一种基于矩阵分块的残缺汉字识别方法与流程
本发明涉及一种基于矩阵分块的残缺汉字识别方法,属于汉语信息处理技术领域。
背景技术:
在文物考察、重要文档辨识中,可能存在一些汉字的一部分因某种原因而被抹去,正确识别出这些残缺的汉字对近代历史研究及考察名人语录等方面具有重要意义。
目前,对于残缺汉字的识别,主要是依靠人对汉字的熟悉程度以及人工对比汉语词典,再根据上下文信息进行推理得到,但是由于汉字的广泛性,使得这一工作即耗时又繁琐。若以编码方式为unicode的基本字符集为标准,则共有20902个汉字,即使可以根据残缺汉字的大概字形及上下文信息推理进行筛选,但筛选结果也存在许多的备选项,更重要的是人工识别中对于这一工作难免会产生疏忽与厌倦,这就造成了识别残缺汉字的难度又一步加大。
技术实现要素:
本发明要解决的技术问题是针对现有技术的局限和不足,提供一种基于矩阵分块的残缺汉字识别方法,以解决现有技术对残缺汉字的识别耗费人力且准确性欠佳等现象,致力于增加目前依靠计算机对残缺汉字进行识别的有效性和准确性。
本发明的技术方案是:一种基于矩阵分块的残缺汉字识别方法,该方法具体包括以下步骤:
step0:采集汉字图像,对图像进行预处理,并创建汉字特征数据库;具体实施步骤如step0.1~step0.4所示;
step0.1:从ttc字体文件中提取出每个汉字所对应的图像,即汉字图像大小为l×w,单位为像素点,并强制令l、w为偶数;将汉字图像作为输入源,生成该汉字所对应的汉字矩阵i,该矩阵中的元素值即为该像素点的灰度值;定义ξ为灰度二值化阈值,对矩阵i进行公式(1)所示二值化处理,得到二值化矩阵i′,其中i′(i,j),i∈[1,l],j∈[1,w]为元素值;
step0.2:将二值化矩阵i′进行公式(2)所示分块处理,得到分块矩阵i1′、i2′、i3′、i4′;
step0.3:将分块矩阵i1′、i2′、i3′、i4′进行公式(3)所示纵向叠加处理,生成纵向特征向量{z1,z2,…,z2l};
step0.4:将分块矩阵i1′、i2′、i3′、i4′进行公式(4)所示横向叠加处理,生成横向特征向量{h1,h2,…,h2w};
step0.5:将纵向特征向量{z1,z2,…,z2l}、横向特征向量{h1,h2,…,h2w}进行连接合并,组成新的特征向量{f1,f2,…,f2l+2w};
step0.6:将汉字及其对应的特征向量{f1,f2,…,f2l+2w}存入数据库,组建汉字特征数据库;
step1:利用现代扫描技术及汉字形状特征,从纸张或其他载体中提取出待检测残缺汉字x的图像,将图像以l:w的比例剪切至待检测残缺汉字x尽可能铺满图像为止,但要将其残缺汉字重心处于图像的中心,并留取合适的边距,生成待检测残缺汉字x的扫描图像
step2:将待检测残缺汉字x的扫描图像
step3:将二值化矩阵x′进行公式(6)所示分块处理,得到分块矩阵x1′、x2′、x3′、x4′;
step4:将分块矩阵x1′、x2′、x3′、x4′进行公式(7)所示纵向叠加处理,生成纵向特征向量{xz1,xz2,…,xz2l};
step5:将分块矩阵x1′、x2′、x3′、x4′进行公式(8)所示横向叠加处理,生成横向特征向量{xh1,xh2,…,xh2w};
step6:将纵向特征向量{xz1,xz2,…,xz2l}、横向特征向量{xh1,xh2,…,xh2w}进行连接合并,组成新的特征向量{x1,x2,…,x2l+2w};
step7:调取汉字特征数据库中的汉字f,以及对应的特征向量{f1,f2,…,f2l+2w},通过余弦定理算法公式(9)计算残缺汉字x与汉字f之间的识别度sbd(x,f);
step8:遍历汉字特征数据库中的所有数据,对数据库中每个汉字fi,i∈[1,k]都经step7步骤计算其与残缺汉字x之间的识别度sbd(x,fi),i∈[1,k];将按照从大到小的顺序排序,提取出前θ个待定汉字并输出。
进一步地,所述步骤step0.1中,ttc字体文件包括但不限于宋体、黑体、微软雅黑等十多种常用字体;汉字图像大小l×w是由字体文件中提取的汉字字体大小决定,可自由设置,并强制令l、w为偶数;并且灰度二值化阈值ξ满足0≤ξ≤255的要求,通常取ξ=1。
进一步地,所述步骤step1中,提取残缺汉字的图像信息时尽可能使残缺汉字平铺,有助于提取残缺汉字的汉字特征。
进一步地,所述步骤step8中,k即为汉字的总个数,若按照编码方式为unicode的基本字符集为标准,则共有20902个汉字,即k=20902。
进一步地,所述步骤step8中,θ可由使用者自己定义,通常令θ=3,θ越大则识别准确度越高,但使用者所需花费的查找时间也随之增加。
本发明的有益效果是:本发明与现有技术相比,主要解决了现有技术耗费人力且准确性欠佳等现象,增加了目前依靠计算机对残缺汉字进行识别的有效性和准确性。
附图说明
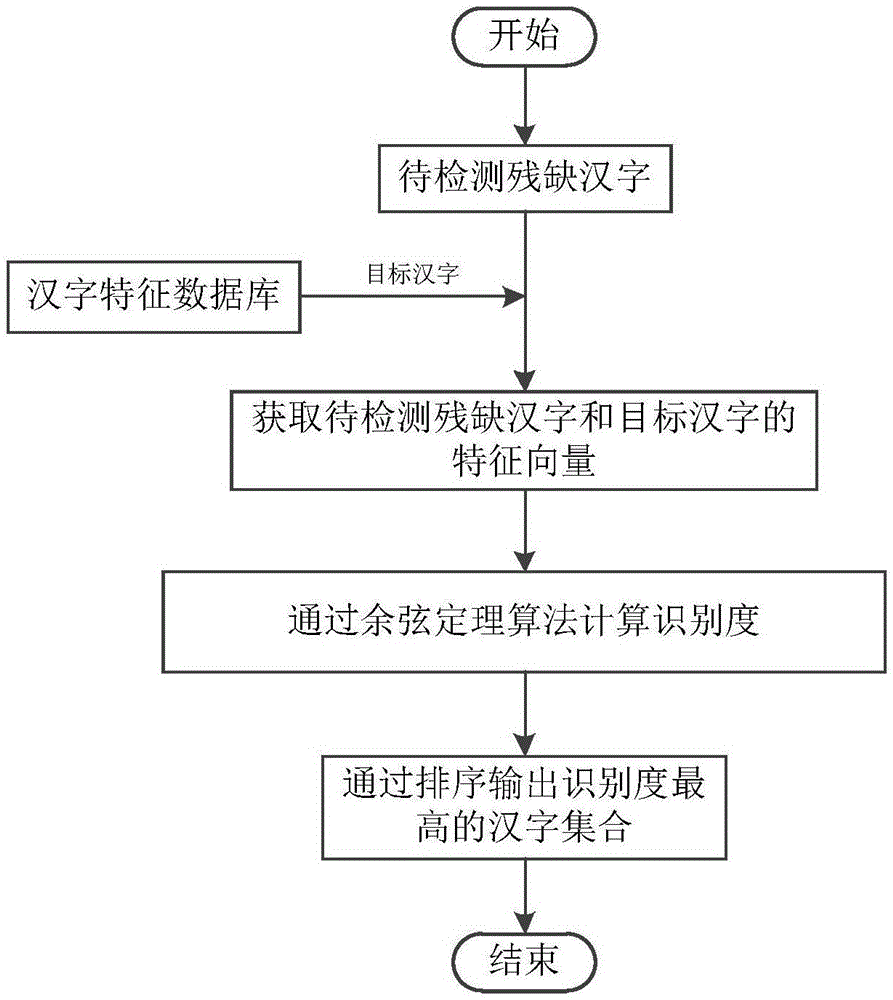
图1是本发明步骤流程图;
图2是本发明建立数据库流程示意图;
图3是本发明获取待检测残缺文字的特征向量流程示意图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
实施例1:如图1-3所示,一种基于矩阵分块的残缺汉字识别方法,通过ttc字体文件提取汉字图像,对图像矩阵进行灰度二值化处理后将其分为四块,按要求依次生成其纵向特征向量及横向特征向量,并进行连接合并处理后得到特征向量,建立汉字特征数据库,对任意待检测残缺汉字通过现代扫描技术及汉字形状特征转化为图像,对其进行特定的灰度化、二值化处理后提取汉字特征并生成纵向特征向量及横向特征向量,进行连接合并处理后得到特征向量,与数据库中现有汉字计算其识别度,最后通过排序输出识别度最高的汉字集合。
具体步骤为:
step0:采集汉字图像,对图像进行预处理,并创建汉字特征数据库;具体实施步骤如step0.1~step0.4所示;
step0.1:从ttc字体文件中提取出每个汉字所对应的图像,即汉字图像大小为l×w(单位为像素点),并强制令l、w为偶数;将汉字图像作为输入源,生成该汉字所对应的汉字矩阵i,该矩阵中的元素值即为该像素点的灰度值;定义ξ为灰度二值化阈值,对矩阵i进行公式(1)所示二值化处理,得到二值化矩阵i′,其中i′(i,j),i∈[1,l],j∈[1,w]为元素值;
step0.2:将二值化矩阵i′进行公式(2)所示分块处理,得到分块矩阵i1′、i2′、i3′、i4′;
step0.3:将分块矩阵i1′、i2′、i3′、i4′进行公式(3)所示纵向叠加处理,生成纵向特征向量{z1,z2,…,z2l};
step0.4:将分块矩阵i1′、i2′、i3′、i4′进行公式(4)所示横向叠加处理,生成横向特征向量{h1,h2,…,h2w};
step0.5:将纵向特征向量{z1,z2,…,z2l}、横向特征向量{h1,h2,…,h2w}进行连接合并,组成新的特征向量{f1,f2,…,f2l+2w};
step0.6:将汉字及其对应的特征向量{f1,f2,…,f2l+2w}存入数据库,组建汉字特征数据库;
step1:利用现代扫描技术及汉字形状特征,从纸张或其他载体中提取出待检测残缺汉字x的图像,将图像以l:w的比例剪切至待检测残缺汉字x尽可能铺满图像为止,但要将其残缺汉字重心处于图像的中心,并留取合适的边距,生成待检测残缺汉字x的扫描图像
step2:将待检测残缺汉字x的扫描图像
step3:将二值化矩阵x′进行公式(6)所示分块处理,得到分块矩阵x1′、x2′、x3′、x4′;
step4:将分块矩阵x1′、x2′、x3′、x4′进行公式(7)所示纵向叠加处理,生成纵向特征向量{xz1,xz2,…,xz2l};
step5:将分块矩阵x1′、x2′、x3′、x4′进行公式(8)所示横向叠加处理,生成横向特征向量{xh1,xh2,…,xh2w};
step6:将纵向特征向量{xz1,xz2,…,xz2l}、横向特征向量{xh1,xh2,…,xh2w}进行连接合并,组成新的特征向量{x1,x2,…,x2l+2w};
step7:调取汉字特征数据库中的汉字f,以及对应的特征向量{f1,f2,…,f2l+2w},通过余弦定理算法公式(9)计算残缺汉字x与汉字f之间的识别度sbd(x,f);
step8:遍历汉字特征数据库中的所有数据,对数据库中每个汉字fi,i∈[1,k]都经step7步骤计算其与残缺汉字x之间的识别度sbd(x,fi),i∈[1,k];将按照从大到小的顺序排序,提取出前θ个待定汉字并输出。
进一步地,所述步骤step0.1中,ttc字体文件包括但不限于宋体、黑体、微软雅黑等十多种常用字体;汉字图像大小l×w是由字体文件中提取的汉字字体大小决定,可自由设置,并强制令l、w为偶数;并且灰度二值化阈值ξ满足0≤ξ≤255的要求,通常取ξ=1。
进一步地,所述步骤step1中,提取残缺汉字的图像信息时尽可能使残缺汉字平铺,有助于提取残缺汉字的汉字特征。
进一步地,所述步骤step8中,k即为汉字的总个数,若按照编码方式为unicode的基本字符集为标准,则共有20902个汉字,即k=20902。
进一步地,所述步骤step8中,θ可由使用者自己定义,通常令θ=3,θ越大则识别准确度越高,但使用者所需花费的查找时间也随之增加。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!