一种基于Q-learning和规则的混合动力车辆运行实时能源管理方法与流程
本发明属于自动化技术领域,具体涉及一种基于q-learning和规则的混合动力车辆运行实时能源管理方法。
背景技术:
现有的混合动力车辆运行实时能源管理方法常利用基于规则或优化的算法对混合能源进行分配。其中基于规则的能源管理算法因为简单易行而运用广泛,但由于其过于单一而无法胜任复杂的车辆工况。而基于优化的算法虽然能将耗能降低到较低的范围,达到最优的燃油经济性,但由于其优化的前提是对车辆工况有较好的认知,因而基于优化的能源管理算法只能用于特定的工况,而无法用于面向复杂工况的在线的实时能源管理。另外,两种方法都缺乏减小电流波动对电池寿命的影响的研究。
技术实现要素:
本发明的目的是针对现有的部分算法的不足之处,提供一种融合q-learning和规则的基于学习的混合动力车辆运行实时能源管理方法。首先,本发明提供两种可选择的最大燃料电池功率输出设定值,其选择由规则决定,小功率输出有利于减小燃料电池的电流波动。其次,基于学习的方法在适应不同工况上比基于规则和优化的方法更加具有优越性,利用离线的方法在不同工况下训练,使能量管理控制器在实时测试时能适应复杂的工况。最后,超级电容作为辅助燃料电池的供能设备,弥补燃料电池在启动和加速阶段动力不足的缺陷,同时吸收制动能量,提高耗能经济性。
本发明的技术方案是通过数据采集,模型建立等手段,确立了一种基于q-learning和规则的混合动力车辆运行实时能源管理方法。利用该方法可显著提高混合动力车辆在不同工况下的实时耗能经济性,同时减小燃料电池的电流波动,延长电池使用周期。
本发明的具体技术方案如下:
一种基于q-learning和规则的混合动力车辆运行实时能源管理方法,其步骤如下:
s1:采集不同工况下,混合动力车辆运行过程中的样本数据;
s2:建立基于q-learning的能源管理系统,具体方法为s21~s23:
s21:根据超级电容soc设计状态空间,并对状态空间进行离散化:
其中soct表示t时刻的soc状态;socmin和socmax分别表示soc的最小值和最大值,d1表示状态空间的离散度,numstates表示状态个数;
s22:根据燃料电池输出功率设计动作空间,并对动作空间进行离散化:
at=k×d2
其中at表示燃料电池t时刻的功率输出,k表示以1为基准的动作下表索引,d2表示动作空间的离散度,max_cell_power表示燃料电池最大功率输出预设值,numactions表示动作个数;
s23:根据超级电容soc状态设计奖励函数,奖励函数形式如下:
其中rt表示t时刻的奖励,soct+1表示t+1时刻的soc状态;
s3:确定规则,用于对燃料电池最大功率输出预设值phigh或plow进行选择;规则的形式如下:
s4:基于s1中的样本数据,结合s2中建立的基于q-learning的能源管理系统和s3中确定的规则,离线训练控制器对混合能源进行实时分配管理,具体步骤如s41~s46:
s41.初始化值函数q(s,a)=0;初始化max_cell_power=plow;初始化迭代次数n=0;
s42.初始化初始状态s0=socinitial,其中socinitial为超级电容soc初始设定值;初始化时间t=1;n=n+1;
s43.根据贪心算法按照概率ε随机选出动作at,若不在概率ε内则使
s44.利用贝尔曼公式对值函数q(s,a)进行更新,形式如下:
其中η是学习速度;γ是折现参数;q(st,at)为t时刻的值函数;t为s1中采集的样本数据的行程时长;
s45.如果超级电容soct+1超出设定范围,即rt+1=-1000,则重复步骤s42到步骤s44;如果超级电容soct+1未超出设定范围,则执行t=t+1,并重复步骤s43到步骤s44,直到t=t;
s46.重复步骤s42到步骤s45,直到n=n,n为预设的最大迭代次数,完成值函数q(s,a)的更新;
s5:利用训练好的控制器在不同工况下对混合能源进行实时分配管理。
作为优选,所述的混合动力车辆由超级电容和燃料电池共同提供混合动力,超级电容作为辅助燃料电池的供能设备。
进一步的,超级电容的输出功率由混合动力车辆行驶所需总功率减去燃料电池输出功率得到。
作为优选,s1中的样本数据的采集方法为:在不同车辆工况下,获取车辆行驶所需的实时功率,记一段行程中t时刻所需的瞬时功率为pt,行程时长记为t。
作为优选,所述的工况包括ftp-75工况、wvusub工况、hwfet工况及manhattan工况。
本发明提出的混合动力车辆运行实时能源管理方法弥补了传统方法的不足,相比与传统的基于规则或优化的方法,本发明融合学习和规则,能显著提高耗能经济性,减少电流波动对燃料电池造成的影响,同时实现复杂工况下的在线实时能源管理。
附图说明
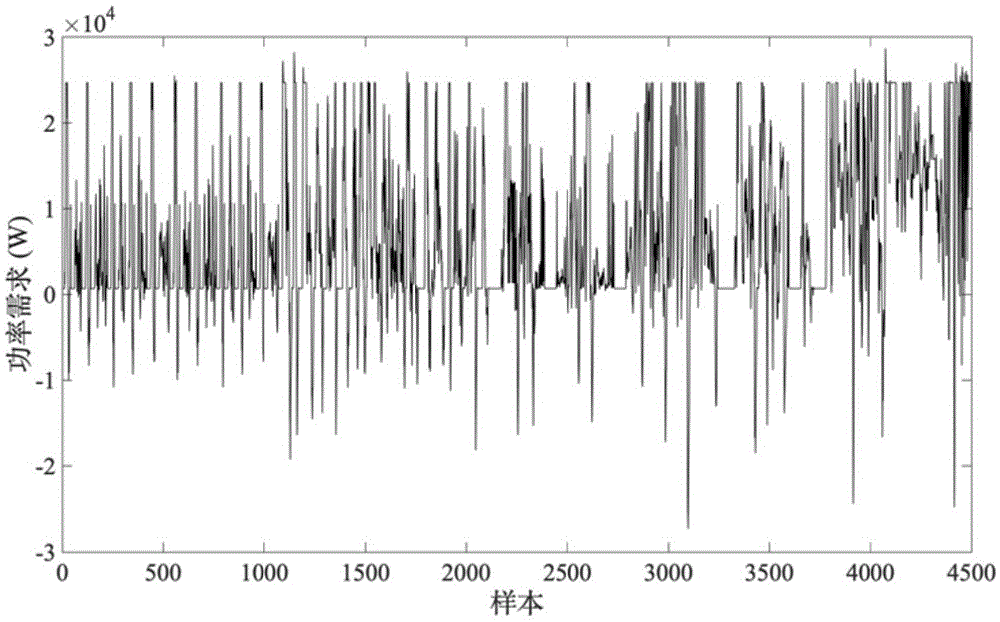
图1为实时测试中在混合工况下车辆运行功率需求;
图2为实时测试中在混合工况下车辆运行功率分配;
图3为实时测试中在混合工况下的功率误差;
图4为实时测试中在混合工况下超级电容的soc分布;
图5为实时测试中在hwfet工况下燃料电池输出功率变化率;
图6为实时测试中在hwfet工况下燃料电池输出电流变化率。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。本发明中各个实施方式的技术特征在没有相互冲突的前提下,均可进行相应组合。
本发明中的基于q-learning和规则的混合动力车辆运行实时能源管理方法,主要针对以超级电容和燃料电池作为混合动力的车辆,其中超级电容作为辅助燃料电池的供能设备,弥补燃料电池在启动和加速阶段动力不足的缺陷。超级电容在燃料电池动力不足时补充剩余功率,同时在制动时吸收制动能量,提高耗能经济性。本方法主要计算燃料电池的输出功率,而超级电容的输出功率由混合动力车辆行驶所需总功率减去燃料电池输出功率得到。两种动力来源的功率值由车辆内的控制器进行控制。为实现对燃料电池及超级电容的混合能量管理,本发明首先在离线状态下对基于q-learning的控制器进行训练,同时融合规则改变燃料电池的最大功率输出,以减小电流突变对燃料电池的影响,然后将离线训练好的控制器用于不同工况下的实时能源管理。下面详细描述本方法的具体实现步骤:
s1:采集不同工况下,混合动力车辆运行过程中的样本数据。采集方法为:在不同车辆工况下,获取车辆行驶所需的实时功率,记一段行程中t时刻所需的瞬时功率为pt,行程时长记为t。
典型工况包括但不限于ftp-75工况、wvusub工况、hwfet工况及manhattan工况等。
s2:建立基于q-learning的能源管理系统,具体方法为s21~s23:
s21:根据超级电容soc设计状态空间,并对状态空间进行离散化:
其中soct表示t时刻的soc状态;socmin和socmax分别表示soc的最小值和最大值,d1表示状态空间的离散度,numstates表示状态个数;
s22:根据燃料电池输出功率设计动作空间,并对动作空间进行离散化:
at=k×d2
其中at表示燃料电池t时刻的功率输出,k表示以1为基准的动作下表索引,d2表示动作空间的离散度,max_cell_power表示燃料电池最大功率输出预设值,numactions表示动作个数;
s23:根据超级电容soc状态设计奖励函数,奖励函数形式如下:
其中rt表示t时刻的奖励,soct+1表示t+1时刻的soc状态;
s3:确定规则,用于对燃料电池最大功率输出预设值进行选择;规则的形式如下:
s4:基于s1中的样本数据,结合s2中建立的基于q-learning的能源管理系统和s3中确定的规则,离线训练控制器对混合能源进行实时分配管理,具体步骤如s41~s46:
s41.初始化值函数q(s,a)=0;初始化max_cell_power=17kw;初始化迭代次数n=0;
s42.初始化初始状态s0=socinitial,其中socinitial为超级电容soc初始设定值;初始化时间t=1;n=n+1;
s43.根据贪心算法按照概率ε随机选出动作at,若不在概率ε内则使
s44.利用贝尔曼公式对值函数q(s,a)进行更新,形式如下:
其中η是学习速度;γ是折现参数;q(st,at)为t时刻的值函数;t为s1中采集的样本数据的行程时长;
s45.如果超级电容soct+1超出设定范围,即rt+1=-1000,则重复步骤s42到步骤s44;如果超级电容soct+1未超出设定范围,则执行t=t+1,并重复步骤s43到步骤s44,直到t=t;
s46.重复步骤s42到步骤s45,直到n=n,n为预设的最大迭代次数,完成值函数q(s,a)的更新和控制器的训练。
s5:利用离线训练好的控制器在不同工况下对混合能源进行实时分配管理。
下面基于上述方法,结合具体实施例对其技术效果进行进一步展示,部分参数的定义如前所述,不再赘述。
实施例
以ftp-75工况(又称udds)、wvusub工况、hwfet工况及manhattan工况4种典型循环工况为例,建立车辆运行实时能源管理模型。
步骤(1).从advisor软件中导出车辆在上述hwfet工况下实时功率需求pt,行程时长记为t。
步骤(2).建立基于q-learning的能源管理系统,具体方法是:
a.设计状态空间。选择超级电容的soc作为系统状态,对连续的soc离散化:
其中socmin=0.45,socmax=0.95,numstates=61。
b.设计动作空间。选择燃料电池的输出功率作为系统动作,对输出功率离散化:
at=k×d2
其中numactions=31;max_cell_power=17kwor24kw,具体值由规则决定;t时刻超级电容的功率输出可以通过pt-at得到。
c.设计奖励函数。根据瞬时的soc状态设计奖励函数形式如下:
其中rt表示t时刻的奖励,soct+1表示t+1时刻的soc状态。
步骤(3).设计规则,具体方法是:
根据超级电容soc的状态选择最大燃料电池输出功率预设值,规则的形式如下:
步骤(4).利用基于步骤(2)的基于q-learning能源管理系统和步骤(3)的规则对步骤(1)获取的功率进行能源分配,具体方法是:
ⅰ.初始化max_cell_power=17kw;初始化迭代次数n=0;初始化值函数q(s,a)=0,其中s表示状态,a表示动作,st、at分别表示t时刻的状态、动作。
ⅱ.初始化初始状态s0=0.8;初始化时间t=1;n=n+1。
ⅲ.根据贪心算法按照概率ε=0.1随机选出动作at,若不在概率ε内无法选出动作,则使
iv.利用贝尔曼公式对值函数q(s,a)进行更新,形式如下:
其中η=0.0001,γ=0.99
v.如果超级电容soct+1超出设定范围,即rt+1=-1000,则重复步骤ii到步骤iv;如果超级电容soct+1未超出设定范围,则执行t=t+1,并重复步骤iii到步骤iv,直到t=t。
vi.重复步骤ii到步骤v直到n=2000,此时完成值函数q(s,a)的更新和控制器的训练。
步骤(5).利用步骤(4)离线训练好的控制器在上述4种典型工况下进行实时测试。
结果显示本发明公开的方法在上述测试中能控制超级电容soc维持在给定范围内,同时满足车辆运行的实时功率需求。在上述测试工况下的氢气消耗为0.5340(g),相比传统的基于模糊规则的能源管理策略减少了9.03%耗氢量。另外,本发明还验证了融合规则的q-learning能源管理策略对燃料电池功率和电流波动的显著改善。通过分别计算在上述测试工况下燃料电池的功率和电流变化率的均方根,证明了基于融合规则的q-leaning能源管理策略相比基于传统的q-learning能源管理策略在功率和电流上分别减少了51.71%和51.54%波动。
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!