一种基于分层狄利克雷模型的文本分割方法与流程
本发明属于文本分割技术领域,尤其涉及一种基于分层狄利克雷模型的文本分割方法。
背景技术:
随着网络的快速发展,人们逐渐跨入全新的网络时代,各种电子文本信息更是以爆炸性的速度增长。各类海量信息在给社会带来便利的同时,同时也为文本处理与分析带来了巨大的挑战,比如如何从这海量信息中快速准确的获得有效信息等。文本分割则是以主题相关的原则对文本进行分割,使得各语义段落之间具有最小的相似度,各语义段落内具有最大相似度,据此来寻找不同主题的边界。
文本分割常用的方法有基于词汇聚集的方法、基于语言特征的方法和基于主题模型的方法。基于词汇聚集的方法忽略了词与词之间的关系,因而分割的准确性有限;基于语言特征的方法无法适用于所有的语料库,在特定的领域分割的效果较好。石晶等人提出了概率潜在语义分析模型和潜在狄利克雷模型的分割方法,ridel等人将texttiling和lda模型相结合,通过对lda模型每次采样得到的主题分布进行统计以确定最终的主题分布,提高了主题模型对文本表示的稳定性。上述这些方法都是基于主题模型的方法,该类方法能够反映出文本语义信息,因此提高了文本分割的准确性。然而基于lda的texttiling方法依赖于主题个数的人工设置。在实际应用中,主题个数的设置对文本分割效果的影响很大,如果主题个数设置过高会造成训练过拟合,设置过低会造成对文本的描述不够全面。
传统文本分割算法普遍依赖于主题个数的人工设置,对于大型语料库很难去估计其中的主题个数,容易造成过拟合或者对文本描述不全面。
技术实现要素:
为解决上述问题,本发明提出一种基于分层狄利克雷模型的文本分割方法,使得文本分割不再依赖于主题个数的人工设置。
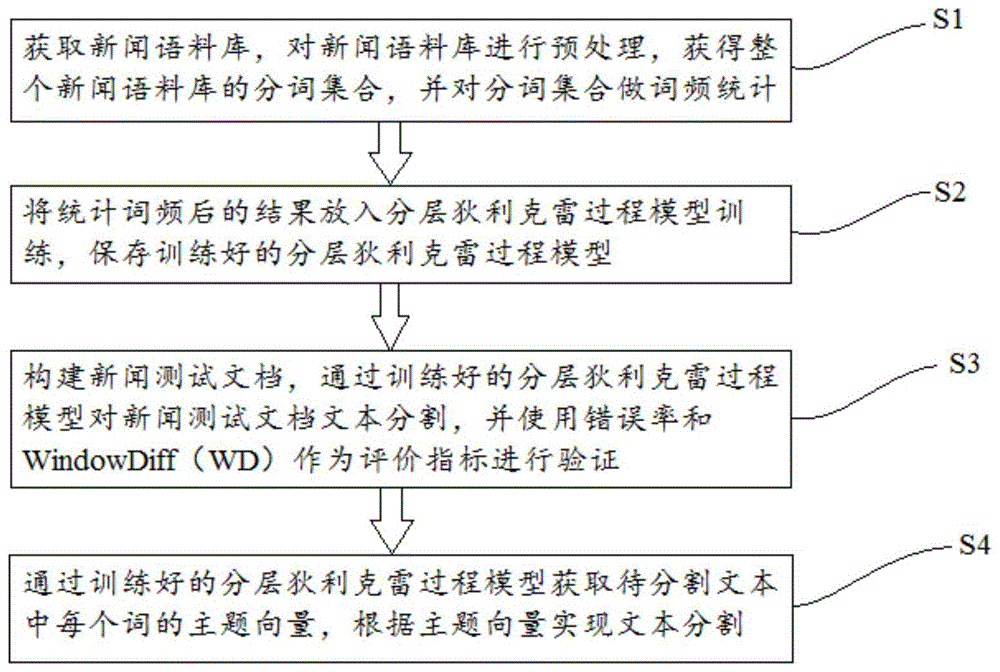
一种基于分层狄利克雷模型的文本分割方法,包括以下步骤:
s1,获取新闻语料库,对新闻语料库进行预处理,获得整个新闻语料库的分词集合,并对分词集合做词频统计;
s2,将统计词频后的结果放入分层狄利克雷过程模型训练,保存训练好的分层狄利克雷过程模型;
s3,通过训练好的分层狄利克雷过程模型获取待分割文本中每个词的主题向量,根据主题向量实现文本分割。
优选的,在所述步骤s2~s3之间还包括:构建新闻测试文档,通过训练好的分层狄利克雷过程模型对新闻测试文档文本分割,并使用错误率pk和windowdiff作为评价指标进行验证。
优选的,所述获取新闻语料库,对新闻语料库进行预处理,获得整个新闻语料库的分词集合,并对分词集合做词频统计包括以下步骤:
s11,利用beautifulsoup库解析新闻语料库中的html文本,保留文本信息;
s12,利用ictclas平台对文本信息进行词语切分,去除无用的介词、虚词、数词词语,提取关键的词语进行处理,在得到新闻语料库的分词集合后利用词袋doc2bow实现词频统计。
优选的,所述将统计词频后的结果放入分层狄利克雷过程模型训练,保存训练好的分层狄利克雷过程模型包括以下步骤:
s21,设新闻语料库中的每篇文本的主题都来源于基分布h,从基分布h中获取该新闻语料库的总体基分布g0~dp(γ,h),其中γ是聚集参数;
s22,构造每一篇文本的主题分布:gj~dp(α0,g0),j=1,2,…,m,其中g0表示总体基分布,α0为聚集参数;
s23,以每一篇文本的主题分布为基础,构造分层狄利克雷模型:
θji|gj~gj,xji|θji~fθji)
其中fθji)表示在给定参数θji的情况下,变量xji的分布;参数θji条件独立服从gj分布,变量xji条件独立服从f(θji)分布,xji表示第j篇文本的第i个词。
优选的,所述通过训练好的分层狄利克雷过程模型获取待分割文本中每个词的主题向量,根据主题向量实现文本分割包括以下步骤:
s31,构建主题向量
对待分割文本进行预处理,得到待分割文本的分词集合并统计词频,将统计词频后的结果放入分层狄利克雷过程模型,分层狄利克雷过程模型在每次迭代推理过程中为每个词分配主题id,设主题向量表示为:t=(topic1,topic2,…,topicn),其中topict为主题idt在待分割文本中出现的频率;n表示分层狄利克雷过程模型自动生成的主题个数;
s32,主题向量的余弦相似度计算
以一个句子sn作为待分割文本中的最小的基本单位,使用分层狄利克雷过程模型得到的主题向量作为句子的表示,得到句子e和f的主题向量se=(x1,x2,…,xn),sf=(y1,y2,…,yn),n表示分层狄利克雷过程模型自动生成的主题个数;在相邻句子间的每个位置p,计算相邻句子的相似度cp:
其中se和sf表示句子e和f的主题向量;
s33,实现文本分割
计算每个位置p的深度值dp,通过查看左右两侧的最高相似度来测量最小深度值,判断公式:dp=1/2(hl(p)-cp+hr(p)-cp),
其中,函数hl(p)返回序列间隙索引i左侧的最高相似度,hr(p)则返回右侧的最高相似度,基于深度分数搜索局部最大位置,对获得的最大值得分进行排序,如果输入n个段落,则将n个最高深度值作为判断语义段落边界的依据,否则如果深度值大于α-β/2,则预测出边界,其中α表示平均深度值,β表示在深度值的标准偏差。
优选的,所述错误率pk的计算方法如下:
pk=p(s)*p(miss)+p(false_alarm)(1-p(s))
其中p(s)表示距离为k的两个句子属于不同语义段落的概率;相反1-p(s)就表示距离为k的两个句子属于相同段落的概率;p(miss)表示算法分割结果缺少一个段落的概率;p(false_alarm)则表示算法分割结果添加一个段落的概率。
优选的,所述windowdiff的计算方法如下:
其中ref表示文档的真实分割;hyp表示算法分割;函数b(i,j)表示整句sentencei和整句sentencej的边界数量;s_n表示文本中整句的数量;设k为真实分割中片段平均长度的一半。
通过使用本发明,可以实现以下效果:该方法使得文本分割不再依赖于主题个数的人工设置,通过分层狄利克雷过程模型自动生成主题向量,提高了文本分割的效率。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1是本发明实施例的整体流程示意图;
图2是本发明实施例中步骤s1的流程示意图;
图3是本发明实施例中步骤s2的流程示意图;
图4是本发明实施例中步骤s4的流程示意图。
具体实施方式
以下结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
本发明的主要思想是对待分割文本进行预处理,得到待分割文本的分词集合并统计词频,将统计词频后的结果放入分层狄利克雷过程模型,分层狄利克雷过程模型在每次迭代推理过程中为每个词分配主题id,从而得到主题向量。该方法使得文本分割不再依赖于主题个数的人工设置,通过分层狄利克雷过程模型自动生成主题向量,提高了文本分割的效率。
如图1所示,本发明实施例提出一种基于分层狄利克雷模型的文本分割方法,包括以下步骤:
s1,获取新闻语料库,对新闻语料库进行预处理,获得整个新闻语料库的分词集合,并对分词集合做词频统计;
如图2所示,具体包括以下步骤:
s11,利用beautifulsoup库解析新闻语料库中的html文本,保留文本信息;
新闻语料库中包含了很多脚本代码,利用python的beautifulsoup库解析html文本,保留有用的文本信息。
具体还包括:
去除链接地址:链接地址显然也需要在进一步分析前被去掉,可以使用正则表达式达到这个目的。
去除停用词:停用词是在每个句子中都很常见,但对分析没有意义的词。比如英语中的“is”、“but”、“shall”、“by”,汉语中的“的”、“是”、“但是”等。语料中的这些词可以通过匹配文本处理程序包中的停用词列表来去除。
词干化:指的是将单词的派生形式缩减为其词干的过程,已经有许多词干化的方法。词干化主要使用在英文中,如“programming”、“programmer”、“programmed”、“programmable”等词可以词干化为“program”,目的是将含义相同、形式不同的词归并,方便词频统计。
去除标点符号:标点符号显然对文本分析没有帮助,因此需要去除。
s12,利用中科院计算所的ictclas平台对每一篇文本进行词语切分,去除那些出现频率很高但是对文本分割作用不大的介词、虚词、数词词语,提取出关键的名词、形容词等重要词语进行处理,在得到新闻语料库的分词集合后利用gensim的doc2bow实现词频统计。
s2,将统计词频后的结果放入分层狄利克雷过程模型训练,保存训练好的分层狄利克雷过程模型;
如图3所示,具体包括以下步骤:
s21,对整个新闻语料库,为了保证各个文本之间能共享主题,设每篇文本的主题都来源于基分布h,从h中获取该新闻语料库的总体基分布g0~dp(γ,h),其中γ是聚集参数;
s22,构造每一篇文本的主题分布:gj~dp(α0,g0),j=1,2,…,m,公式中的g0就是s21过程中的主题分布,以g0为基分布,α0为聚集参数;
s23,以每一篇文本的主题分布为基础,构造分层狄利克雷模型:
θji|gj~gj,xji|θji~fθji)
其中fθji)表示在给定参数θji的情况下,变量xji的分布;参数θji条件独立服从gj分布,变量xji条件独立服从f(θji)分布,xji表示第j篇文本的第i个词。
s3,构建新闻测试文档,通过训练好的分层狄利克雷过程模型对新闻测试文档文本分割,并使用错误率pk和windowdiff(wd)作为评价指标进行验证。
其中,构建新闻测试文档的方法为:从新闻语料库中选取5000篇文档来制作测试语料库,每次从选取的新闻语料库中随机选10篇不同类别的文档,从每篇文档中提取4-10个凸显主题的句子形成段落,将这10个不同类别的段落重新组合成新的文档。重新组合的文档中每一个段落来自不同的类别,拼接的地方就是新文本的主题边界。
具体的,错误率pk的计算方法如下:
pk=p(s)*p(miss)+p(false_alarm)*(1-p(s))
其中p(s)表示距离为k的两个句子属于不同语义段落的概率;相反1-p(s)就表示距离为k的两个句子属于相同段落的概率,一般情况下p(s)取0.5;p(miss)表示算法分割结果缺少一个段落的概率;p(false_alarm)则表示算法分割结果添加一个段落的概率。
具体的,windowdiff(wd)的计算方法如下:
其中ref表示文档的真实分割;hyp表示算法分割;函数b(i,j)表示整句sentencei和整句sentencej的边界数量;s_n表示文本中整句的数量;设k为真实分割中片段平均长度的一半。
使用错误率pk和windowdiff(wd)作为评价指标进行验证,当错误率pk大于其设定阈值或者windowdiff(wd)大于其设定阈值,则需要对分层狄利克雷过程模型进行重新训练,当错误率pk小于其设定阈值且windowdiff(wd)小于其设定阈值,则验证通过。
s4,通过训练好的分层狄利克雷过程模型获取待分割文本中每个词的主题向量,根据主题向量实现文本分割。
如图4所示,包括以下步骤:
s41,构建主题向量
对待分割文本进行预处理,得到待分割文本的分词集合并统计词频,将统计词频后的结果放入分层狄利克雷过程模型,分层狄利克雷过程模型在每次迭代推理过程中为每个词分配主题id,设主题向量表示为:t=(topic1,topic2,…,topicn),其中topict为主题idt在待分割文本中出现的频率;n表示分层狄利克雷过程模型自动生成的主题个数;
s42,主题向量的余弦相似度计算
以一个句子sn作为待分割文本中的最小的基本单位,使用分层狄利克雷过程模型得到的主题向量作为句子的表示,得到句子e和f的主题向量se=(x1,x2,…,xn),sf=(y1,y2,…,yn),n表示分层狄利克雷过程模型自动生成的主题个数;在相邻句子间的每个位置p,计算相邻句子的相似度cp:
其中se和sf表示句子e和f的主题向量;
s43,实现文本分割
计算每个位置p的深度值dp,通过查看左右两侧的最高相似度来测量最小深度值,判断公式:dp=1/2(hl(p)-cp+hr(p)-cp),
其中,函数hl(p)返回序列间隙索引i左侧的最高相似度,hr(p)则返回右侧的最高相似度,基于深度分数搜索局部最大位置,对获得的最大值得分进行排序,如果输入n个段落,则将n个最高深度值作为判断语义段落边界的依据,否则如果深度值大于α-β/2,则预测出边界,其中α表示平均深度值,β表示在深度值的标准偏差。
本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!