一种含水天然气管线内腐蚀速度预测方法及装置与流程
本发明涉及天然气管道腐蚀速度预测技术领域,具体涉及一种含水天然气管线内腐蚀速度预测方法及装置。
背景技术:
天然气管道在传输气体的过程中,某些物质必定会腐蚀天然气管道内壁,影响天然气管道的正常使用寿命。如果不采取防御措施,势必会由于内腐蚀而发生泄漏甚至爆炸等恶性事件,造成巨大的财产和人员的损失,但是盲目更换有腐蚀缺陷的管道又会造成巨大的经济浪费,怎样对安全性和经济性做到合理兼顾,就具有十分重要的意义。
目前国外多会严格把关天然气气质和对输送的中间环节进行把关,还采用内壁涂层的方法等,国内用于天气管线内腐蚀的方法为定期加注缓蚀剂及定期清管、安装线路分水器等。但是尽管在采取了很多措施和大量投资的情况,国外在管线事故统计分析中,由于内腐蚀而引发的事故依然高达10%,国内由于腐蚀而导致的事故则更多。之所以还有如此多的由于内腐蚀所引起的事故,重要的原因之一是没有对管道内腐蚀速度做好预测工作,没有把握好修理或者更换管道的时间。
目前在预测天然气管道腐蚀速度的相关研究中,天然气管道的腐蚀速度预测多采用逐步回归、人工神经网络等方法,预测得到的腐蚀速度不够准确。其中很大原因就是因为选择预测的模型不够准确,在选择模型的时候,如决策树模型容易陷入过拟合、需要剪枝操作,支持向量机算法对缺失数据敏感,核函数对参数影响较大。
因此,如何更精准的预测天然气管道内的腐蚀速度,预测出天然气管道的使用寿命,以便及时更换天然气管道具有重要意义。
技术实现要素:
本发明的目的在于提供一种含水天然气管线内腐蚀速度预测方法及装置,以解决上述背景技术中提出的问题。
为了实现上述目的,本发明提供以下技术方案:
一种含水天然气管线内腐蚀速度预测方法,其特征在于,包括以下步骤:
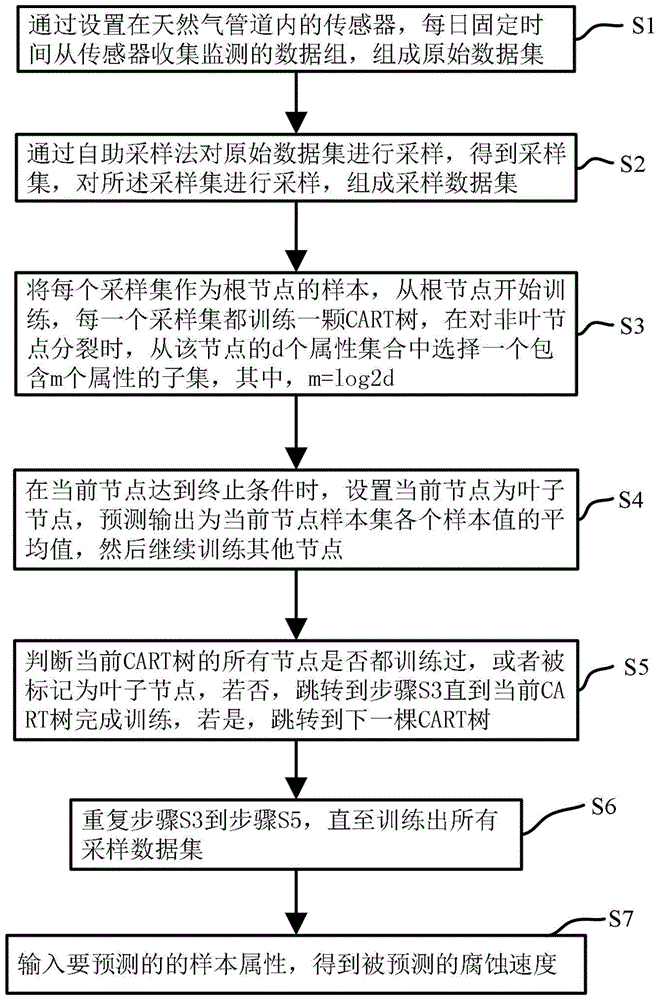
步骤s1、通过设置在天然气管道内的传感器,每日固定时间从传感器收集监测的数据组,组成原始数据集;
步骤s2、通过自助采样法对原始数据集进行采样,得到采样集,对所述采样集进行采样,组成采样数据集;
步骤s3、将每个采样集作为根节点的样本,从根节点开始训练,每一个采样集都训练一颗cart树,在对非叶节点分裂时,从该结点的d个属性集合中选择一个包含m个属性的子集,其中,
步骤s4、在当前节点达到终止条件时,设置当前节点为叶子节点,预测输出为当前节点样本集各个样本值的平均值,然后继续训练剩余节点;
步骤s5、判断当前cart树的所有节点是否都训练过或者被标记为叶子节点,若否,跳转到步骤s3直到当前cart树完成训练,若是,跳转到下一棵cart树;
步骤s6、重复步骤s3到步骤s5,直至训练出所有采样数据集;
步骤s7、输入要预测的样本属性,得到被预测的腐蚀速度。
进一步,在步骤s1中,所述监测的数据包括:天然气管道内的甲烷含量、乙烷含量、丙烷含量、丁烷含量、硫化氢含量、二氧化碳含量、一氧化碳含量、氢气含量、缓蚀剂浓度、水蒸气含量、温度。
进一步,在步骤s2中,通过采样小类样本合成重采样的方式修改采样集。
一种含水天然气管线内腐蚀速度预测装置,所述装置包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当所述计算机程序指令被所述处理器执行时,触发所述装置执行上述任一项所述的方法。
本发明的有益效果是:本发明引用了随机森林算法解决天然气管道腐蚀预测问题,由于两个随机性的引入,使得随机森林不容易陷入过拟合,并且对异常值、噪声值不敏感,具有很好得抗噪能力,采用组合多个分类器进行投票分类,可以减少单个分类器的误差,改进的随机森林算法克服了面对不平衡数据精确度不高等情况,具有更高的稳定性和鲁棒性,分类准确较高,能极大地保证预测的精度。
附图说明
下面结合附图和实例对本发明作进一步说明。
图1是本发明实施例一种含水天然气管线内腐蚀速度预测方法的流程示意图。
具体实施方式
参考图1,下面结合附图与具体实施方式对本发明作进一步详细的描述。
下面将结合附图对本发明的技术方案进行清楚、完整的描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所以其他实施例,都属于本发明的保护范围。
如图1所示,本发明提供一种含水天然气管线内腐蚀速度预测方法,包括:
步骤s1、通过设置在天然气管道内的传感器,每日固定时间从传感器收集监测的数据组,组成原始数据集;
所述监测的数据包括:天然气管道内的甲烷含量、乙烷含量、丙烷含量、丁烷含量、硫化氢含量、二氧化碳含量、一氧化碳含量、氢气含量、缓蚀剂浓度、水蒸气含量、温度;
本实施例在收集了1500条监测的数据组,组成原始数据集;
步骤s2、通过自助采样法对原始数据集进行采样,得到采样集,采样出t个采样集组成采样数据集;
本实施例采用有放回地抽取方式对包含1500条数据组经过1000次随机采样操作后,得到包含1000条数据组的采样集,并从中采样出500个采样数据集。
本实施例中,原始数据集中有的数据在采样集里多次出现,有的则从未出现;
作为本实施例的进一步改进,为减低不平衡数据的影响,通过采样小类样本合成重采样技术,修改训练集,通过采样算法的改进,提升了分类效果。
步骤s3、将每个采样集作为根节点的样本,从根节点开始训练,每一个采样集都训练一颗cart树,在对非叶节点分裂时,从该结点的d个属性集合中选择一个包含m个属性的子集,其中,
本实施例中,从所有的11个属性中随机地选取4个属性,随机选择二氧化碳含量、硫化氢含量、缓蚀剂浓度、水蒸气浓度4个属性,再从这4个属性中选取最佳分裂属性p以及相应的最佳分裂阈值th,当前节点上样本第k维属性小于th的样本被划分到左节点,其余的被划分到右节点。
步骤s4、在当前节点达到终止条件时,设置当前节点为叶子节点,预测输出为当前节点样本集各个样本值的平均值,然后继续训练剩余节点;
本实施例中,通过上述操作,在该采样集上最终生成的决策树不需要剪枝步骤。
步骤s5、判断当前cart树的所有节点是否都训练过或者被标记为叶子节点,若否,跳转到步骤s3直到当前cart树完成训练,若是,跳转到下一棵cart树;
步骤s6、重复步骤s3到步骤s5,直至训练出所有采样数据集;
步骤s7、输入要预测的样本属性,得到被预测的腐蚀速度;
作为本实施例的一个可选项,从训练集中用自助采样法获得的训练集与原始数据相比,只有一部分的数据被重复抽取,本实施例数据为63%,而有另一部分的数据从未出现,这部分数据称为oob,用oob可以来检验每棵树分类效果的好坏,最终得到袋外误差,进而衡量分类器泛化能力。
本实施例提供的一种含水天然气管线内腐蚀速度预测装置,所述装置包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当所述计算机程序指令被所述处理器执行时,触发所述装置执行上述任一项所述的方法。
以上所述,只是本发明的较佳实施例而已,本发明并不局限于上述实施方式,只要其以相同的手段达到本发明的技术效果,都应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!