岸桥QC、集卡YT和龙门吊YC的集成调度模型及其GA算法的制作方法
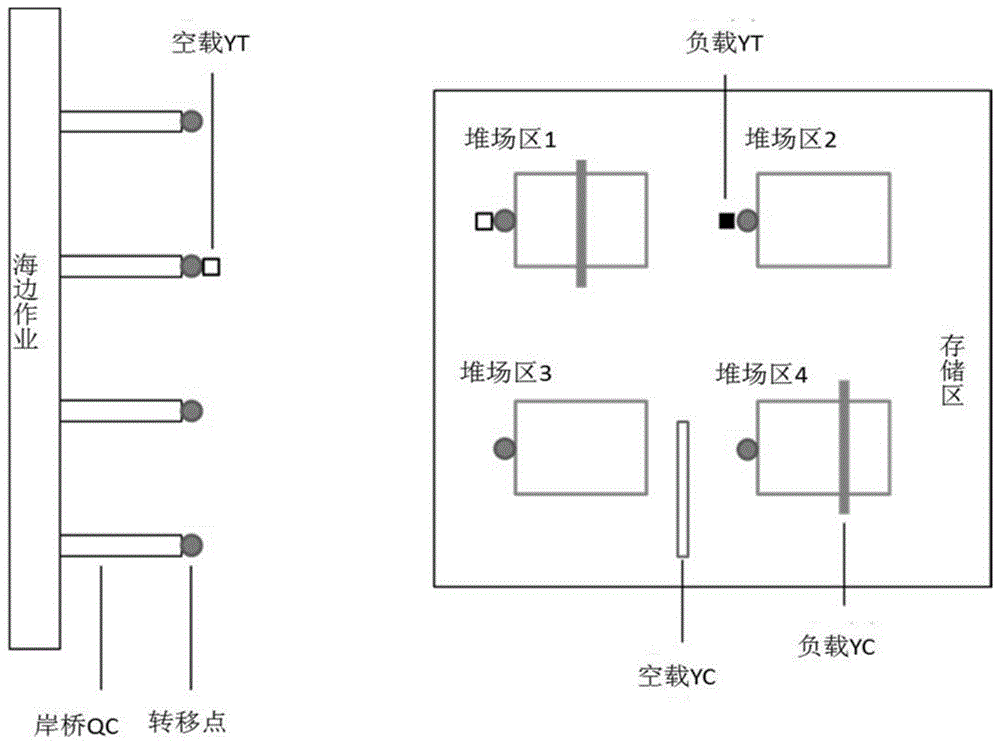
本发明涉及港口核心资源集成调度模型及算法。
背景技术:
:贸易全球化促进了全球物流和运输业的发展,特别是海运集装箱港头(containerterminals,简称ct),港口的运营效率对国际贸易和国家经济的增加有直接的影响。船舶周转时间是船舶在泊位上所花费的总时间,是评价港口效率的一个关键指标[1],能够使船舶周转时间短的高效港口更具有竞争力并将在世界上保持领先地位。为实现这一目标,需要港口内部各资源的相关活动开展密切的合作。在大多数港口中,集装箱的标准尺寸为20英尺等效单位,主要使用三种大型设备来完成集装箱的转移[2],他们分别是岸桥(quaycrane,简称qc),集卡(yardtruck,简称yt)和龙门吊(yardcrane,简称yc)。qc位于码头区,负责将集装箱装载到船上或者从船上卸下集装箱。yc在堆场中用于将集装箱从yt放入其相应的存储位,或者将集装箱放置到yt上,yt工作于qc和yc之间运送集装箱。由于起重机(qc和yc)与yt之间没有缓冲空间,因此港口中可能会出现停滞状态。例如,当qc或yc吊起集装箱时,它需要将集装箱放在可用的yt上而不是直接将其放在地上,因为yt需要起重机的帮助才能装载集装箱。因此,如果没有空载yt将起重机吊起的集装箱进行转移,qc和yc则无法继续下一个任务,直到有空载yt到达。而在另一方面,集装箱只能一直保持在yt上,直到有qc或yc将集装箱吊起,将其装载入船或堆放至储位中。由于起重机和yt之间的存在前后配合不协调的情况,从而导致系统发生停滞情况。忽视起重机和yt之间的这种相互协作关系会导致不能保证全局最优性,因此,当在港口集成模型中同时考虑qc,yt和yc三大主要设备的运作过程时,能够大大提升港口系统的整体性能。随着港口系统重要性的日益增加,目前针对港口资源的相关问题已有了大量研究。适当安排qc,yt和yc等有限资源会直接影响港口的运营效率,但以往的研究主要集中在港口单资源调度问题,如qc调度问题,yt调度问题,yc调度问题。李等[3]研究了考虑qc不可跨越这一约束条件的qc调度问题,并建立了mip模型和开发了ga来解决此问题。文中作者指出qc调度问题是np-complete。tavakkoli-moghaddam等[4]研究了qc调度和分配问题。鉴于对qc调度问题的研究越来越多,meisel和bierwirth[5]提出了一个一般化的的方法来评估不同的qc调度模型和相应的求解过程。bish等[6]针对港口单艘货船研究了车辆调度问题,目标函数是船舶总完工时间最短,重点工作是调查车辆的分派或部署对港口吞吐量的影响。对于港口的其他方面,包括卸载集装箱的储位选择,车辆移动路线和交通控制等,都作为给定的已知数据。ng等[7]对一组卡车调度问题进行了研究,问题中考虑了与序列相关的设备处理时间和不同的准备时间,其目标是尽量减少总完工时间。ng和mak[8]求解了港口单台yc的调度问题,目标是最小化作业总等待时间,其中考虑了装载作业和卸载作业具有不同的准备时间这一约束条件。jung和kim[9]将单台yc调度问题扩展到多台yc调度问题,他们仅考虑了装载作业,目标函数是最小化总完工时间。heetal.[10]设计了一种混合遗传算法来解决港口yc调度问题,与以往很多论文不同的是,他们考虑的yc需要在不同的堆场区之间移动以便充分利用yc。上述所有研究主要针对港口中单一资源的调度问题,而忽略了与此资源作业过程中具有关联性的其他资源设备。这通常会不能保证港口的整体性能,因此,一些研究人员已经开始对港口中不同设备资源的集成问题展开了研究工作。bierwirth和meisel[11]对港口中的泊位分配和qc调度集成问题进行了相关文献的总结。他们指出,港口集成问题将受到更多关注,并成为未来港口问题研究的新趋势。cao等[12]提出了yt和yc在出口集装箱装载作业中的集成调度问题,建立了mip模型并利用bender分解方法来解决该集成模型。在文献[1,13-14]中均阐述了在港口中研究多种类型设备资源集成问题的重要性。chenetal.[1]提出了一种基于ts的算法来求解qc、场地车辆和yc的集成调度问题,他们假设每个堆场区都有特定的yc,yc不需要在堆场区之间进行移动,并且每台yc只能负责一种操作模式,即将出口集装箱运出堆场或者将进口集装箱放入其相应储位。在lau和zhao[13]的论文中,提出了一个qc、自动导引车和自动yc的集成调度模型,在他们的模型中,假设每个堆场区都具有指定的yc。上述两种模型对改善港口中不同装卸设备工作中的协作性有很大益处。然而,chenetal.[1]和lau和zhao[13]所采用的假设对于一些具有多个堆场区但资金支持相对有限的中小型港口而言,在现实中具有一定执行难度,由于yc设备价格高昂,而不同存储区共享yc不会增加yc的潜在成本。此外,heetal.[10]在他们的研究中也已经提到过,有限的设备资源yc在很多港口并没有得到很充分的利用。在港口中,有一种被广泛使用的yc,即橡胶轮胎龙门起重机(rubbertiredgantrycranes,简称rtgc),它装有橡胶轮,可以在堆场区之间进行移动,使用rtgc可以大大提高港口运营的灵活性。由于其具有移动性和灵活性的特征,rtgc已经成为香港以及世界各地的港口中最常用的装卸设备之一[15-17]。由于yc设备非常昂贵,因此在某些港口中不能满足每个堆场区都具有一台yc。为了充分利用yc并克服堆场区之间的工作负载不平衡,yc需要通过共享和再分配以缓解工作负载[10]。此外,yc的调度计划通常由港口管理人员根据他们的工作经验制定,但这种方式不能保证每个班次的安排效率。而低效的yc调度计划可直接降低堆场区中的生产效率,从而影响港口的整体性能。技术实现要素:本发明的目的的是提供一种岸桥qc、集卡yt和龙门吊yc的集成调度模型,它是一种港口核心资源集成调度模型,它考虑了堆场区之间yc移动和yc分配,能够改善港口中不同装卸设备工作中的协作性,提升港口的整体性能。为解决上述问题,本岸桥qc、集卡yt和龙门吊yc的集成调度模型为:minimizecmax(1)其中:公式(1)描述了模型的目标函数;约束条件(2)定义了所有集装箱的总完工时间;约束条件(3)计算每个作业的完成时间,并表明在通过yt将该作业转移到相应qc之后,qc可以立刻对该作业进行装载;约束条件(4)确保在通过yc将集装箱转移到储位的转移点之后,yt可以开始进行转移;约束条件(5a),(5b)定义了系统停滞状态:约束条件(5a)描述了在yce上作业i排在了作业j之前进行处理,约束条件(5b)描述了在ytk上作业i排在了作业j之前进行处理;约束条件(6a),(6b)分别限制了每个yt和每个yc从其初始位置开始其第一项任务;约束条件(7a),(7b)确保qcq上不能同时处理任务对(i,j)所包含的工作i和j;约束条件(8a),(8b)确保每个作业仅分配给一个yt和一台yc;约束条件(9a)描述了如果作业i和j由ytk先后进行运送,则必须将作业i和j分配给ytk;约束条件(9b)针对yc限定了同样的约束;约束条件(10a),(10b)分别确定了每个yt和每个yc的首任务。约束条件(11a)描述了如果作业i是ytk的第一个任务,则必须将作业i分配给ytk;约束条件(11b)描述了如果作业i是yce的第一个任务,则必须将作业i分配给yce;约束条件(12a)-(12c)确定每个yt上的作业顺序;约束条件(13a)-(13c)确定每台yc上的作业顺序;约束条件(14)对0-1整数决策变量进行了限定。本发明同时提供了一种集成调度模型的ga算法,它一种基于ga的优化算法,能够在合理的计算时间范围内找到最优解或满意解。为解决上述问题,本发明所述的集成调度模型求解的ga算法,其步骤包括:读取输入数据开始,根据输入数据,创建和评估初始种群;在每一次迭代中,并行地执行三对交叉算子和变异算子来产生后代,然后对其进行评估;新种群通过混合选择策略来构建;当满足终止条件时,则算法运行结束。作为对上述的ga算法的进一步改进,种群解中的每一个单解称为染色体;每个染色体表示一个为3×njob的数组,记作π,它有三个维度且具有相同的长度:作业的装载顺序,名为π(1);π(1)中每个工作的yt分配,记为π(2);π(1)中每个工作的yc分配,命名为π(3);将π(a)定义为π(a)={π(a)(1),π(a)(2),…,π(a)(njob)}(a=1,2,3);根据π(1)中qc的装载顺序,yt和yc上的作业序列分别从π(2)和π(3)获得;染色体π中每个作业π(1)(i)(i=1,2,…,njob)的完成时间的计算过程如下:a)初始化:a.1设置i=1.a.2设置并且a.3设置b)计算工作π(1)(i)在ycπ(3)(i)上的完成时间:b.1计算ycπ(3)(i)的到达时间和完成时间:ayc[π(3)(i)]=ryc[π(3)(i)]+dpyc[π(3)(i)],b(π(1)(i))/sycfyc[π(3)(i)]=ayc[π(3)(i)]+hycb.2将ycπ(3)(i)的所在位置更新为b(π(1)(i)).pyc[π(3)(i)]=b(π(1)(i))c)计算工作π(1)(i)在ytπ(2)(i)上的结束时间:c.1计算ytπ(2)(i)的到达时间:ayt[π(2)(i)]=ryt[π(2)(i)]+dpyt[π(2)(i)],b(π(1)(i))/sytc.2对出口集装箱而言,当任务集装箱即工作π(1)(i)被放置于ytπ(2)(i)时,设备资源ycπ(3)(i)被释放,因此,ycπ(3)(i)在被释放后的处于可用状态的时间可计算为:ryc[π(3)(i)]=max{ayt[π(2)(i)],fyc[π(3)(i)]}然后,ytπ(2)(i)的完成时间可计算为:fyt[π(2)(i)]=ryc[π(3)(i)]+db(π(1)(i))qc(π(1)(i))/sytc.3则ytπ(2)(i)所处位置可更新为qc(π(1)(i)).pyt[π(2)(i)]=qc(π(1)(i))c.4对于出口集装箱而言,当任务集装箱π(1)(i)被所分配的qc从ytπ(2)(i)中转移走后,设备ytπ(2)(i)被释放处于待用状态,因此,设备ytπ(2)(i)的释放时间可计算为:ryt[π(2)(i)]=max{fyt[π(2)(i)],fqc[qc(π(1)(i))]}d)计算工作π(1)(i)在其所指定qc上的装载完成时间:cπ(1)(i)=fqc[qc(π(1)(i))]=ryt[π(2)(i)]+hqce)计算所有任务的总完工时间cmax:如果i=njob,则cmax=max{cπ(1)(i)|i=1,2,…,njob},否则,设置i=i+1,算法跳转到步骤b)。作为对上述的ga算法的进一步改进,初始种群解的生成方法:随机初始化π(1)中njob个作业的qc装载序列,随机产生π(2)中的每个ytk(k∈st),随机产生π(3)中的每个yce(e∈sc);新一代种群解的产生方法:基于三维染色体,设计了三对交叉算子和突变算子:crossover_1&mutation_1,crossover_2&mutation_2,crossover_3和mutation_3;crossover_1和mutation_1应用于π(1),同时保持其yt和yc的分配不变;对π(2)上执行crossover_2和mutation_2,同时保持π(1)和π(3)不变;在π(3)上执行crossover_3和mutation_3,同时保持π(1)和π(2)不变;在每一次迭代中,以并行的方式执行三对交叉算子和突变算子以产生新一代的种群解。作为对上述的ga算法的进一步改进,crossover_1使用顺序交叉算子,crossover_2和crossover_3采用两点交叉算子。作为对上述的ga算法的进一步改进,使用确定性选择和轮盘赌选择在内的混合选择策略来选择后代染色体。作为对上述的ga算法的进一步改进,变异算子mutation_2或者mutation_3采用启发式变异算子;在mutation_2中,固定父代染色体的π(1)和π(3),通过将分配给作业π(1)(i)(i=1,2,…njob)的yt逐个变换为其余的(nyt-1)yt中任何一个;通过mutation_2来改变一个工作的yt分配,产生(nyt-1)个邻域解;因此,在mutation_2中共生成njob×(nyt-1)个邻域解;对每个邻域解进行评估,并选择其中具有最小完工时间的邻域解作为后代染色体。作为对上述的ga算法的进一步改进,变异算子mutation_3采用启发式变异算子;在mutation_3中,固定父代染色体的π(1)和π(2),通过将分配给作业π(1)(i)(i=1,2,…njob)的yc逐个变换为其余的(nyc-1)yc中任何一个;通过mutation_3来改变一个工作的yc分配,产生(nyc-1)个邻域解;因此,在mutation_3中共生成njob×(nyc-1)个邻域解;对每个邻域解进行评估,并选择其中具有最小完工时间的邻域解作为后代染色体。作为对上述的ga算法的进一步改进,mutation_1是基于交换突变实现。本发明的有益效果:本专利提出的集成模型中考虑了堆场区之间yc移动和yc分配,并建立了混合整数规划模型和一种基于ga的优化算法,以获得总体最优或近似最优解。本专利对港口三种核心设备资源qc,yt和yc的集成调度模型,我们将其命名为i_qcytyc,其目标函数是总完工时间最小化,此目标能够直接反映船舶的周转时间。我们提出并求解港口多资源qc,yt和yc的集成调度问题,在此问题中,我们考虑了yc在不同堆场区的分配和移动,而也可将它看作是每个堆场区都有一台专用yc的一般化模型。对于设定专用yc的这种特殊情况,则不需要分配yc,可以通过在约束条件中对yc的选择进行具体的限定,便可以使用本模型进行求解。目前大多数港口采用分别安排装载和卸载的方式(即装载操作在所有卸载操作完成后开始),在专利中,仅针对出口集装箱的装载过程进行集成性研究。但是此专利所提出的方法不仅限于装载操作,同时对于卸载操作过程也是适用的。在本集成问题中,假设各船舶的qc分配已经确定,而且根据集装箱的类型和集装箱的运输目的地,每个集装箱在船上的位置也是预先指定的。也就是说,每个集装箱都有一个预先指定好的qc,我们需要做的是确定每台qc上各集装箱的装载序列。而在分配决策方面,除了需要确定yt分配,还要确定yc在不同堆场区之间的分配问题,因为yc并不指定给某一个堆场区,为的是充分利用资源yc并降低其潜在的投资成本[10]。可见,i_qcytyc的目的是对三个相关子问题同时做出决策:每台qc上集装箱的装载顺序,集装箱的yt分派,堆场区的yc分派。为求解此集成问题,开发了一个混合整数规划模型(mip)以找到最佳调度方案。然而,由于单独一个子问题yt调度问题属于np-hard[7],i_qcytyc也是np-hard问题,因为当其他两个子问题被视为已知数据时,它便可以简化为yt调度问题。通过使用数学规划模型,很难解决大型的港口实际调度问题,因此,我们提出了一种易于实现的基于ga的优化算法。最后的实验结果表明,该算法能够有效地为i_qcytyc找到了优质解或满意解。此集成调度问题需要同时对三个子问题做出决策:qc的装载顺序,yt调度计划和yc调度计划。为了匹配该集成问题的结构特征,在所提出的算法中设计了一个三维解方案表达式,该表达式是通过考虑三个装卸设备的相互协作关系将三个子方案进行集成。因此,相对应地设计了三对交叉算子和突变算子,其中每对交叉算子和突变算子应用到其中一个子问题中。同时,我们提出了一种新的启发式突变算子,它能够提高ga寻找更好解方案的效率。本专利提出的集成调度模型及其ga算法的求解结果,减少设备空载行程和等待时间,提高各设备的利用率和协作性,从而尽快完成所有集装箱的装载工作。本专利的技术内容是名称为“碳排放约束下集装箱港口核心资源集成调度问题研究”的国家自然科学基金青年项目(71701099)的部分内容。附图说明图1是集装箱港口典型布局的示意图。图2是ga算法的流程图。图3是π(1)执行crossover_1的过程具体示例图。图4是π(2)执行crossover_2的过程具体示例图。图5是π(1)执行mutation_1的过程具体示例图。图6是算法ga_hm和ga_sm的收敛性分析图。具体实施方式下面结合具体实施例及附图对本发明进行详细说明。一、问题描述和数学公式图1给出了集装箱港口典型布局的示意图。货船沿着海边在泊位上停靠,并将一定数量的qc分配给各货船,集装箱存储地被分为几个储位区,并在每台qc和每个储位区之前均设有一个集装箱转移点。yt在转移点接收或者卸载集装箱。以出口集装箱为例,完成将集装箱装载到货船上这一过程需要经历三个阶段:首先,一组yc在存储区域内移动以从储位中获取所需的集装箱并将它们转移至到yt上;然后,yt将集装箱按照一定的路径运送至qc处;最后,qc将集装箱装载到货船上。这里假设每台yt或yc从其初始位置开始进入工作状态,且任何两个转移点之间的距离是预先给定的。为了完成出口集装箱的装载操作,需要前后顺序地利用yc,yt和qc来运送集装箱。因此,在i_qcytyc中,一个作业或任务被定义为一个集装箱完整的传送过程。集装箱的起始点和终止点分别是其储位区和被分配的qc,此处每个集装箱的指定储位、被分配的qc以及所有yt和yc的初始位置都是已知的。i_qcytyc模型的假设条件介绍如下:(1)在港口中使用均相同的yt和yc,每个集装箱可以使用任何一台yt或yc进行运输;(2)假设负载yt或yc和空载yt或yc以相同的速度移动;(3)yt使用单位容量,即每个yt一次只能运送一个20英尺标准当量的集装箱;(4)模型中将qc或yc处理一个集装箱的平均工作时间作为设备的操作时间,起重机(qc,yc)和yt之间的交接时间包含在起重机的操作时间之内。(5)不考虑特殊集装箱(例如危险品,动物或冷冻物品的集装箱)的装载,且前往同一目的地的出口集装箱装有相同或同类别的货物。所有集装箱可以堆叠在彼此的顶部,并且分配给相同qc的集装箱由该qc装载原则为先到先服务。(6)港口具有足够的空间用于装卸设备的移动,并且模型中不考虑诸如yt和yc的交通堵塞等控制问题。每个作业的完成时间是其qc和yc的处理时间,yt从作业的起点到目的地的行程时间以及等待时间的总和。当所需的装卸设备不可用或处于忙碌状态时,待处理集装箱则处于等待状态。通过减少每个集装箱的等待时间和yt和yc的空载行驶率,可以大大提高港口运营效率。而合理的qc装载顺序以及恰当地将yt和yc分配给集装箱则可以显着减少空载行程和等待时间。i_qcytyc模型的最终结果由qc,yt和yc的具体调度表组成,包括:(1)在qc,yt和yc上每个集装箱的开始时间和结束时间;(2)每台qc、yt和yc上的集装箱加工顺序,以及(3)yt分配和yc分配。本专利使用以下数学符号对i_qcytyc模型进行数学描述:符号:i,j表示岸桥、集卡或者龙门吊移转、运送某集装箱的任务,i,j=1,2,…,njob,njob=任务总数q表示岸桥qc的编号,q=1,2,…,nqc,nqc=岸桥总数qcq表示编号为q的岸桥qck表示集卡yt的编号,k=1,2,…,nyt,nyt=集卡总数ytk表示编号为k的集卡yte表示龙门吊yc的编号,e=1,2,…,nyc,nyc=龙门吊总数yce表示编号为e的龙门吊ycm,n表示岸桥qc和各堆场区的所在位置参数:qc(i)表示分配给任务i的岸桥qcb(i)表示在任务i中所处理的集装箱被存放的堆场区iptk集卡ytk的初始位置ipce龙门吊yce的初始位置dmn从位置m到位置n的距离hqc岸桥将集装箱从集卡转移到货船上所需要的平均处理时间hyc龙门吊将集装箱从堆场转移到集卡上所需要的平均处理时间syt集卡yt的移动速度syc龙门吊yc的移动速度m一个非常大的常数(i,j)任务对,包括分配给同一台qc所有任务中,其中任意两个任务i,j的组合,即qc(i)=qc(j)集合:l出口集装箱集合sq岸桥qc集合st集卡yt集合sc龙门吊yc集合spq任务对(i,j)的集合决策变量:cmax所有任务的总完工时间tyti任务i被其所分配的集卡yt运送到qc(i)对应的转移点的到达时间tyci任务i被其所分配的龙门吊yc运送到b(i)对应的转移点的到达时间ci任务i的完成时间,即任务i在qc(i)上的完成时间下面列出了所建立的mip模型:minimizecmax(1)公式(1)描述了模型的目标函数。约束(2)定义了所有集装箱的总完工时间。约束(3)计算每个作业的完成时间,并表明在通过yt将该作业转移到相应qc之后,qc可以立刻对该作业进行装载。其中,(ci-hqc)为任务i在qc(i)上的开始时间。约束(4)确保在通过yc将集装箱转移到储位的转移点之后,yt可以开始进行转移,其中,(tyti-db(i)qc(i)/syt)为yt开始执行任务i的开始时间。约束(5a),(5b)定义了系统停滞状态:约束(5a)描述了在yce上作业i排在了作业j之前进行处理,约束(5b)描述了在ytk上作业i排在了作业j之前进行处理。当工作i被其后面操作所需要的设备从当前设备(yc或yt)中释放之后,该设备便可以为其后续任务j进行服务。否则,工作i将不得不留在当前的处理设备上,直到工作i所需的下一台设备从当前的处理设备中将其释放出来。其中,(tyti-db(i)qc(i)/syt)为yt开始执行任务i的开始时间,(tyci-hyc)为yc开始执行任务i的开始时间。并且,此约束条件同时保证了任意一台yt或yc不能同时处理两项任务i和j。约束(6a),(6b)分别限制了每个yt和每个yc从其初始位置开始其第一项任务。约束(7a),(7b)确保qcq上不能同时处理任务对(i,j)所包含的工作i和j。约束(8a),(8b)确保每个作业仅分配给一个yt和一台yc。约束(9a)描述了如果作业i和j由ytk(即yijk=1)先后进行运送,则必须将作业i和j分配给ytk(即uik=1且ujk=1)。约束(9b)针对yc限定了同样的约束。约束(10a),(10b)分别确定了每个yt和每个yc的第一个执行任务。约束(11a)描述了如果作业i是ytk的第一个任务,则必须将作业i分配给ytk。约束(11b)描述了如果作业i是yce的第一个任务,则必须将作业i分配给yce。约束(12a)-(12c)确定每个yt上的作业顺序。约束(13a)-(13c)确定每台yc上的作业顺序。约束(14)对0-1整数决策变量进行了限定。二、解决方法由于i_qcytyc属于np-hard问题,使用精确方法解决港口的实际大型问题非常困难。因此,我们开发了一个基于ga的优化算法,希望能够在合理的计算时间范围内找到最优解或满意解。此集成调度问题需要同时对三个子问题做出决策:qc的装载顺序,yt调度计划和yc调度计划。为了匹配该集成问题的结构特征,在所提出的算法中设计了一个三维解方案表达式,该表达式是通过考虑三个装卸设备的相互协作关系将三个子方案进行集成。因此,相对应地设计了三对交叉算子和突变算子,其中每对交叉算子和突变算子应用到其中一个子问题中。同时,我们开发了一种新的启发式突变算子,以提高ga寻找更好解方案的效率。ga设计的目标是减少设备空载行程和等待时间,提高各设备的利用率和协作性,从而尽快完成所有集装箱的装载工作。ga的流程图如图2所示。ga从读取输入数据开始,根据输入数据,创建和评估初始种群。在每一次迭代中,并行地执行三对交叉算子和变异算子来产生后代,然后对其进行评估。新种群通过混合选择策略来构建。当满足终止条件时,则算法运行结束。1、染色体表示ga算法是从问题的初始种群解开始搜索的,种群解中的每一个单解称为染色体。针对i_qcytyc模型结构,每个染色体表示一个为3×njob的数组,记作π,它有三个维度且各维度具有相同的长度:作业的装载顺序,名为π(1);π(1)中每个任务的yt分配,记为π(2);π(1)中每个任务的yc分配,命名为π(3)。将π(a)定义为π(a)={π(a)(1),π(a)(2),…,π(a)(njob)}(a=1,2,3)。根据π(1)中qc的装载顺序,yt和yc上的作业序列分别从π(2)和π(3)获得。在每个解方案π中,每列中的基因对应给出了每个任务的yt和yc分配,而每行中的基因组则给出了qc,yt和yc上的作业序列。此处使用三维染色体的潜在好处是,通过将每项作业对应的yt和yc分配组合在同一列(每个作业具有预先设定的qc),为每个作业对应的qc,yt和yc的协作过程建立了联系。在执行交叉和变异算子之后,这些子解之间的连接关系有助于保持染色体中具有高适应度的基因组合。而这些优质染色体模式的保留相比独立的只考虑单一资源的解方案更有助于ga趋于收敛。下面通过一个具体示例问题来说明所提出的三维染色体。某港口具有三台qc和由三个堆场区。在表1中有10个作业,每个作业都有已分配的qc和储位。第一行中的数字1-10表示各作业的编号,第二行和第三行提供有关每个作业所分配的qc和储位区,数字1-3代表qc的编号,数字4-6代表堆场区编号。在这个例子中,总共有三台yt和两台yc,且每个yt和yc的初始位置在表2中给出。表110个任务qc和储位分配表jobi12345678910qc(i)2321332231b(i)4655644564表2yt和yc的初始位置对于这个例子问题,一个可行的染色体π可以定义为3×10矩阵,其中π(1)={2,4,1,6,3,8,9,7,10,5},π(2)={2,1,1,3,2,3,1,2,2,3},π(3)={1,1,2,2,1,2,1,2,2,1},如表3所示。π(1)是各作业在qc上的装载顺序,π(2)表示了π(1)中各作业的yt分配,π(3)表示了π(1)中各作业的yc分配。例如,从染色体的第一列基因中可以得知,yt2和yc1被分配给了作业2,而根据每个作业给定的qc和指定储位信息,由该染色体我们可以得出表4所示的qc,yt和yc的作业序列。表3一个针对示例问题的可行染色体π表4由表3所示问题解中所得到的各设备资源上任务的执行顺序表5显示了完成10个任务各yt和yc的行走路径。从中可以看出,当yt前往新任务或者yc在不同的堆场区之间移动以获取任务集装箱时,会发生空载行程,在表中用下划线做了标记。表5由表3所示问题解中所得到的yt运输路径和yc行走路径注意:表中数字表示岸桥qc和各个堆场区域,其中1-3代表岸桥,4-6代表堆场区域。__:yt或yc的空载路径2、初始种群解的生成群体中每个染色体的初始化包括三个部分:π(1)初始化,π(2)初始化和π(3)初始化。随机初始化π(1)中njob个作业的qc装载序列,随机产生π(2)中的每个ytk(k∈st),随机产生π(3)中的每个yce(e∈sc)。3、检验适应度对于每个染色体,目标函数值等于最后一个作业的完成时间。由于i_qcytyc是最小化问题并且其目标函数值(即完工时间)总是正数,因此在此问题中,我们将每个染色体πn对应的适应度fitness(n)设置为总完工时间的倒数,即fitness(n)=1/cmax。下面对染色体π中每个作业π(1)(i)(i=1,2,…,njob)的完成时间的计算过程描述如下:ycπ(3)(i):执行作业π(3)(i)的ycytπ(2)(i):执行作业π(2)(i)的ytqc(π(1)(i)):执行作业π(1)(i)的qcpyc[π(3)(i)]:ycπ(3)(i)当前所在位置pyt[π(2)(i)]:ytπ(2)(i)当前所在位置ayc[π(3)(i)]:ycπ(3)(i)为执行任务π(1)(i)的到达时间ayt[π(2)(i)]:ytπ(2)(i)为执行任务π(1)(i)的到达时间ryc[π(3)(i)]:ycπ(3)(i)释放掉任务π(1)(i)的时间,即ycπ(3)(i)可被使用的时间ryt[π(2)(i)]:ytπ(2)(i)释放掉任务π(1)(i)的时间,ytπ(2)(i)可被使用的时间fyc[π(3)(i)]:任务π(1)(i)在ycπ(3)(i)上的结束时间fyt[π(2)(i)]:任务π(1)(i)在ytπ(2)(i)上的结束时间fqc[qc(π(1)(i))]:任务π(1)(i)在qc(π(1)(i))上的结束时间dpyc[π(3)(i)],b(π(1)(i))表示ycπ(3)(i)从当前位置到达所要执行任务π(1)(i)所在存储区位置的距离,由上可知,syc是yc的移动速度,因此,dpyc[π(3)(i)],b(π(1)(i))/syc表示ycπ(3)(i)从当前位置出发到达执行任务π(1)(i)所在存储区所需要的时间。dpyt[π(2)(i)],b(π(1)(i))表示ytπ(2)(i)从当前位置到所要执行任务π(1)(i)所在存储区位置的距离,由上可知,syt是yt的移动速度,因此,dpyt[π(2)(i)],b(π(1)(i))/syt表示ytπ(2)(i)从当前位置出发到达执行任务π(1)(i)所在存储区所需要的时间。db(π(1)(i))qc(π(1)(i))表示ytπ(2)(i)从执行任务π(1)(i)所在存储区位置b(π(1)(i))将其运输到其所分配岸桥qc(π(1)(i)处,所需要移动的距离,而syt是yt的移动速度,因此,db(π(1)(i))qc(π(1)(i))/syt表示ytπ(2)(i)将任务π(1)(i)从存储区转移到岸桥位置所需要的移动时间。由于生成的染色体π满足mip模型中的约束条件(4.2.6a)-(4.2.12c),根据约束条件(4.2.1)-(4.2.5b)和π(1)中任务的装载顺序来逐一计算每个作业π(1)(i)(i=1,2,…,njob)的完成时间。由于每个作业接连由三个装卸设备yc,yt和qc进行转移,计算完成时间的核心程序包括以下三个步骤:(1)集装箱由yc完成转移的结束时间的计算,(2)集装箱由yt完成运输的结束时间的计算,以及(3)集装箱在qc上装载到货船上的完成时间的时间。而对于每个出口集装箱而言,其任务的最终完成时间就等于该集装箱所分配qc的装载结束时间。a)初始化。a.1设置i=1.a.2设置并且a.3设置b)计算工作π(1)(i)在ycπ(3)(i)上的完成时间。b.1计算ycπ(3)(i)的到达时间和完成时间。ayc[π(3)(i)]=ryc[π(3)(i)]+dpyc[π(3)(i)],b(π(1)(i))/sycb.2将ycπ(3)(i)的所在位置更新为b(π(1)(i)).pyc[π(3)(i)]=b(π(1)(i))c)计算工作π(1)(i)在ytπ(2)(i)上的结束时间。c.1计算ytπ(2)(i)的到达时间。ayt[π(2)(i)]=ryt[π(2)(i)]+dpyt[π(2)(i)],b(π(1)(i))/sytc.2对出口集装箱而言,当任务集装箱即工作π(1)(i)被放置于ytπ(2)(i)时,设备资源ycπ(3)(i)被释放,因此,ycπ(3)(i)在被释放后的处于可用状态的时间可计算为:ryc[π(3)(i)]=max{ayt[π(2)(i)],fyc[π(3)(i)]}然后,ytπ(2)(i)的完成时间可计算为:fyt[π(2)(i)]=ryc[π(3)(i)]+db(π(1)(i))qc(π(1)(i))/sytc.3则ytπ(2)(i)所处位置可更新为qc(π(1)(i)).pyt[π(2)(i)]=qc(π(1)(i))c.4对于出口集装箱而言,当任务集装箱π(1)(i)被所分配的qc从ytπ(2)(i)中转移走后,设备ytπ(2)(i)被释放处于待用状态,因此,设备ytπ(2)(i)的释放时间可计算为:ryt[π(2)(i)]=max{fyt[π(2)(i)],fqc[qc(π(1)(i))]}d)计算工作π(1)(i)在其所指定qc上的装载完成时间。cπ(1)(i)=fqc[qc(π(1)(i))]=ryt[π(2)(i)]+hqce)计算所有任务的总完工时间cmax。如果i=njob,则cmax=max{cπ(1)(i)|i=1,2,…,njob},否则,设置i=i+1,算法跳转到步骤1。4、新一代种群解的产生在提出的ga中,基于三维染色体,相应地设计了三对交叉算子和突变算子(crossover_1&mutation_1,crossover_2&mutation_2,crossover_3和mutation_3)广泛搜索解空间,从而提高算法的寻优能力。crossover_1和mutation_1应用于π(1),同时保持其yt和yc的分配不变。对π(2)上执行crossover_2和mutation_2,同时保持π(1)和π(3)不变。在π(3)上执行crossover_3和mutation_3,同时保持π(1)和π(2)不变。在每一次迭代中,以并行的方式执行三对交叉算子和突变算子以产生新一代的种群解。通过引入这种寻优机制,来改进ga的探索能力,并且降低错过具有优良属性解的可能性。交叉算子基于π(a)(a=1,2,3)的结构特征,分别针对性的开发了三种交叉算子。由于π(1)具有排列型结构,通过简单的交叉算子无法保证可行的后代,因此crossover_1使用顺序交叉算子(ordercrossover)以保证工作装载序列的可行性。对于π(2)和π(3),crossover_2和crossover_3采用简单的两点交叉算子(two-pointcrossover)。关于顺序交叉算子和两点交叉算子的具体过程可参照文献gen和cheng[18]。图3通过示例对π(1)执行crossover_1的过程给出了具体说明。基于父代染色体parent1,通过在两个选定的父代染色体parent1和parent2上执行crossover_1来生成子代染色体child1。在图3(a)中,随机选择父代染色体parent1中π(1)的子序列并将其复制到相应的child11中的位置。child1的其余空位由父代染色体parent2中π(1)剩余工作填写,而且保持这些工作在父代染色体parent2中的序列顺序。需要注意的,子代染色体child1继承了其父代染色体parent1中每个工作的yt和yc分配。例如,在父代染色体parent1中,yt1和yc2被分配给作业4。因此,子代染色体child1的作业4具有相同的分配,即yt1和yc2。同样,基于父代染色体parent2,通过在parent1和parent2上执行crossover_1,来生成子代染色体child2,如图3(b)所示。在执行crossover_1的过程中,更改π(1)中装载顺序的同时,保留了每项工作的yt和yc分配关系。图4显示了对于π(2),crossover_2的执行过程。以父代染色体parent1为基准,通过在两个选定的父代染色体parent1和parent2上执行crossover_2来产生子代染色体child1。在图4(a)中,随机地确定两个分割点:分割点cutpoint1和分割点cutpoint2。对于这两个分割点之间的任务集装箱,父代染色体parent1的yt分配π(2)被复制到子代染色体child1中。而对于子代染色体child1中其他集装箱的yt分配则与父代染色体parent2相同。子代染色体child1直接继承父代染色体parent1中的π(1)和π(3)。以相同的方式,以父代染色体parent2为基准,通过对父代染色体parent1和parent2执行crossover_2,产生子代染色体child2,如图4(b)所示。对于π(3),crossover_3使用两点交叉算子的过程与crossover_2相同,不同点是保持π(1)和π(2)不变。变异算子变异算子的使用使得ga有机会跳出当前搜索区域转到解空间的其他区域。这里为π(a)(a=1,2,3)设计了不同的变异算子。对于π(1),mutation_1是基于交换突变(swapmutation)[19]来实现的,它通过交换π(1)中两个随机选择的作业以及它们所指定的yt和yc分配来改变当前所选择的父代染色体。图5以一个小实例说明了mutation_1的执行过程。针对π(2)和π(3),分别设计了变异算子mutation_2和mutation_3,它们是一种新式的基于启发式的突变,在所提出的启发式变异算子中,基于所选择的父代染色体来生成邻域染色体,然后通过选择由此生成的所有邻域染色体中的最佳染色体来寻求改进。在mutation_2(或mutation_3)中,固定父代染色体的π(1)和π(3)(或π(1)和π(2)),通过将分配给作业π(1)(i)(i=1,2,…njob)的yt(或yc)逐个变换为其余的(nyt-1)yt(or(nyc-1)yc)中任何一个。则通过mutation_2来改变一个工作的yt分配,产生(nyt-1)个邻域解,同样,通过mutation_3来改变一个工作的yc分配,产生(nyc-1)个邻域解。因此,在mutation_2中共生成njob×(nyt-1)个邻域解,并且在mutation_3中共生成njob×(nyc-1)个邻域解。对每个邻域解进行评估,并选择其中具有最小完工时间的邻域解作为后代染色体。由于每一代的染色体质量对产生的下一代染色体有重要影响,因此设计的基于启发式的变异算子在此算法中起到了局部搜索的作用,通过在每一代染色体中搜索邻域解的方式找到更好的突变染色体,从而来提高种群染色体质量。选择算子在此算法中,使用确定性选择和轮盘赌选择在内的混合选择策略来选择后代染色体。将上一代群体解和所有生成的后代染色体按适应度值的大小进行降序排列。其中,部分新种群解通过确定性选择策略来形成,即选择具有不同适应度值且最佳的前k个染色体。此处,popsize表示ga中种群规模的大小,而剩余的(popsize-k)个染色体则使用最常用的轮盘赌选择规则来产生。基于初步实验,若仅使用确定性选择(即k=popsize),其缺点是只保留好的后代染色体,很可能舍弃了的较差个体中优良基因以及失去解的多样性,从而导致算法过早收敛。而另一方面,由于精英个体可能被交叉和变异算子破坏,而确定性选择迫使ga在每一代中保留前k个精英个体,而若仅使用轮盘赌选择,则可能丢失优质解。许多研究人员已经证实了精英染色体在改善遗传算法中的重要作用[20]。仅使用轮盘赌选择的另一个缺点是可能导致在下一代中选择许多类似或相同的染色体,而种群中存在太多相同染色体的现象是早熟收敛的另一个重要原因[18]。因此,利用这种混合选择策略有助于克服仅使用确定性选择或轮盘赌选择的缺点。终止条件算法中的终止条件是所允许的最大迭代数(max_gen),即达到max_gen时,ga终止,输出最终结果。5、算例分析为了评估所设计ga的性能,本文基于来已发表文献[12-13]中的数据生成了25个(e1-e25)问题算例。在此问题的港口布局中,有6台qc,在堆场中有20个存储区,随机产生每个作业所需要的qc和储位,yt和yc的初始位置也是随机生成的,此港口中yt和yc的移动速度分别为4m/s和3m/s,并假定qc和储位区的任何两个位置之间的距离是依据最短路径计算的。假定qc的平均处理时间为60秒,yc的平均处理时间为100秒。表6列出了25个算例问题中的工作,qc,yt和yc的数量关系。表625个问题算例的输入数据本算法使用c语言实现编程,mip模型通过ilogcplex9.0进行求解。所有算例在具有intercore2,3.30ghzcpu和4gbram的pc上进行了测试。ga的参数包括种群大小popsize,交叉概率pc,突变概率pm,每次迭代中所要选择的优良染色体的数目k和总迭代次数max_gen。基于初步实验,选择其中一组最佳参数集用于下面的算例实验,如表7所示。表7ga算法的参数设置为评估所提出ga的性能,对于每个算例问题,算法运行10次,将ga所获得的最优总完工时间和相应的cpu时间作为最终结果与mip所得结果进行比较分析。表8显示了mip与ga之间的比较结果。对于小型问题e1和e2,mip能够找到问题的最优解。由于其他算例问题无法在合理的计算时间内找到最优解,因此将cplex的运行时间限制为36小时,将在mip在36小时内获得的最优解作为其最终结果。从表8可以看出,即使对于小型问题,mip也难以找到最优解。而对于大型问题,mip在36小时内已无法找到可行的解方案。mip可以为其中7个算例问题找到最佳或可行的解方案。对于e3-e7,ga在几秒钟内找到的解方案要优于mip在36小时内找到的解方案,且计算了两者之间的差距值。表8中的结果表明mip无法在合理的时间段内解决中型或大型i_qcytyc,而所提出的ga可以有效地为i_qcytyc找到较好的解决方案。表8mip和ga算法所得实验结果对比“-”表示无法得到可行解。为了验证所提出的启发式变异算子的有效性,将具有启发式变异算子的ga(ga_hm)和具有一般变异算子的ga(ga_sm)所得的结果进行比较。在ga_sm中,通过在所选择的父代染色体中随机地选择某个作业并将其yt(或yc)随机地改变为不同的yt(或yc)。将相同的参数集用于ga_hm和ga_sm来解决25个算例问题,对每个问题将算法运行10次,将所得最佳结果进行比较。表4.14给出了ga_hm和ga_sm获得的最终结果及二者之间的差距值。从表9可以看出,ga_hm和ga_sm在短时间内为小型算例问题(e1-e8)找到相同质量的解方案。然而,随着问题规模的增加,两个结果的差距值从0.17%增长到36.32%。可见,ga_hm相对ga_sm可以找到更好的结果,特别是对于实际大型问题。但是,ga_hm需要更多的计算时间,这是因为随着问题规模的增加,在启发式变异算子中产生的邻域染色体的数量随之增大。对于三个规模最大的算例问题e23-e25,需要花费一个多小时的计算时间才能获得大约30%的改进。鉴于船舶到达港口前几个小时需要制定出详细的调度时间表,在实际情况下这样的计算时间仍然是合理的。表9算法ga_hm和ga_sm所得实验结果对比在图6中,以算例e25为例,可以看出ga_hm和ga_sm所获得的目标函数值随算法的迭代次数逐渐收敛,并且ga_hm和ga_sm均可以在1000代内达到收敛状态。尽管如此,可以明显看出ga_hm可以找到比ga_sm更好的解方案,这是因为启发式变异算子通过找到具有潜在良好基因模式的最佳邻域染色体来提高解方案的质量。总之,比较结果表明两种ga能够有效求解i_qcytyc,并且ga_hm相比ga_sm能够找到更好的解方案,尤其对于大规模实际问题。由于只优化一种装卸设备可能无法保证系统的全局最优解,因此提出了港口多资源设备qc,yt和yc的集成调度问题。为此集成问题,提出了一种mip模型,由于大量的变量和约束条件,mip模型难以处理大型实际问题。为此,开发了一种遗传算法,该算法结合了所提出的一般化算法框架。在ga中,设计了三维染色体,其将三个子问题相互关联起来。基于染色体的结构特征,引入了三对交叉算子和变异算子,每对交叉和变异算子只针对其中一个子问题。ga中的这种机制很好地匹配了集成问题的属性。此外,为了提高所提出的遗传算法的效率,设计了一种新的启发式变异算子。通过并行地应用三对交叉算子和变异算子,可以找到更好的解决方案。通过计算结果显示了所提出的算法能够较好地解决港口集成调度问题。参考文献:1.chen,l.,bostel,n.,dejax,p.,cai,j.andxi,l.,atabusearchalgorithmfortheintegratedschedulingproblemofcontainerhandlingsystemsinamaritimeterminal.europeanjournalofoperationalresearch,2007.181(1):pp.40-58.2.steenken,d.,voβ,s.andstahlbock,r.,containerterminaloperationandoperationsresearch-aclassificationandliteraturereview.orspectrum,2004.26:pp.3-49.3.lee,d.h.,wang,h.q.andmiao,l.,quaycraneschedulingwithnon-interferenceconstraintsinportcontainerterminals.transportationresearchparte:logisticsandtransportationreview,2008.44(1):pp.124-135.4.tacakkoli-moghaddam,r.,makui,a.,salahi,s.,bazzazi,m.andtaheri,f.,anefficientalgorithmforsolvinganewmathematicalmodelforaquaycraneschedulingproblemincontainerports.computers&industrialengineering,2009.56(1):pp.241-248.5.meisel,f.andbierwirth,c.,aunifiedapproachfortheevaluationofquaycraneschedulingmodelsandalgorithms.computers&operationsresearch,2011.38:pp.683-693.6.bish,e.k.,chen,f.y.,leong,y.t.,nelson,b.l.,ng,j.w.c.andsimchi-levi,d.,dispatchingvehiclesinamegacontainerterminal.orspectrum,2005.27:pp.491-506.7.ng,w.c.,mak,k.l.andzhang,y.x.,schedulingtrucksincontainerterminalsusingageneticalgorithm.engineeringoptimization,2007.39(1):pp.33-47.8.ng,w.c.andmak,k.l.,yardcraneschedulinginportcontainerterminals.appliedmathematicalmodeling,2005.29:pp.263-276.9.jung,s.h.andkim,k.h.,loadingschedulingformultiplequaycranesinportcontainerterminals.journalofintelligentmanufacturing,2006.17:pp.479-492.10.he,j.,chang,d.,mi,w.andyan,w.,ahybridparallelgeneticalgorithmforyardcranescheduling.transportationresearchparte:logisticsandtransportationreview,2010.46(1):pp.136-155.11.bierwirth,c.andmeisel,f.,asurveyofberthallocationandquaycraneschedulingproblemsincontainerterminals.europeanjournalofoperationalresearch,2010.202:pp.615-627.12.cao,j.x.,lee,d-h.,chen,j.h.andshi,q.,theintegratedyardtruckandyardcraneschedulingproblem:benders’decomposition-basedmethods.transportationresearchparte:logisticsandtransportationreview,2010.46(3):pp.344-353.13.lau,h.y.k.andzhao,y.,integratedschedulingofhandlingequipmentatautomatedcontainerterminals.annalsofoperationsresearch,2008.159:pp.373-394.14.zeng,q.andyang,z.,integratingsimulationandoptimizationtoscheduleloadingoperationsincontainerterminals.computers&operationsresearch,2009.36:pp.1935-1944.15.linn,r.,liu,j.,wan,y.,zhang,c.andmurtyk.g.,rubbertiredgantrycranedeploymentforcontaineryardoperation.computers&industrialengineering,2003.45:pp.429-442.16.murty,k.g.,liu,j.,wan,y.andlinn,r.,adecisionsupportsystemforoperationsinacontainerterminal.decisionsupportsystems,2005.39:pp.309-332.17.zhang,c.,wan,y.,liu,j.andlinn,r.,dynamiccranedeploymentincontainerstorageyards.transportationresearchpartb,2002.36:pp.537-555.18.gen,m.andcheng,r.,geneticalgorithmsandengineeringoptimization.1999:newyork,wiley.19.goldberg,d.e.,geneticalgorithmsinsearch,optimizationandmachinelearning.1989:boston,ma,addisonwesleylongman.20.mitchell,m.,anintroductiontogeneticalgorithms.1999:cambridge,ma,mitpress.当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1