一种基于多视角图像特征分解的行人再识别方法与流程
本发明涉及智能图像检索技术领域,更具体而言,涉及一种基于多视角图像特征分解的行人再识别方法。
背景技术:
随着社会公共安全越来越受到重视,大量的监控摄像头被安装到许多重要场所,监控摄像头拍摄的监控视频可为公安部门提供侦破诸如恐怖袭击、聚众斗殴等重大刑事案件的线索。行人再识别是一种自动的目标识别技术,在监控网络中快速定位到感兴趣的人体目标,是智能视频监控和人体行为分析等应用中的重要步骤。使用行人再识别技术主要目的就是要解决安全监控领域中行人的检索问题。
行人重识别通常是从特征提取和距离度量学习两个方面进行研究。基于特征提取的行人重识别研究,特征提取是进行图像识别的核心问题。提取到合适的、稳健的特征,对于检测结果和执行效率都有很大的提高。常使用的特征主要有:hog特征,sift特征,surf特征,covariance描述子,elf特征,haar-likerepresention特征,lbp特征,gabor滤波器,co-occurrencematrics共生阵等。
基于距离度量学习的行人重识别研究。由于摄像机的视角、尺度、光照、服饰与姿态变化、分辨率不同以及存在遮挡,不同摄像头之间可能会失去连续的位置和运动信息,使用欧氏距离、巴氏距离等标准的距离度量来度量行人表观特征的相似度不能获得很好的重识别效果,因此,研究者们提出通过度量学习的方法,来衡量不同图像下的行人的相似度。常见的距离度量学习算法如:lmnn算法,prdc算法,ldml算法kissme算法,lfda算法,xqda算法。
2014年,将行人重识别的研究与深度学习结合在一起,目前基于图像的行人再识别主要使用基于深度卷积神经网络方法。mclaughlin等采用基于alexnet卷积神经网络(cnn)结构的方法,进行迁移学习,对图像提取颜色和光流特征,采用卷积神经网络处理得到高层表征,然后用循环神经网络(rnn)捕捉时间信息,然后池化得到序列特征。t.xiao等对来自各个领域的数据训练出同一个卷积神经网络(cnn),有些神经元学习各个领域共享的表征,其它的神经元对特定的某个区域有效,得到鲁棒的cnn特征表示。
在基于图像的行人重识别研究中,viper作为最广泛的采用的数据集,rank-1的准确率从2008年的12.0%提高了2015年的63.9%;同时,数据集cuhk01上的rank-1提高到2017年的79.9%;在market-1501上,深度学习的应用明显提高了rank-1的准确率,从2015年该数据集刚开始应用到行人重识别的研究中时,rank-1的准确率从44.42%提高到了2017年的82.21%。从上面描述的研究成果可以看出,基于图像的行人重识别的研究取得了重大进步,但是有进一步提升的空间,主要存在准确率不高的问题。注:rank-1表示判定结果中概率最高的解即是正确解。
技术实现要素:
本发明的目的在于提供一种基于多视角图像特征分解的行人再识别方法,通过改进的胶囊神经网络实现对任意行人图像的多视角图像特征分解(正面、侧面、背面),生成任意行人图像在多视角下的图像特征描述信息和相应的概率信息,生成的行人特征描述信息和特征的概率信息用于行人图像相似度度量,该方法可用于大规模视频或者图像集中检索特定行人目标。
为达到上述目的,本发明提供的技术方案为:
一种基于多视角图像特征分解的行人再识别方法,包括以下步骤:
s1、在行人图像数据集中,选取标准图像,将选好的标准图像分成训练数据集和测试数据集,建立多视角图像特征分解神经网络的训练数据集和测试数据集;
s2、将数据集中行人图像经过缩放或裁剪成分辨率为192×64的rgb图像,作为训练集和测试集;
s3、将胶囊分类网络capsulenet设计为两层卷积层,两层胶囊层,得到改进后的胶囊网络;
s4、对s3中改进的胶囊分类网络在s2中标准视角行人图像训练集上进行训练,构造多视角图像特征分解神经网络,生成任意行人图像在三种标准视角下的相似度和图像特征向量;
s5、生成跨视角特征转换矩阵,用于不同视角下的行人图像特征转换,计算跨视角特征转换系数矩阵,用于减少跨视角行人图像特征度量损失;
s6、选择行人图像相似度度量函数,实现行人再识别,实现同视角特征比较和跨视角特征比较,用于行人再识别中的行人图像相似度度量。
进一步地,所述s1中标准图像为拍摄角度为标准的正面图像、侧面图像和背面图像。
进一步地,所述s3中改进后的胶囊网络为三分类网络。
进一步地,所述s3中改进后的胶囊网络capsulenet的第一层设置为卷积层,参数:卷积核5×5、输出通道数32、输入维度为b×3×192×64,b为超参数批处理数量;第二层设置为卷积层,参数:卷积核5×5、输出通道数256;第三层为初级胶囊层,参数:卷积核5×5,输出通道数8;第四层为编码胶囊层,参数:输出通道数3,路由参数2,输出维度为b×3×64,b为超参数批处理数量。
进一步地,所述卷积层可以被单层神经网络、resnet、hourglassnet等其他卷积网络替代。
进一步地,所述s4中相似度计算公式为:
式中,e为自然常数(e≈2.71828),v表示特征向量模的长度,i表示第i个行人图像,vij表示第i个行人某种(j)视角下的特征向量模的长度,sij表示第i个行人在视角j下的相似度。
进一步地,所述s5中生成跨视角特征转换矩阵具体包括以下步骤:
(1)建立数据集,数据集中包含同一行人不同视角的特征对{vi,ui},特征vi和ui具有相同的维度d,其中vi,ui表示某视角下的行人特征编码;
(2)建立并训练特征转换网络,特征转换网络是两层的bp神经网络,网络输入层数据为vi,输入层维度1×d,网络输出层数据为ui’,输出层维度1×d,损失函数为:loss(x)=1-cos(ui’,ui),其中ui’表示网络转换特征,ui表示目标特征;
(3)特征转换网络经过训练后,损失函数降低到0.07以下,从特征转换网络提取转换矩阵w,ui’=w*vi,w是d×d的矩阵;
(4)重复步骤(2)和步骤(3),将所有的不视角的图像特征转换矩阵都计算一次,得到所有跨视角特征转换矩阵。
进一步地,所述s5中计算跨视角特征转换系数为
不同视角的转换系数组成转换系数矩阵矩阵为:
其中a12表示行人正面特征到侧面特征的转换系数,a13表示行人正面特征到背面特征的转换系数,a21表示行人侧面特征到正面特征转换系数,a23表示行人侧面特征到背面特征的转换系数,a31表示行人背面特征到正面特征转换系数,a32表示行人背面特征到侧面特征的转换系数。
进一步地,所述s6中实现行人再识别具体包括以下步骤:
(1)选择cos函数进行行人特征距离度量,行人特征距离度量如下:f(x,y)=alpha×cos(x,y),其中alpha为转换系数;
(2)同视角行人特征比较,行人特征距离为:l=f(xi,yj),其中xj、yj为任意行人图像概率最大的多视角图像特征分解特征;
(3)跨视角行人特征比较,行人特征距离为:l=f(w×xi,yj),其中xj、yj为任意行人图像概率最大的多视角图像特征分解特征,w为转换矩阵;
(4)对被检索行人图像距离度量结果进行降序排序,排序结果中前面的行人图片即为行人图像再识别结果。
与现有技术相比,本发明所具有的有益效果为:
本发明提供了一种基于多视角图像特征分解的行人再识别方法,从目标图像分类问题出发,结合胶囊网络,构建了行人图像多视角图像特征生成网络,将任意行人图像进行分解得到多视角图像特征以及该视角下的相似度。同视角特征直接用于再识别,不同视角特征则必须经过特征转换,本发明中使用bp神经网络获的了特征转换矩阵,解决了不同视视角特征的度量问题。实验表明通过行人图像的分解对提高行人再识别准确率有极大的帮助。
附图说明
图1为行人图像多视角图像特征示意图;
图2为行人图像数据集示意图;
图3为标准胶囊网络;
图4为行人图像多视角图像特征生成网络结构图;
图5为同视角特征比较方法;
图6为不同视角特征比较方法;
图7为行人特征转换示意图;
图8为实施例数据测试结果;
图9为行人再识别检测结果。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于多视角图像特征分解的行人再识别方法,按照以下步骤进行:
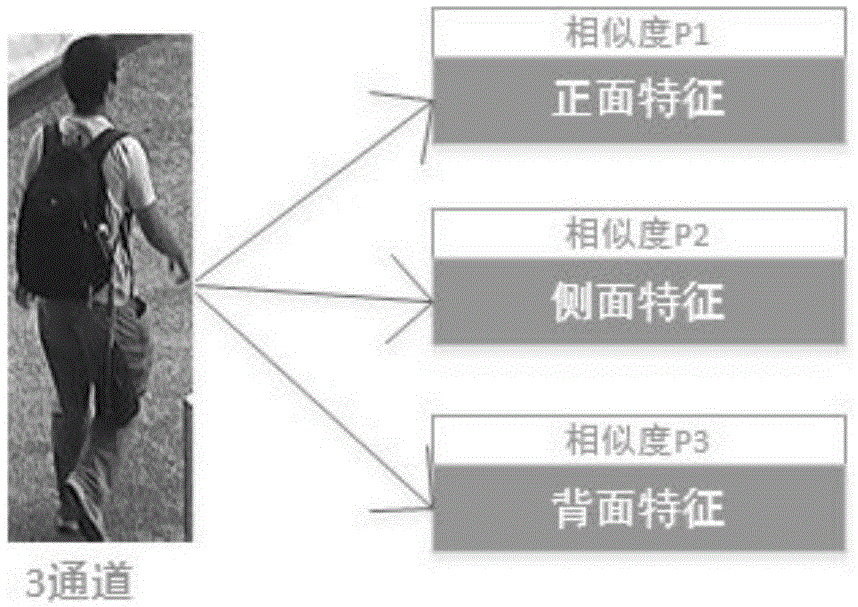
一、构造多视角图像特征分解神经网络,实现行人图像从不同视角进行描述(如图1所示)
1.建立多视角图像特征分解神经网络的训练数据集和测试数据集
在行人图像数据集中,选取标准的正面图像,侧面图像,背面图像(如图2所示,图中(a)为行人正面图像,(b)行人侧面图像,(c)为行人背面图像),其他角度的图像不选取,选取的标准图像如图2所示,将选好的标准图像分成训练数据集和测试数据集两部分。训练数据集中正面行人图像1713张,侧面行人图像1737张,背面行人图像1722张,共计5172张;测试数据集中正面行人图像170张,侧面行人图像256张,背面行人图像124张,共计550张。
2.数据集预处理
将数据集中行人图像经过缩放或裁剪成分辨率为192×64的rgb图像。
3.通过改进胶囊分类网络capsulenet的结构,构造多视角图像特征分解神经网络
标准胶囊网络capsulenet第一层为卷积层,卷积核为7×7;第二层为初级胶囊层,卷积核7×7,输出通道数8;第三层为编码胶囊层,输出通道数10,路由数3,输出维度b×10×16,b为超参数批处理数量,如图3所示。
改进后的胶囊网络capsulenet的第一层设置为卷积层,参数:卷积核5×5、输出通道数32、输入维度为b×3×192×64,b为超参数批处理数量;第二层设置为卷积层,参数:卷积核5×5、输出通道数256;第三层为初级胶囊层,参数:卷积核5×5,输出通道数8;第四层为编码胶囊层,参数:输出通道数3,路由参数2,输出维度为b×3×64,b为超参数批处理数量。如图4所示。
改进的胶囊网络capsulene的前两层是特征提取层,特征提取层可以选用其它特征提取网络,例如单层神经网络,resnet,hourglassnet等。从实验结果来看,复杂的特征提取网络会对行人再识别的结果有1%-3%的提升作用。
4.训练多视角图像特征分解神经网络
通过在标准视角行人图像训练集上进行训练,训练迭代次数epoch为10,训练结束时,多视角图像特征分解神经网络准确率为98%,整体损失函数值为0.016。
5.获得多视角行人多视角图像特征以及对应的相似度
将预处理的图像输入多视角图像特征分解神经网络,通过多视角图像特征分解神经网络对图像进行多视角图像特征分解,获得不同视角的图像特征值以及对应的相似度,同一行人图像不同视角下的图像特征值进行softmax计算得到相应的相似度pi1,pi2,pi3,其中i表示第i个行人图像。如图1所示。
视角相似度计算公式为:
二、确定不同视角下的特征转换矩阵,计算转换系数
1.利用bp神经网络确定特征转换矩阵,求解特征转换矩阵采用如下步骤:
步骤1、建立数据集,数据集中包含同一行人不同视角的特征对{vi,ui},特征vi和ui具有相同的维度d,其中vi,ui表示某视角下的行人特征编码,本实施例中选取d=64,维度d也可以选其他数值:128,256等;
步骤2、按照图5示意,建立并训练特征转换网络,特征转换网络是两层的bp神经网络,网络输入层数据为vi,输入层维度1×d,网络输出层数据为ui’,输出层维度1×d,损失函数为:loss(x)=1-cos(ui’,ui),其中ui’表示网络转换特征,ui表示目标特征
步骤3、特征转换网络经过训练后,损失函数降低到0.07以下,从特征转换网络提取转换矩阵w,ui’=w*vi,w是d×d的矩阵,本实施例中w是64×64的矩阵;
步骤4、重复步骤2和步骤3,将所有的不视角的图像特征转换矩阵都计算一次,得到所有跨视角特征转换矩阵。
2.计算特征转换系数矩阵
通过跨视角特征转换网络将特征进行转换,在特征转换的过程中存在一定概率转换误差,跨视角特征转换网络的损失函数的值不为零,所以跨视角图像特征度量的结果必须乘以转换系数alpha,转换系数alpha用于减少特征转换的误差。
跨视角行人特征转换网络的损失函数值表示不同视角特征转换的差异度,取平均损失函数值为t,转换系数的取值为
不同视角的转换系数组成转换系数矩阵矩阵为:
其中a12表示行人正面特征到侧面特征的转换系数,a13表示行人正面特征到背面特征的转换系数,a21表示行人侧面特征到正面特征转换系数,a23表示行人侧面特征到背面特征的转换系数,a31表示行人背面特征到正面特征转换系数,a32表示行人背面特征到侧面特征的转换系数。
在本实施例中,转换系数矩阵为:
三、选择行人图像相似度度量函数,实现行人再识别
选择cos函数进行行人特征距离度量,行人特征距离度量如下:
f(x,y)=alpha×cos(x,y)
根据任意两张行人图像多角度特征的相似度进行判断(如图6、7所示),如果相似度最大的特征是同视角特征,选择直接比较方式,行人特征距离为l=f(xi,yj);如果相似度最大的特征不是同视角特征,选择特征转换比较方式,行人特征距离为l=f(w×xi,yj),w为转换矩阵,alpha为转换系数。
行人再识别时,在被检索行人图像集中选取任意一对行人图像(x,y),计算行人特征距离度量函数的值,对被检索行人图像距离度量结果进行降序排序,排序结果中前面的行人图片即是行人图像再识别结果。
四、实验样本量确定
本实施例选取行人图像样本共28193张,其中训练样本27145张,测试测试样本1048张。
五、行人再识别实验效果
在本实施例选取的数据集上,特征向量d分别选取16维、32维、48维、64维等4种维度,测试准确率选取rank1,rank5,rank10,rank15,rank20,rank表示在一定范围内包含正确的检索图像。从测试结果可以看出再识别结果中,行人图像特征选取64位时,一次命中rank1达到了88%以上,前五命中rank5达到了95%以上,前20命中rank20达到了98%以上。行人再识别检测结果如图9所示,数据测试结果如图8所示。
本方法将生成多视角图像特征看作多分类问题。在多分类问题中,通过多分类网络最后一层softmax归一化处理后生成各个分类的概率,这个概率表示输入与各种分类的相似度。例如:多分类网络的结果经过softmax归一化处理后得到属于类别1的概率是50%,属于类别2的概率是49%,属于类别3的概率是1%,那么分类结果表示与类别1的相似度为50%,与类别2的相似度为49%,与类别3的相似度只有1%。
本发明借助capsulenet多分类网络实现了3视角图像特征分解神经网络。首先,利用了capsulenet多分类网络实现了行人图像的视角分类,分类结果中的三个概率值就是与标准视角的相似度,如分类结果中正面视角的概率是60%,说明此行人图像与标准正面像相似度有60%,该图像中60%的部分包含了行人的正面图像特征。其次,由于capsulenet多分类网络可以生成分类对应的特征向量,本方法通过capsulenet多分类网络不仅可以生成三个标准视角的相似度还生成了三个标准视角下的图像特征,在本方法中根据三个标准视角的相似度以及相应的图像特征进行图像相似度判别。
本实施例中行人图像相似度的判别采用cosine距离作为基本判别方法。在行人图像相似度计算的过程中,如果两幅行人图像的多视角分类结果相同,即概率最大的视角是同一视角分类,行人图像相似度采用该视角下对应的图像特征进行cosine计算,计算的结果即行人图像相似度;如果两幅行人图像的多视角分类结果不相同,即概率最大的视角不是同一视角分类,行人图像相似度计算采用将某个视角下(概率最大)对应的图像特征进行跨视角转换后再进行cosine计算,计算的结果即行人图像相似度。通过跨视角图像特征转换行人图像相似度cosine计算存在一定的误差,本方法通过在转换结果前乘以一个转换系数alpha,转换系数用于减少转换误差。
本实施例中行人图像特征跨视角转换通过转换矩阵乘法的形式计算,跨视角行人图像特征是通过视角转换矩阵和原视角行人图像特征向量相乘得到。视角转换矩阵是通过提取视角转换神经网络中的系数获得的,本实施例中有3个标准视角,总共需要6个视角转换矩阵。
上面仅对本发明的较佳实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化,各种变化均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!