一种基于大数据和机器学习的电信诈骗上当人发现方法与流程
本发明涉及通讯信息安全技术领域,尤其涉及一种基于大数据和机器学习的电信诈骗上当人发现方法。
背景技术:
机器学习包括无监督学习和监督学习,其中随机森林是一种重要的基于bagging(是一种用来提高学习算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将它们组合成一个预测函数)的集成学习方法,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定,可以用来做分类、回归及聚类等问题,优点是:具有极高的准确率;由于随机性的引入,使得随机森林不容易过拟合,且具有很好的抗噪声能力;能够用来处理很高维的数据,并且不用做特征选择;随机森林算法既能够用来处理离散型数据,也能用来处理连续性数据,无须规范化;训练速度很快,可以得到变量重要性排序,容易实现并行化。但是随机森林算法也有缺点:当其中的决策树个数很多的时候,训练需要的时间空间较大;且可解释性较弱。随机森林的构建过程如下:
从原始训练集中使用bootstraping方法(指的就是利用有限的样本资料经由多次重复抽样,重新建立起足以代表母体样本分布的新样本),随机有放回采样选出m个样本,共进行n_tree次采样,生成n_tree个训练集;对于n_tree个训练集,我们分别训练n_tree个决策树模型;对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据信息增益/信息增益比/基尼指数选择最好的特征进行分裂;每棵树都一直这样分裂下去,直到该节点的所有训练样例都属于同一类。在决策树的分裂过程中不需要剪枝;将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果。
目前已有一种基于大数据和机器学习的防范电信诈骗系统及方法,该方法是在接收到短信消息或者来电消息的时候通过预定的约束规则针对当前的电信数据进行诈骗检测判定,采用机器学习算法检测是否为电信诈骗,如果检测结果判定为电信诈骗,则将该诈骗数据信息上传到大数据分析端;也有一种诈骗电话号码的分析方法,其采用随机森林算法建立不同类型的诈骗电话检测模型,周期性地对诈骗电话号码分类模型进行离线的训练,然后在现网中进行准实时的检测判定,从大量话单信息中甄别出诈骗电话事件和号码;也有一种基于深度学习的电信诈骗识别与防御系统,将深度学习技术与国密算法相结合,采取来电监听与语音识别等技术,来识别诈骗电话。
上述已有方法在电信诈骗识别与防范方面各有侧重,但以上方法均是针对诈骗方进行的识别和预防,对于潜在的被诈骗人方面没有预防措施,不能提前做到防止潜在被诈骗人上当受骗。
因此,急需一种基于大数据和机器学习的电信诈骗上当人发现方法。
技术实现要素:
本发明提供了一种基于大数据和机器学习的电信诈骗上当人发现方法,以便于使用随机森林算法与关联规则算法,在大数据平台上根据原始话单数据分析发现上当人,找出规律,挖掘潜在上当人。
本发明提供了一种基于大数据和机器学习的电信诈骗上当人发现方法,包括以下步骤:
获取原始电话记录单,筛选出其中的诈骗电话事件;
分析诈骗电话事件中被叫的特征和场景以得到多维度特征表,并作为预处理数据进行存储;
对预处理数据进行清理,得到待转换数据;
将待转换数据转换成训练样本;
利用训练样本生成分类器模型;
将被叫为分析对象的电话记录单数据代入分类器模型,进行预警。
进一步地,采用填写空缺值或者光滑噪声数据或者识别删除离群点或者删除重复值或者数据降维中的至少一种方法对预处理数据进行清理。
进一步地,采用建立数据仓库,并通过平滑聚集或者数据概化或者数据规范化中的至少一种方法将待转换数据转换成训练样本。
进一步地,利用训练样本生成分类器模型的步骤具体包括以下步骤:
预设数值m,m被用来决定当在一个节点上做决定时,会使用到多少个变量;
从n个训练样本中以可重复取样的方式,取样n次,形成一组训练集;
对于每一个节点,随机选择m个基于此点上的变量,根据这m个变量,计算其最佳的分割方式,以得到分类器模型;
其中,m为小于变量数目的预设数值,n为训练样本的个数。
进一步地,利用训练样本生成分类器模型的方式为:在训练样本上执行分类器算法,生成分类器模型。
进一步地,分类器算法为决策树算法。
进一步地,分析诈骗电话事件中被叫的特征和场景的方式为记录被叫在预设时间段内的行为特征和行为场景以得到多维度特征表。
进一步地,对预处理数据进行清理之前还包括步骤:对多维度特征表采用随机森林算法进行无监督学习聚类和异常点检测,得到预处理数据。
进一步地,将被叫为分析对象的电话记录单数据代入分类器模型,进行预警的步骤具体包括以下步骤:
将被叫为分析对象的电话记录单数据代入分类器模型,得到潜在上当人信息;
通过人工监听验证分类器模型,并进行预警。
进一步地,进行预警之前还包括步骤:
通过人工监听验证分类器模型,得到完善后的分类器模型;
将潜在上当人的电话记录单数据代入完善后的分类器模型,并进行预警。
本发明提供的基于大数据和机器学习的电信诈骗上当人发现方法,与现有技术相比具有以下进步:通过对原始话单数据的分析发现上当人,并根据上当人被叫时的特征和场景建立模型,通过将被叫为分析对象的电话记录单数据代入模型中进行预警,能够有效的防止被叫的潜在上当人被电信诈骗的问题,具有方法简单、防诈骗效率高的优点。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1为本发明实施例中一种基于大数据和机器学习的电信诈骗上当人发现方法的步骤图;
图2为本发明实施例中步骤s6具体实施时的步骤图;
图3为本发明实施例中步骤s7具体实施时的步骤图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本技术领域技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语),具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语,应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非被特定定义,否则不会用理想化或过于正式的含义来解释。
本实施例提供了一种基于大数据和机器学习的电信诈骗上当人发现方法。
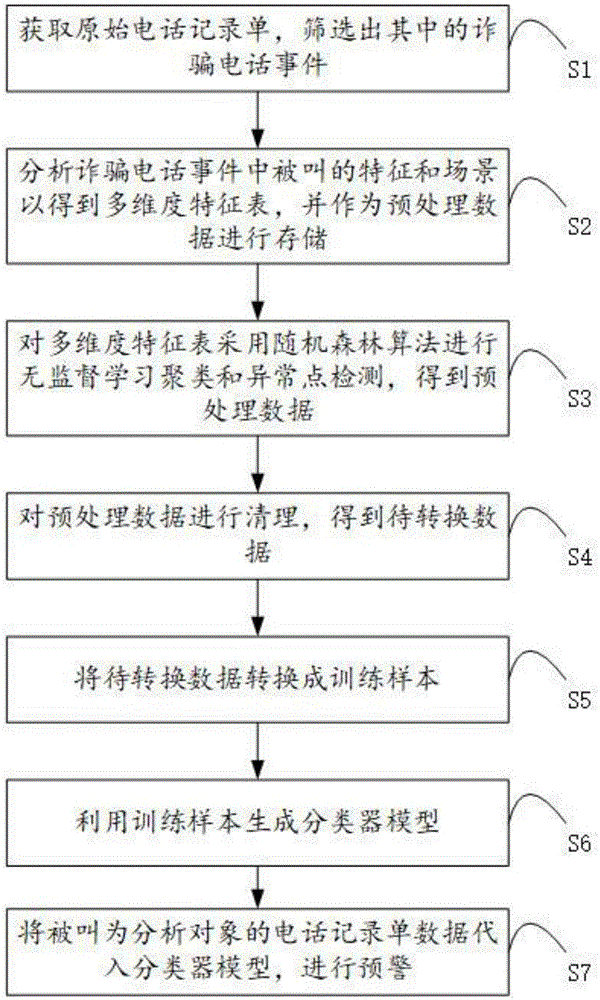
如图1,本实施例的基于大数据和机器学习的电信诈骗上当人发现方法,包括以下步骤:
s1、获取原始电话记录单,筛选出其中的诈骗电话事件;
s2、分析诈骗电话事件中被叫的特征和场景以得到多维度特征表,并作为预处理数据进行存储;
s4、对预处理数据进行清理,得到待转换数据;
s5、将待转换数据转换成训练样本;
s6、利用训练样本生成分类器模型;
s7、将被叫为分析对象的电话记录单数据代入分类器模型,进行预警。
本实施例的基于大数据和机器学习的电信诈骗上当人发现方法,通过对原始话单数据的分析发现上当人,并根据上当人被叫时的特征和场景建立模型,通过将被叫为分析对象的电话记录单数据代入模型中进行预警,能够有效的防止被叫的潜在上当人被电信诈骗的问题,具有方法简单、防诈骗效率高的优点。
具体实施时,采用填写空缺值或者光滑噪声数据或者识别删除离群点或者删除重复值或者数据降维中的至少一种方法对预处理数据进行清理。使最后得到的分类器模型更加准确。
具体实施时,采用建立数据仓库,并通过平滑聚集或者数据概化或者数据规范化中的至少一种方法将待转换数据转换成训练样本。转换后的训练样本是更适于数据挖掘的形式,有利于提高效率和准确性。
如图2,本实施例的基于大数据和机器学习的电信诈骗上当人发现方法,步骤s6实施时具体包括以下步骤:
s61、预设数值m,m被用来决定当在一个节点上做决定时,会使用到多少个变量;
s62、从n个训练样本中以可重复取样的方式,取样n次,形成一组训练集;
s63、对于每一个节点,随机选择m个基于此点上的变量,根据这m个变量,计算其最佳的分割方式,以得到分类器模型;
其中,m为小于变量数目的预设数值,n为训练样本的个数。
以上步骤中,每个训练样本作为一个节点,目的是建造每棵树,从而形成随机森林,为后续的随机森林模型的建立提供基础数据。
具体实施时,利用训练样本生成分类器模型的方式为:在训练样本上执行分类器算法,生成分类器模型。其中,分类器算法为决策树算法。决策树算法的优点是:分类精度高、生成的模式简单、对噪声数据有很好的健壮性。也可以是逻辑回归、朴素贝叶斯、神经网络等算法,根据需要,由用户自行选择。
具体实施时,分析诈骗电话事件中被叫的特征和场景的方式为记录被叫在预设时间段内的行为特征和行为场景以得到多维度特征表。在一定时间段内的行为特征和行为场景有利于提高工作效率和防诈骗的准确性。
如图1,对预处理数据进行清理之前还包括步骤:s3、对多维度特征表采用随机森林算法进行无监督学习聚类和异常点检测,得到预处理数据。
如图3,步骤s7具体实施时包括以下步骤:
s71、将被叫为分析对象的电话记录单数据代入分类器模型,得到潜在上当人信息;
s73、通过人工监听验证分类器模型,得到完善后的分类器模型;
s74、将潜在上当人的电话记录单数据代入完善后的分类器模型,并进行预警。
本实施例的基于大数据和机器学习的电信诈骗上当人发现方法,在具体使用时,可以根据大量电信日志分析,分析诈骗电话事件中被叫的行为特征和场景,在大数据分布式平台上对原始话单进行筛选和统计,以被叫为主分析对象,记录其特定时段或一定时间范围内的行为特征和行为场景,建立多维度特征集,使用sparkmlib(spark是一种计算引擎,mllib是spark的机器学习库,其目标是使实际的机器学习可扩展和容易),对已建立的针对被叫号码的多维特征表采用随机森林算法进行无监督学习聚类和异常点检测,通过部分监听分析该号码是否为电信诈骗上当人,进而检验分类器模型,将完善好的分类器模型,本实施例中,分类器模型为随机森林模型,用于新记录的分类预测,进而及时预警。
对于方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明实施例并不受所描述的动作顺序的限制,因为依据本发明实施例,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作并不一定是本发明实施例所必须的。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!