一种基于结构化表达的电力运维文本分析方法与流程
本发明属于自然语言处理技术领域,具体涉及一种基于结构化表达的电力运维文本分析方法。
背景技术:
在当前信息化人工智能时代,基础性公用事业企业也将面临向管理智能化的模式升级。随着互联网信息化数据爆炸式的增长,着眼未来城市电网科学发展,电力大数据分析将是智能电网中的核心一环。其中,海量的互联网新闻媒体、社交评论充分的反映了社会热点话题,电网内部每天产生的大量的日志信息也蕴含了巨大的潜在价值,目前处理分析这些日志存在以下缺点:
1、由于互联网文本及日志信息来源广泛,从语义结构和书写格式上存在较多差异,例如:互联网新闻媒体资讯等长文本文档、社交评论和运维检修日志等不同类型的短文本文档,因此冗杂的非/半结构化文本信息难以从中挖掘有效信息,从而发现事件影响因素的关联。
2、日志文档多由手工录入和语音转化记录得到,同时海量互联网文本信息主要是由个人用户发表。此类语料在语言校对方面不够严谨,存在一定量的错别字、语法错误问题,同时词语中口语化词素或常用语较多。如何对此类文本实现数字化表达,设计专用的词向量表示模型是整个自然语言处理工作中的头部环节,良好词向量表示模型将能在多类任务性能中表现出显著的效果。
3、处理此类企业级电力相关文档,数据量巨大,由于分析结果直接影响基础性公用建设,真实可靠是首要要求。在数据处理环节中,由于业务文本存在着较多专业化词语或短语,仅依靠技术手段完成特征关键词提取、分类等往往是不够的,还需依靠人工分析构建并更新相关的本体字典,标记训练和验证用样本。从而确保技术方法的准确可靠,确保对于文本事件语义挖掘对事件关联所作出的响应式准备无误的。
4、在电力运检方面,往往涉及故障排查和抢险等问题,而事件的发生是多因素影响的。需要深度挖掘单因素特性和多因素关联进行综合判断,才能准确对事件预控做出判断,实现及时避免事故发生或快速响应。
针对上述问题目前采用的技术有:1、中文词向量表示技术,大多数不是针对汉字这种结构字体去设计的,主要是通过西文拉丁文这种文字的表达而用于中文词领域。但是中文词包含很少的字符信息,却具有很强的语义信息,包括汉字本身和词语结构特点,这类西文拉丁词表示方法难以充分挖掘中文文本的语义信息。2、在依据词向量构造中文文本结构化表达形式中,需要在海量语料中提取不同属性类别的关键词。而现有的基于统计学模型的方法需要构造完备的人工规则和本体字典,这种限制性只能应用于特定领域,无法构造通用模型同时也难以对规则和字典更新维护。3、一些无监督模型在上下文语义理解、运算量和人工标记成本等方面均存在一定的不足。4、目前针对事件关联分析,主要采用特定性建模和聚类的方法。其中,特定性建模过于依赖人工规则和场景的专业性,面向海量互联网数据时会出现大量不在本体语料中的文本,难以在线更新规则,则无法进行关联分析。而聚类关联方法时能够通过无监督训练,寻找无规则匹配的关键特征之间的关系,这种关系在自然语言处理领域通常使用相似性函数,用于获取两个关键词之前的语义关联度确定其间的相似程度,这种方法在很大程度上取决于中文词向量表示模型的设计,包含更深丰富语义信息的表达即会获得更优层次的分类结果。
技术实现要素:
本发明的目的主要针对现有结构化表达多维事件关联技术中的不足之处,提出了一种基于结构化表达的电力运维文本分析方法,该方法可对庞大且冗杂的企业级文本数据资产实现对其进行统一管理,通过数据分析并高效获取相关设备网点运营状况,发现潜在的危险和隐患,在第一时间能够对异常事件做出响应。
如上构思,本发明的技术方案是:一种基于结构化表达的电力运维文本分析方法,其特征在于:包括如下步骤:
①通过采集电力运维日志并加入维基百科的开源中文语料库构建电力运维语料数据库,同时对所构建的语料数据库进行预处理;
②基于所构建的电力运维语料库,针对这种中文记录文档特征设计基于拼音统计的词向量,引入了语素拼音的词频作为统计权重,即对拼音表示在训练集语料和全文档中统计词频和逆文档概率tfp和idfp,其中
③采用cbow模型网络架构生成中文词表示向量,对于给定长度语句s=[x1,x2,...,xk],其中xk为第k个语素,通过一个固定大小(2m+1)窗口内的上下文语素来预测目标中心词xi,获取中心语素的前m个和后m个语素{xi-m,...,xi-1,xi+1,...,xi+m}的局部拼音表示组
所述cbow网络架构是包含输入层、输出层和一个隐含层的神经网络;
④采用基于bi-lstm字符级提取方法识别实体关键词,其方法流程为:首先对拼字输入26个拼音字符通过ont-hot随机编码为26维字向量构造一个查找表,对语素拼音的每个字符分别参照查找表表示为初始化字向量,然后以tw大小滑窗通过一个卷积层和一个最大池化层,构造每个字符对应的tc维字向量cx,然后融合每个语素的词向量和字向量特征,即生成(t+tc)维的拼音特征向量vx,将词特征向量作为输入放入bi-lstm网络模型,其中前向lstm的输入序列是文本中以语素为单元的顺序序列,后向lstm的输入是其逆序序列;通过bi-lstm网络,在t时刻前向lstm输出矩阵为
⑤对于所提取的实体关键词,构建多维特征语义槽结构,该结构由七个语义槽构成,分别为:f={c,n,d,t,a,r,e,p},c为作业单位,n为姓名,d为日期,t为时间,a为事故发生原因,r为故障线路,e为故障设备,p为事故发生地点;具体方法是:首先对电力运维日志历史记录进行处理,设计运维文本的文法表达结构并通过实体关键词提取来构造不同词类的本体字典,同时获得本体字典中的全部词语的词向量表示wij,其中本体字典包含i个词类,每个此类包含j个词语,对同一词类的全部词向量取平均值获得
语义槽填充包括关键词提取和正则匹配,对外部语料提取实体关键词与字典词进行匹配,匹配成功则根据词类填入语义槽中,若所提取关键词未与字典完全匹配,则对比该关键词与各个词类间的语义相似度,即
中间语义槽经过词串合并,最终能够对非/半结构化文本重组为多维特征语义槽结构的文法表达结构,同时获得到的语素或词串也可以用与扩充本地字典;
⑥提取影响事故发生的多类特征的类内和类间的关系;每一词类及一个事故影响因素,对于类内特征的分析采用统计词频特征tf-idf,对类内全部词语统计tf-idf,由高到底进行排序,即获得同一影响因素下最可能发生事故的特征;同时,对于同一类影响因素下的多个特征间存在的联系提取方法为:两个不同特征wi和wj属于同一词类,其间语义相似度函数为sim(wi,wj)=wi·wj,对于类内的全部词语,依次获得两个词向量余弦距离最相邻的词语构成一组因素串,即为所获得的同类别事故影响因素的关联结果;
对于不同类间影响因素的关联,在词频维度上,wi和wk是任意两个不同词类的特征,认为其同时出现在同一文本中是不同因素的高发强关联特征,因此设计两个特征间词频距离为,
其中ti是在全语料中每个文本包含wi的tf-idf词频的统计量,采用k-means聚类将dik作为距离函数在类间统计多类影响因素同时造成事故发生的情况。
上述步骤②设计基于拼音统计的词向量的方法是:以不同长度n(n可取3、4、5...)的窗口大小在一个语素的拼音表示上滑动,构成局部拼音表示组px;;遍历全语料即获得全部中文语素所共享的局部拼音表示字典s,其中s(x)表示语素x的局部拼音表示组px。
上述神经网络的输入网络的2m个拼音词向量组乘上输入权重矩阵wt×n得到
上述目标中心词xi的损失函数为,
最后采用梯度下降法来求解目标函数,即只需对上述一个样本的损失梯度求解,获得更新表达式为:
输入权重矩阵,
输出权重矩阵,
上述每个lstm块结构包含输入、遗忘和输出三个乘法门,遗忘门更新函数为:ft=sigmoid(wfvt+ufht-1+bf),在决定细胞状态更新时,先将对输入门确定更新的值通过tanh函数获得新的候选状态向量:it=sigmoid(wivt+uiht-1+bi),c't=tanh(wcvt+ucht-1+bc),c't为细胞t时刻的候选状态,因此即获得细胞更新状态公式为:ct=ftct-1+itc't。细胞状态更新后,输出门通过sigmoid函数计算将要输出的信息后通过tanh激活,即获得输出结果:ot=sigmoid(wovt+uoht-1+bo),ht=ot·tanh(ct),其中wf、wi、wc和wo为输入信息的权值参数,uf、ui、uc和uo为循环权值参数,bf、bi、bc和bo为偏置。
本发明具有如下的优点和积极效果:
1、本发明通过对互联网通用语料、电力运维日志等信息语料构造运维语料库,针对语言结构特征设计了py2vec词向量表示方法,生成的词向量包含了丰富中文语义信息。
2、为了对海量语料进行结构化表达分析,本发明中提出了构建多维特征语义槽结构的文法表达框架,多维关键词特征的提取采用基于bi-lstm字符级实体词分类技术,根据本方法所构建的多维本体字典和结构化表达框架,能够对语料库外部进行正文(关键词)提取。
3、本发明设计了基于词频和词向量关系的聚类方法分别针对多维特征类内和类间关联进行统计分析,提供了一种对事件风险评估、事件预警进行针对性指示的文本分析方法。
附图说明:
图1为本发明方法的主要框架图。
图2为本发明方法的中文词向量表示模型框架图。
图3为本发明方法的关键词提取与分类模型框架图。
图4为lstm块结构示意图。
图5为本发明方法的语料结构化处理设计流程图。
图6为本发明方法的多维特征类内及类间分析流程图。
具体实施方式:
为了使本发明的目的、技术方案和优点更加清楚,下面将结合本发明的具体实施方案和附图做进一步详细描述。实施例如下:由平安供电公司大安抢修班,张三赶赴现场进行故障抢修,经查19点45分由于台区内用户漏电原因导致下城123干线、4号杆、大华公用变压器停电(保安器跳闸),造成平安村没电,于9月28日20点15分抢修完毕,恢复供电,用户认可。处理人:张三。另显然,所描述实施例仅是本发明的部分实施例,而不是全部的应用场景。
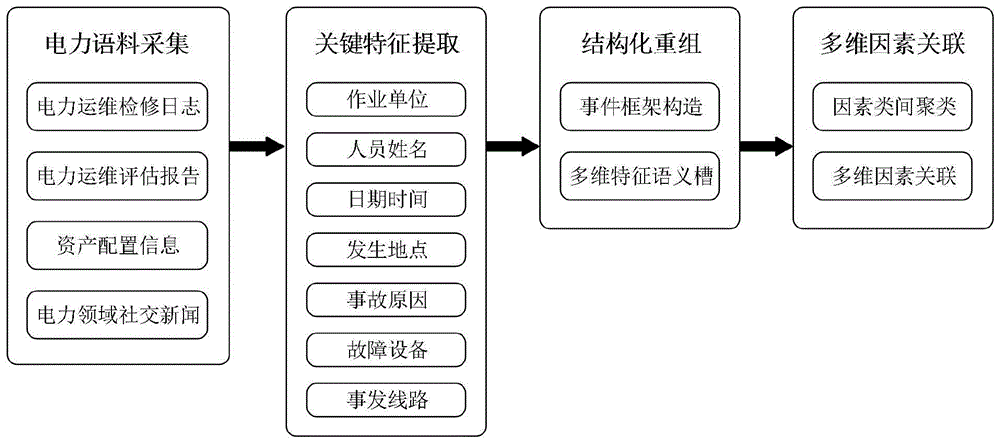
本发明提供了一种基于结构化表达的电力运维文本分析方法,其整体架构如图1所示,该方法具体包括:
1.对于结构化表达的电力运维文本分析方法的设计,需要专业语料库支持,语料来源主要采集于互联网电力行业信息官网的新闻媒体资讯、社交媒体平台的博客与评论以及电力某公司的运维检修日志文档。此外由于对语料分析泛化能力的要求,还加入了维基百科的开源中文语料库。其中维基百科中文数据集包含1.13亿个中文词语,排重后词典大小为28.9万;电力新闻语料包含94.19万个中文词语,排重后词典大小为3.14万;电力运维日志语料包含286.50万个中文词语,排重后词典大小为5.80万。
对构造的语料库数据首先基于正则表示进行正文提取,后使用openncc将文本中繁体词转换为简体中文,本方法中使用结巴分词根据统计的1893个停用词对语料进行分词操作,并完成初步的词性标注,其示例结果如下表。
2.对于所构造的电力运维语料库,针对这种中文记录文档特征设计了基于拼音统计的词向量表示方法,其模型框架图如图2所示。以不同长度n(n可取3、4、5...)的窗口大小在一个语素的拼音表示上滑动,构成局部拼音表示组px。遍历全语料即获得全部中文语素所共享的局部拼音表示字典s,其中s(x)表示语素x的局部拼音表示组px。此外由于在自然语言处理领域,词频和词向量均是重要的语言特征,本方法中引入了语素拼音的词频作为统计权重,即对拼音表示在训练集语料和全文档中统计词频和逆文档概率tfp和idfp,其中
在生成中文词表示向量时,本方法采用cbow模型网络架构,对于给定长度语句s=[x1,x2,...,xk],其中xk为第k个语素。通过一个固定大小(2m+1)窗口内的上下文语素来预测中心目标词,其中m=2,获取中心语素的前m个和后m个语素{xi-m,...,xi-1,xi+1,...,xi+m}的局部拼音表示组
在本方法中对于中文词向量设计采用cbow网络架构,仅包含输入层、输出层和一个隐含层的神经网络。输入网络的2m个拼音词向量组乘上输入权重矩阵wt×n得到
本方法定义目标中心词xi的损失函数为,
最后采用梯度下降法来求解目标函数,即只需对上述一个样本的损失梯度求解,获得更新表达式为:
输入权重矩阵,
输出权重矩阵,
3.对于实体关键词识别采用基于bi-lstm字符级提取方法,其方法流程如图4所示。首先对拼字输入26个拼音字符(韵母“ü”在拼音输入中表示为字母“v”)通过ont-hot随机编码为26维字向量构造一个查找表。对语素拼音的每个字符分别参照查找表表示为初始化字向量,然后以tw大小滑窗,通过一个卷积层和一个最大池化层,构造每个字符对应的tc维字向量cx。然后融合每个语素的词向量和字向量特征,即生成(t+tc)维的拼音特征向量vx,将词特征向量作为输入放入bi-lstm网络模型,其中前向lstm的输入序列是文本中以语素为单元的顺序序列,后向lstm的输入是其逆序序列。每个lstm块记录细胞状态参数并在链上传输,每个块结构包含输入、遗忘和输出三个乘法门,其示意图如图4所示,遗忘门决定细胞状态中丢失信息的程度,其更新函数为:ft=sigmoid(wfvt+ufht-1+bf),在决定细胞状态更新时,先将输入门确定更新的值通过tanh函数获得新的候选状态向量:it=sigmoid(wivt+uiht-1+bi),c't=tanh(wcvt+ucht-1+bc),c't为细胞t时刻的候选状态,因此即获得细胞更新状态公式为:ct=ftct-1+itc't。细胞状态更新后,输出门通过sigmoid函数计算将要输出的信息后通过tanh激活,即获得输出结果:ot=sigmoid(wovt+uoht-1+bo),ht=ot·tanh(ct),其中wf、wi、wc和wo为输入信息的权值参数,uf、ui、uc和uo为循环权值参数,bf、bi、bc和bo为偏置。
通过bi-lstm网络,在t时刻前向lstm输出矩阵为
4.对于所提取的实体关键词,构建多维特征语义槽结构。本方法中一个完整表达框架由七个语义槽构成,分别为:f={c,n,d,t,a,r,e,p},c为作业单位,n为姓名,d为日期,t为时间,a为事故发生原因,r为故障线路,e为故障设备,p为事故发生地点,见下表:
首先对电力某公司的运维日志历史记录进行处理,设计运维文本的文法表达结构(如:大安区抢修队张三于9月28日19点45分,因用户漏电造成保安器跳闸,导致123干线4号杆大华变压器停电,事故发生地点平安村)并通过实体关键词提取来构造不同词类的本体字典(如设备类:低压出线电杆断杆故障、总保跳闸故障、开关跳闸、单相令克烧掉故障等),同时获得本体字典中的全部词语的词向量表示wij,其中本体字典包含i个词类,每个此类包含j个词语,对同一词类的全部词向量取平均值获得
语义槽填充包括关键词提取和正则匹配,具体流程如图5所示。对外部语料提取实体关键词与字典词进行匹配,匹配成功则根据词类填入语义槽中。若所提取关键词未与字典完全匹配,则对比该关键词与各个词类间的语义相似度,即
中间语义槽经过词串合并,最终能够对非/半结构化文本重组为多维特征语义槽结构的文法表达结构,同时获得到的语素或词串也可以用与扩充本地字典。词串合并的规则即为:c抢修队n于d(月、日)t(时、分),因a造成e,导致r,事故发生地点p)。
5.对于结构化表达的运维日志语料,能够更直接的提取影响事故发生多类特征的类内和类间的关系,具体分析方法如图6所示。每一词类及一个事故影响因素,对于类内特征的分析采用统计词频特征tf-idf,对类内全部词语统计tf-idf,由高到底进行排序,即获得同一影响因素下最可能发生事故的特征。同时,本方法中认为对于同一类影响因素下的多个特征间在一定程度上存在某种联系,两个不同特征wi和wj属于同一词类,其间语义相似度函数为sim(wi,wj)=wi·wj,对于类内的全部词语,依次获得两个词向量余弦距离最相邻的词语构成一组因素串,即为所获得的同类别事故影响因素的关联结果。
对于不同类间影响因素的关联,在词频维度上,wi和wk是任意两个不同词类的特征,认为其同时出现在同一文本中是不同因素的高发强关联特征,因此设计两个特征间词频距离为,
本发明是针对电力运维语料的记录特点设计的专用的词向量表示方法,对海量复杂的语料以多种神经网络结构提取实体关键词构造字典词库作为目标特征。此外本方法中还提出了一种对于非/半结构化文本结构化处理的语义槽模型,能够能直观的统计和分析影响事故发生的多维因素内部和之间的语义关联性,并设计了基于语言的词频和词向量两个重要方法的多个维度的类内和类间统计关联,能够有效地进行事件预警并提供针对性运检指示方法。
以上所述为本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所包含的额内容,仍应属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!