一种知识图谱体系搭建方法与流程
本发明涉及一种知识图谱体系搭建方法,属于跨模态知识图谱构建和数据存储管理利用技术领域,具体涉及一种跨模态知识图谱构建和多模态数据管理。
背景技术:
知识图谱能把复杂的知识领域通过数据挖掘、信息处理、知识计量和图形绘制而显示出来,揭示知识领域的动态发展规律,为学科研究提供切实的、有价值的参考。
目前知识图谱的构建和数据管理工作都是基于单一数据格式进行分析,对于语音、视频、文本、图像等多模态数据的利用率和管理存储方式的研究存在明显不足。由于互联网技术和信息技术的高速发展,数据以一种多元化多模态的方式呈现出来,如何利用这些多模态的数据构建更加完善的知识图谱并进行多模态数据的合理管理利用,具有非常高的研究意义。
随着计算机技术的不断发展,深度学习在多模态数据处理领域取得了非常显著的成果。在数据存储方面,从关系型数据库、分布式数据库再到基于键值对的nosql(notonlysql)数据库,逐步实现了多模态多格式数据的有效存储和管理。
因此通过结合传统逻辑规则、统计学习、深度学习技术,以及键值对存储方式,通过跨模态数据分析的方式构建统一的跨模态知识图谱,并将知识图谱和底层多模态数据关联起来,对获得更高质量的知识图谱、提升知识图谱效果、提升数据利用率、推进计算机技术发展等具有重要意义。
技术实现要素:
为解决上述技术问题,本发明提供了一种知识图谱体系搭建方法,该知识图谱体系搭建方法通过输入多种格式的多模态数据,输出拓展后的多模态数据、多模态数据存储方式、知识图谱和多模态数据关联,构建统一表示的知识图谱,并实现多模态数据快速拆解和定位检索算法。
本发明通过以下技术方案得以实现。
本发明提供的一种知识图谱体系搭建方法,包括以下步骤:
①数据采集:通过接口、爬虫获取多模态数据;
②提取特征:提取多模态数据的特征;
③表征特征:将提取的特征进行统一表示、关联分析、共性选择和粗分类,获取表征特征;
④特征保存:搭建数据库,将表征特征存入数据库中;
⑤获取知识图谱基础:从多模态数据中抽取实体、属性和关联关系,并以各个粗分类类别为基准,获取构建知识图谱的基础;
⑥构建知识图谱:根据知识图谱基础,构建跨模态数据的统一表征的知识图谱。
所述步骤①分为以下步骤:
(1.1)通过接口、爬虫获取目标领域相关的多模态数据,包括常规数值数据、文本数据、图像数据、视频数据、语音数据;
(1.2)对获取的多模态数据进行初步的数据清洗、数据处理,并按照数据格式选择合理的方式进行分类储存。
所述步骤②分为以下步骤:
(2.1)通过大规模数据,结合统计学习、逻辑规则方法,进行多模态数据特征提取的训练,获取深度学习神经网络模型,分别为图像特征提取神经网络模型、视频特征提取神经网络模型、语音特征提取神经网络模型、文本特征提取神经网络模型;
(2.2)通过统计方法获得用于提取多模态数据的特征算法模型;
(2.3)根据步骤(2.1)~(2.2)中的模型,分别提取常规数值数据、文本数据、图像数据、视频数据、语音数据的特征;
(2.4)将提取的特征作为对应数据,进行表示。
所述步骤(2.1)中,通过图像特征提取神经网络模型获取图像数据特征,通过视频特征提取神经网络模型获取视频数据特征,通过语音特征提取神经网络模型获取语音数据特征,通过文本特征提取神经网络模型获取文本数据特征,通过逻辑规则获取常规数值数据特征。
所述步骤③分为以下步骤:
(3.1)将提取到的多模态数据的特征利用深度学习技术进行统一表示;
(3.2)利用聚类算法、关联算法、距离算法对表示的各个数据的特征进行分析、分类;
(3.3)从分类中获取各个类别的多模态混合数据特征,并通过统计学习方法、逻辑规则、深度学习方法获取可以粗糙表示的各个类别的共性特征,即表征特征。
所述步骤④分为以下步骤:
(4.1)搭建基于nosql的数据库;
(4.2)通过多模态数据的特征算法模型,获取各个类别的表征特征作为索引key,类别包含的多模态数据作为对应的值value,存入数据库中。
所述步骤⑤分为以下步骤:
(5.1)通过统计学习方法、逻辑规则方法、深度学习方法,分别对各个类别中的图像数据、语音数据、文本数据、视频数据进行常规实体抽取、属性抽取、关系抽取分析,获取实体、属性和关联关系;
(5.2)以各个粗分类类别为基准,分别对属于各个类别实体、属性、关联关系进行跨模态的关联分析、交叉验证,去除错误信息,获取置信度高的实体、属性、关联关系信息,作为构建知识图谱的基础。
所述步骤⑥分为以下步骤:
(6.1)根据置信度高的实体、属性和关联关系,构建知识图谱,并对知识图谱进行统一表征;
(6.2)对构建的知识图谱进行知识推理研究,建立实体间隐藏的关系图,得到拓展后的知识图谱。
还包括步骤⑦数据拆解定位算法:通过知识图谱和多模态数据的关联,实现数据拆解定位算法;
具体分为以下步骤:
(7.1)通过建立实体、属性和数据特征、表征特征、索引key之间的关系,将知识图谱和nosql数据库中的多模态数据关联进行关联;
(7.2)根据数据特有格式、结合逻辑规则和统计学习、深度学习方法,实现基于数据格式的数据拆解算法,以及数据的快速定位检索算法;
(7.3)结合数据拆解定位算法以及知识图谱和多模态数据的关联关系,建立统一表征知识图谱和底层多模态数据的强关联关系。
本发明的有益效果在于:能够将多媒体数据关联起来构建知识图谱、进行多媒体数据统一管理和使用、解决训练数据不足的问题、提升知识图谱关键信息抽取准确度、提升知识图谱构建效率,并通过实体属性特征关联以及键值对存储的方式,将知识图谱和底层多模态数据关联起来,利用数据拆解定位算法进行快速检索,再通过闭环式的体系,实现整个体系的快速迭代进化和完善,从而为后期的各项应用提供有力的支撑。
附图说明
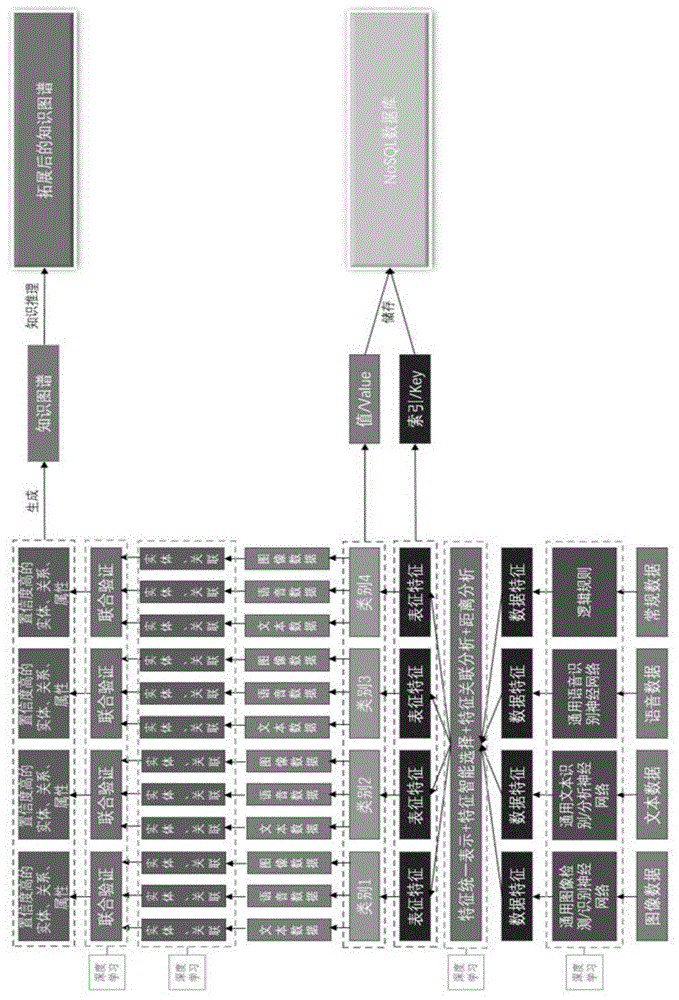
图1是本发明的结构图。
具体实施方式
下面进一步描述本发明的技术方案,但要求保护的范围并不局限于所述。
如图1所示,一种知识图谱体系搭建方法,包括以下步骤:
①数据采集:通过接口、爬虫获取多模态数据;
具体分为以下步骤:
(1.1)通过接口、爬虫获取目标领域相关的多模态数据,包括常规数值数据、文本数据、图像数据、视频数据、语音数据;
(1.2)对获取的多模态数据进行初步的数据清洗、数据处理,并按照数据格式选择合理的方式进行分类储存。
②提取特征:提取多模态数据的特征;
具体分为以下步骤:
(2.1)通过大规模数据,结合统计学习、逻辑规则方法,进行多模态数据特征提取的训练,获取深度学习神经网络模型,分别为图像特征提取神经网络模型、视频特征提取神经网络模型、语音特征提取神经网络模型、文本特征提取神经网络模型;
优选的,选用通用数据、通用神经网络进行特征提取,可以解决训练数量不足的问题;
进一步地,通过图像特征提取神经网络模型获取图像数据特征,通过视频特征提取神经网络模型获取视频数据特征,通过语音特征提取神经网络模型获取语音数据特征,通过文本特征提取神经网络模型获取文本数据特征,通过逻辑规则获取常规数值数据特征。
(2.2)通过统计方法获得用于提取多模态数据的特征算法模型;
(2.3)根据步骤(2.1)~(2.2)中的模型,分别提取常规数值数据、文本数据、图像数据、视频数据、语音数据的特征;
(2.4)将提取的特征作为对应数据,进行表示。
③表征特征:将提取的特征进行统一表示、关联分析、共性选择和粗分类,获取表征特征;
具体分为以下步骤:
(3.1)将提取到的多模态数据的特征利用深度学习技术进行统一表示;
(3.2)利用聚类算法、关联算法、距离算法对表示的各个数据的特征进行分析、分类;
优选的,通过特征统一表示、特征选择、特征关联分析、共性特征选择和特征表征的方式,将多模态数据关联起来,并进行分类;
优选的,通过对多模态数据进行特征表征以及分类,实现以通用表征特征对包含多模态数据(比如图像、语音、视频、文本数据等)各个类别数据进行分类管理;
(3.3)从分类中获取各个类别的多模态混合数据特征,并通过统计学习方法、逻辑规则、深度学习方法获取可以粗糙表示的各个类别的共性特征,即表征特征。
④特征保存:搭建数据库,将表征特征存入数据库中;
具体分为以下步骤:
(4.1)搭建基于nosql的数据库,使用nosql(notonlysql)数据库进行多模态数据的存储和管理;利用nosql基于对键值的存储方式,可以对多模态数据进行合理存储;
优选的,多模态数据的管理是利用数据特征作为数据标签、利用表征特征作为类别标签进行标记和管理;
(4.2)通过多模态数据的特征算法模型,获取各个类别的表征特征作为索引key,类别包含的多模态数据(比如图像、文本、语音等格式的数据)作为对应的值value,存入数据库中;利用算法生成的特征信息作为索引,用分类之后的数据作为值,可以有效管理和使用数据。
⑤获取知识图谱基础:从多模态数据中抽取实体、属性和关联关系,并以各个粗分类类别为基准,获取构建知识图谱的基础;
具体分为以下步骤:
(5.1)通过统计学习方法、逻辑规则方法、深度学习方法,分别对各个类别中的图像数据、语音数据、文本数据、视频数据进行常规实体抽取、属性抽取、关系抽取分析,获取实体、属性和关联关系,可以有效降低构建知识图谱的工作量;即对同一类别不同数据使用常规统计学习方法、逻辑规则方法、深度学习方法提取知识图谱实体、属性和关联关系信息,并进行信息之间的关联分析以及交叉验证,并对跨类别的信息进行交叉关联分析获取新的实体、属性和关联关系;
(5.2)以各个粗分类类别为基准,分别对属于各个类别实体、属性、关联关系进行跨模态的关联分析、交叉验证,去除错误信息,获取置信度高的实体、属性、关联关系信息,作为构建知识图谱的基础,可以提升知识图谱核心元素的可信度。
⑥构建知识图谱:根据知识图谱基础,构建跨模态数据的统一表征的知识图谱,可以大幅度提升数据的逻辑性;
具体分为以下步骤:
(6.1)根据置信度高的实体、属性和关联关系,构建知识图谱,采用常规的表示方法,对知识图谱进行统一表征;
(6.2)基于常规知识图谱构建技术,对构建的知识图谱进行知识推理研究,建立实体间隐藏的关系图,得到拓展后的知识图谱。
还包括步骤⑦数据拆解定位算法:通过知识图谱和多模态数据的关联,实现数据拆解定位算法;即通过利用数据特有格式、结合逻辑规则统计学习深度学习技术,实现基于数据格式的数据拆解算法以及数据的快速定位检索算法;
具体分为以下步骤:
(7.1)通过建立实体、属性和数据特征、表征特征、索引key之间的关系,将知识图谱和nosql数据库中的多模态数据关联进行关联;
(7.2)根据数据特有格式、结合逻辑规则和统计学习、深度学习方法,实现基于数据格式的数据拆解算法,以及数据的快速定位检索算法;
(7.3)结合数据拆解定位算法以及知识图谱和多模态数据的关联关系,建立统一表征知识图谱和底层多模态数据的强关联关系;
进一步地,通过统一表示的知识图谱将多模态数据(图像、文本、语音、视频等数据)关联起来,并通过实体、属性、数据特征、表征特征、数据格式、定位检索、键值对存储的方式建立知识图谱和底层数据的强关联关系;
本发明是一种基于nosql数据库的多模态数据融合统一知识图谱体系搭建方法,通过获取图像、视频、音频等多种格式的混合数据;利用大规模通用数据分别训练通用图像、文本、音频、视频数据特征提取神经网络,然后分别对图像、文本、音频、视频数据进行特征抽取、特征统一表征、特征关联分析和共性特征选择,建立多模态数据弱关联关系,利用共性特征进行多模态数据分类,并将共性特征作为类别的表征特征以及索引(key)、表征特征对应的多模态数据作为值(value)存入nosql(notonlysql)数据库中;从各个类别中分别对图像数据、音频数据、文本数据等多模态数据利用逻辑规则、统计学习方法、深度学习方法提取知识图谱实体、属性和关联关系,然后对属于同一类别的不同格式数据提取到的知识图谱实体、属性和关联关系进行交叉再验证,选出置信度较高的实体、属性、关联关系构建统一表示的知识图谱。
实施例
如上所述,本发明的实施过程如下:
1)获取图像、语音、视频、文本等多模态数据,进行数据初步清洗和处理;
2)训练多模态数据特征提取的神经网络算法模型、建立逻辑规则算法模型;
3)分别对各个格式的多模态数据进行特征抽取;
4)对得到的特征进行统一表示、特征关联分析、特征选择、共性特征选择和数据表征特征的确定,并依据特征分析结果对多模态数据进行初步分类;
5)将表征特征作为索引(key),对应类别的多模态混合数据作为值(value)存入nosql数据库中;
6)利用逻辑规则方法、统计学习方法和深度学习方法,分别对每个类别中的多模态数据进行实体抽取、属性抽取和关联关系抽取,获取实体、属性和关联关系信息;
7)对从多模态数据中获得的实体、属性和关联关系进行关联分析、交叉验证,获取置信度较高的信息,去掉错误提取的信息或者本身存在错误的信息;
8)基于常规知识图谱构建和统一表示方法,利用置信度较高的实体、属性和关联关系信息搭建多模态数据的统一表示的知识图谱;
9)利用知识推理技术,从已获得的知识图谱中进行知识推理,建立更深层次的实体属性信息以及关联关系,得到拓展后的知识图谱;
10)通过数据特征、表征特征、键值对建立知识图谱和底层数据的对应关系;
11)通过实现基于数据格式的数据拆解和快速检索定位算法,建立知识图谱和底层数据的强关联关系。
综上所述,本发明是一套闭环式完整体系,任意环节的修改均可以通过整体关联响应变化的方式进行迭代升级,适用于多媒体跨媒体数据管理体系、检索体系的搭建实现,高质量跨媒体知识图谱的生成与管理利用和建立多媒体跨媒体数据关联关系以及统一表示方法。
- 还没有人留言评论。精彩留言会获得点赞!