的一层的操作过程示意图,其中kernel3×1s(2,1)表示大小为“3×1”的卷积核,在b方向上大小与步长分别为3和2,在a方向上的大小和步长分别为1和1。输入特征图在经过一层异步卷积分解的卷积处理后,仅在b方向实现降维。再次经过卷积核kernal1×3s(1,2)的卷积处理后,特征图在a与b方向分别降低了维度,类似pool2×2_s2对特征图进行处理的效果。与ssd高层网络中的一层kernal3×3s(2,2)卷积结构相比,kernal3×1_s(2,1)与kernal1×3_s(1,2)的结合在未增加计算量的同时,提高了网络的非线性表达能力。与pool2×2_s2的最大池化层相比,两层异步卷积分解的卷积处理既在卷积核大小为“3”方向上保证了像素之间的重叠,也在步长为“2”方向上保证了感受野之间的重叠,保留了足够的空间相关信息。
(2)shunt结构
本发明中回归特征图层间的shunt结构连接示意图如图4所示。结合异步卷积分解操作,并结合分支交融结构,对主流结构采用两种方式进行连接。从图4可以看出,block4与fc7之间的网络深度大于回归特征图之间的深度,且fc7层宽度最大。为节省计算量、提高回归特征图间的联系,shunt0起始于回归特征图层block4,直接与回归特征图层fc7进行交融,与其它shunt结构无直接联系。而shunt1与shunt2之间以及shunt2与shunt3之间存在交错连接,例如shunt1的输出端(即交融端)位于shunt2的输入端(即分流端)之后,shunt2则可跨越block9直接连接block8与block10。如果shunt2起始端位于shunt1交融位置之后,则会因为特征交融导致特征图通道的倍增,而增加计算量。交融后的特征图在通道方向上合并,之后经过batchnormalization处理及回归计算得出类别与位置信息。通过上述两种shunt连接方式增强高层网络中多层次的回归计算之间的联系,相当于增强了高层网络结构的协调性和统一性。
(3)高层网络结构的优化及计算过程
图5展示了本发明中优化后的主流结构中单个通道的结构示意图(即优化后的主流结构中的局部结构示意图)。本申请发明人实验搭建了多种网络结构并进行了训练及测试,对比试验结果证明图5所示的结构取得了最好的测试效果。该结构主要由池化层pool2×2s(2,2)和shunt结构组成,池化层和shunt结构均可实现特征图的维度降低。其中pool2×2s(2,2)表示大小为“2×2”、步长为2的池化层,kernel3×3s(1,1)表示大小为“3×3”步长为1的卷积层二,沿通道方向的两个kernal1×1s(1,1)分别表示大小为“3×3”步长为1的卷积层一和卷积层三。
二、实验与分析
1、训练和测试
通过实验对本发明搭建的fa-ssd网络结构进行训练和测试。实验所用训练数据集为voc07trainval与voc12trainval,检测数据集为voc07test。实验软件配置为window10、tensorflow1.7.0、tensorflowlayersapi、cuda9.0,硬件配置为nvidiageforcegtx1080ti(一块)、intel(r)xeon(r)cpue5-2609v4@17.0ghz。
fa-ssd中参与训练和检测的图像大小为300×300像素,因此下文也称fa-ssd300。回归特征图的大小分别是“19×19”、“10×10”、“5×5”、“3×3”和“1×1”,在上述六种回归特征图上采用锚箱分别生成建议框,具体建议框参数设置和分类定位阈值设定与ssd算法相应设置相同,参与对比分析的ssd300检测结果如表1和表2所示。
采用批次为16,共训练150000步。学习率初始设置为0.01,采用分阶段控制方式间接调整目标函数优化器。衰减步长边界设置为:“20000、900000、130000”,学习率衰减设置为:“1、0.1、0.005、0.001”。学习率终止边界设为0.00001,直至收敛。
为增加所用训练样本的价值,采用类似于ssd的数据增广方式,对样本进行如下顺序的预处理:曝光调节、大小裁剪,颜色调整、左右翻转。增广中的每种图像预处理都执行概率均为50%,并且不改变4种图像操作顺序。ssd网络为进一步增加样本的质量,随机改变上述4种图像预处理的操作顺序。因此,与ssd采用的数据预处理方式相比,本训练所采用的数据增广方式相对较弱。增广产生的数据实例如图6所示。
实验对fa-ssd的训练网络初试参数设定采用vgg参数迁移和参数初始化两种方法。其中,迁移vgg的参数是经过imagenet数据训练后获得的权重。训练过程中的损失变化曲线如图7(a)和图7(b)所示,其中7(a)的loss1与和7(b)的loss2分别是初始化参数和迁移vgg参数下的损失。由图7(a)和图7(b)可看出,迁移vgg参数的训练损失loss2收敛速度最快。但两种参数情况下的训练最终收敛在近似损失水平。
在迁移vgg参数的训练下,检测物体的平均准确度的变化对比图如图8所示(即不同迭代次数下的平均准确度的变化对比图)。由图8可见,除30000步的检测结果外,训练120000步之前平均准确度均逐渐提升。在120000步至终止训练阶段,平均准确度出现震荡,分别于120000步和140000步达到高峰,因此最终检测的平均准确度为80.5%。
2、基于异步卷积分解的shunt结构对实验结果的影响
fa-ssd网络中的高层网络共使用了4个shunt结构,即shunt0、shunt1、shunt2、shunt3,如图5所示。为验证不同的shunt连接方式对网络检测结果的影响,实验通过调整shunt结构个数,分别搭建了shunt0000、shunt1000、shunt0101、shunt1110、shunt1111进行相同的训练与检测。其中,末尾数字串的前后数字顺序表示shunt0至shunt3结构的位置顺序。“0”表示去除fa-ssd中对应位置的shunt结构,“1”表示保留所在位置的shunt结构,例如shunt0101表示图6中仅有shunt1与shunt3结构的fa-ssd网络结构。
不同数目的shunt结构对检测精度的影响对比图如图9所示,图9中每个shunt结构对应的检测结果中有两种对比度量,即检测速度(fps)和百分制的平均准确度(map)。由图9可见,仅加深高层主流网络深度后,shunt0000网络检测平均精度为77.8%,相对ssd提高0.6%,说明增加回归特征图之间的卷积层数可提高检测精度。此后,每增加一个shunt结构,网络在保证实时性的同时,进一步提高了平均检测精度。最后shunt1111(fa-ssd300)网络的检测平均精度达到最高的80.5%,相对ssd提高了3.3%。由平均准确度提高的幅度可推断,仅增加高层主流网络的卷积层数是提高平均准确率的次要因素,交错连接的shunt结构是检测精度提高的主要原因。在增加了shunt结构后,fa-ssd300检测精度达到了最高的80.5%,同时保证了检测的实时性。
3、高层网络优化对实验结果的影响
为优化异步卷积分解与shunt结构的融合,进一步提高特征的多样性,搭建了如图10(a)~图10(c)所示的三种高层局部网络结构(局部类似结构可叠构成高层网络)。图10(a)结构表示ssd原有的kernal3×3s(2,2)卷积层与shunt结构的结合,图10(b)与图(c)结构分别表示异步卷积分解结构、最大池化层和shunt结构的搭配。a、b和c分别对应的网络结构为fa-ssd0、fa-ssd1、fa-ssd2。fa-ssd1与fa-ssd2中的主流结构中的不同部分,分别为图10(b)中的kernal3×1s(2,1)、kernal1×3s(1,2)和图10(c)中的pool2×2s(2,2)。为保证fa-ssd1与fs-ssd2的主流结构深度相同(卷积层数与池化层数),结构c相比b增加一层kernal1×1s(2,2)的卷积层。在相同条件下对上述三种网络进行训练后,在voc2007test上的检测结果对比图如图11所示。图11中每种网络对应的检测结果中有两种对比度量,即检测速度(fps)和百分制的平均准确度(map)。fa-ssd0的平均检测精度为78.3%,相对ssd提升1.1%,检测速度虽然相对ssd降低11fps,但依然能保证实时检测。fassd1采用异步卷积分解结构对主流特图进行降维,平均精确度达到80%,相比ssd提高2.8%。主流结构采用最大池化进行降维时,目标检测的精度与速度都有进一步的提升。fa-ssd2相比fa-ssd1在平均准确度和检测速度上都提高0.5。fa-ssd1与fa-ssd2在结构上的主要区别是主流结构上的降维计算方式。fa-ssd1采用一种异步卷积分解结构同时进行特征提取与降维,而fa-ssd2采用异步卷积分解和池化两种不同的降维计算方式,提高特征的多样性。由于池化计算相对异步卷积分解结构更简单,fa-ssd2相对fa-ssd1提高了检测速度。异步卷积分解相对池化更有利于传递空间相关信息,同时两种降维方式提高了特征的多样性,因此fa-ssd2检测精度达到最高的80.5%。
4、对比实验
实验通过端到端的方法训练fa-ssd300,与现有算法在voc2007上进行了对比,结果如表1所示,fasterrcnn与r-fcn属于两阶段分类回归算法,虽然训练用到分辨率最大的图像,但平均精度仍然最低,且不具备实时检测能力。先后出现的单阶段回归系列算法yolov2、ssd300、dsod300以及dssd321的检测平均准确度逐步提升。其中,ssd类算法dsod300、dssd321虽然较前几种算法取得了更高的检测精度,但不能保证实时性,检测速度分别为17.4fps和9.5fps。fa-ssd300检测平均准确度最高,达到80.5%,同时采用一块相对titanx低端的1080ti显卡,仍然保持平均30fps的检测速度。
8种算法在voc07test上针对20个常见类别的具体检测结果对比如表2所示。其中,最高平均准确度和每个类最高准确度数字加有下划线。表2中左列五种算法为两阶段分类回归系列算法,右列三种算法为单价段回归算法,两类算法各自平均准确度最高的网络分别是r-fcn与fa-ssd300。虽然与fa-ssd300同样达到80.5%的平均准确度,但是r-fcn采用信息提取能力更强的复杂网络结构resnet-101,处理速度仅为7fps。除平均检测精度达到最高外,fa-ssd在20类检测中共有11类达到最高检测精度,其中“bus”与“cat”两个类的平均检测精度均超过90%,分别为90.2%和91.7%。
fa-ssd300在voc07test上的部分结果展示如图12(a)~图12(h)所示,对难以检测的密集小目标、遮挡目标和局部大目标均取得了较好的检测结果。图12(e)由于像素分辨率低造成一个小目标漏检,同时图12(b)和图12(g)由于目标遮挡过于严重造成次要目标漏检,其他所有位置定位框架均在合理范围内。
表1不同算法在voc07test上的检测结果
表2针对voc07test具体类别的检测对比
- 还没有人留言评论。精彩留言会获得点赞!