一种基于CNN和海量日志的SQL注入识别方法与流程
本发明涉及sql注入识别方法,具体涉及一种基于cnn和海量日志的sql注入识别方法。
背景技术:
sql注入形式多样,不可避免的出现新的方法绕过传统检测;现有检测方法主要包括支持向量机(svm),正则匹配、决策树、朴素贝叶斯方法等;其中正则匹配应用广泛,效果较好;但是sql注入形式多样,不可避免的出现新的方法绕过正则匹配技术,同时由于基于现有规则,很难识别新的攻击;传统的机器学习技术(svm、朴素贝叶斯和决策树等统计学习方法)需要人为的给出特征,不易得到其最好的特征且不能判断其是否是最好特征以及不易判断是否有更好的特征,造成识别准确率不高,容易出现大量误报漏报。
技术实现要素:
本发明提供一种可提取sql注入的隐藏共有特征,识别出绕过正则的sql注入攻击流量的基于cnn和海量日志的sql注入识别方法。
本发明采用的技术方案是:一种基于cnn和海量日志的sql注入识别方法,包括以下步骤:
步骤1:从网站日志中提取url访问记录,提取url中的查询参数部分;
步骤2:对步骤1中提取的数据进行预处理;
步骤3:搭建cnn网络,根据步骤2得到的数据对cnn网络进行训练,得到cnn模型;
步骤4:根据步骤3得到的模型进行实时检测基于查询语句的sql注入攻击。
进一步的,所述步骤1中提取的url访问记录为网站日志中已标记好的具有查询语句且请求方法为get的url访问记录。
进一步的,所述步骤1中提取url中的查询参数部分之后还需要对样本进行去重处理。
进一步的,所述步骤2中的预处理包括以下过程:
s1:统计每条样本的平均长度,即字符数量;
s2:对样本进行词向量化训练,得到词向量化模型;
s3:根据步骤2中的模型对样本进行向量化,每个样本均转化为一个二维矩阵;
s4:将步骤3得到的二维矩阵转化为指定大小矩阵。
进一步的,所述步骤3具体过程如下:
s11:将正负样本打乱,一部分样本作为训练集,剩余的作为测试集;
s12:搭建cnn网络进行训练;
s13:通过验证集对步骤s12得到的模型进行测试,若误差满足预设要求则停止,否则调整cnn网络参数后继续进行训练。
本发明的有益效果是:
(1)本发明能自动提取sql注入的隐藏共有特征,识别出绕过正则的sql注入攻击流量,且速度快;
(2)本发明基于单个字符进行向量化,词量较少,可保留query语句所有信息,可降低训练难度和训练成本。
附图说明
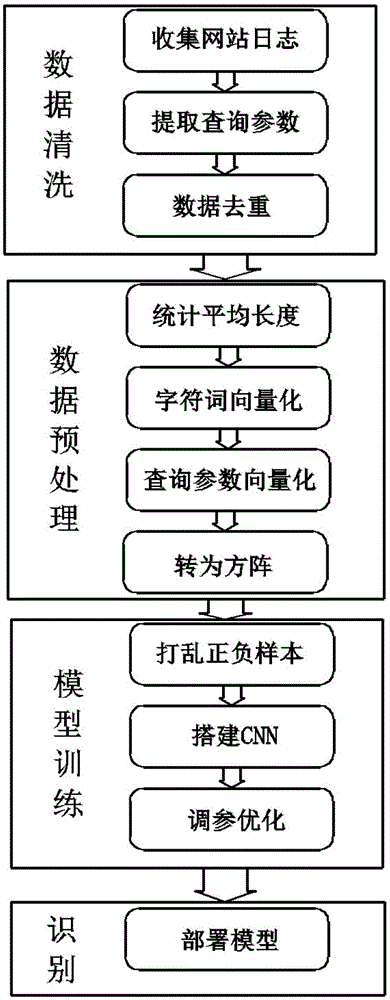
图1为本发明流程示意图。
图2为本发明实施例中roc曲线。
具体实施方式
下面结合附图和具体实施例对本发明做进一步说明。
如图1所示,一种基于cnn和海量日志的sql注入识别方法,包括以下步骤:
步骤1:从网站日志中提取url访问记录,提取url中的查询参数部分;(数据清洗)
提取出网站日志中已标记好的查询语句且请求方法为get的url访问记录,包括正常的sql注入的。
如http://www.abc.com/a/b/?query#fragment,具有query参数的url,即问号后面,井号前面的字符串(一般情况下格式为key1=value1&key2=value2…);为了保证样本具有足够的代表性,需要大量的数据(数十万到百万级别),如果已标记日志量太大,可按时间均匀采样。
然后提取url中的查询参数部分,如http://www.abc.com/a/b/?query#fragment,只保留query参数部分。
对于正负样本均可能出现重复,去重可减少由重复带来的冗余信息,提高训练样本质量。
步骤2:对步骤1中提取的数据进行预处理(数据预处理);
包括以下过程:
s1:统计每条样本的平均长度,即字符数量;通过统计样本平均长度确定矩阵行数,近似等于平均长度,如abc长度即为3。
s2:对样本进行词向量化训练,得到词向量化模型;
使用word2vec方法(谷歌开源的词向量化方法)将样本进行词向量化训练,得到一个词向量化模型;此模型保存了每个字符对应的向量;向量化维度值不宜大于样本平均长度,并且以2为n次方为宜,比如16,32,64等;以单个字符作为一个向量单位,无须对其进行url解码;解码后会大大增加字符数量(会出现大量的中文字符,如果过滤掉中文字符会丢掉部分有用信息,因为有的sql注入会利用中文字符)。
例如“a”表示[0.1,1.2,0,1,3]这样的5元素向量。
s3:根据步骤2中的模型对样本进行向量化,每个样本均转化为一个二维矩阵;
若模型中没有样本中出现的字符,则用1向量填充,即行向量每个元素值都取1;每条样本均可转化为一个二维矩阵,列数即为每个字符确定的向量维度,行数即为样本字符数量。
如abc向量化示意图
a[0.1,1.2,0,1,3]
b[0,1.6,10,11,2.3]
c[0.8,1.2,0.67,1.983,1.41]
s4:将步骤3得到的二维矩阵转化为矩阵。
若矩阵行数小于指定值,则在最下方一直补0向量至其为指定大小矩阵,若行数大于指定值,则去掉最后若干行使其变为指定大小矩阵。
步骤3:搭建cnn网络,根据步骤2得到的数据对cnn网络进行训练,得到cnn模型(模型训练);
具体过程如下:
s11:将正负样本打乱,一部分样本作为训练集,剩余的作为验证集;
由于在训练时是将所有样本分批次导入训练,打乱正负样本可防止训练时出现整个训练批次全是正样本或负样本;随机选取部分已标记正负样本作为训练集(十到二十万左右即可),剩下的作为验证集。
s12:搭建cnn网络进行训练;
一般来说,训练数据量越大越好,但训练成本也会上升。
s13:通过验证集对步骤s12得到的模型进行测试,若误差满足预设要求则停止,否则调整cnn网络参数后继续进行训练。
通过验证集对训练好的模型进行测试,若误差(正确率,损失函数值等)在可接受范围内则停止,否则通过调整神经网络参数继续进行训练,参数包括cnn结构,网络层数、训练次数、卷积核大小、数量、池化函数、分类函数、激活函数等等;通常训练的模型对验证集的分类正确率在99%以上。
步骤4:根据步骤3得到的模型进行实时检测基于查询语句的sql注入攻击。
将模型部署到服务器环境中可实时检测基于查询语句的sql注入攻击,也可以将本发明用于检测历史日志。
实施例
本发明方法的roc曲线如图2所示,从图中可以看出本发明分类性能好;本发明构建的模型是面对无规则的,也就是没有明显的可见特性,对于能绕过传统正则特征匹配(url中是否有敏感字符串,所以存在各种花式绕过技巧)的sql注入仍然有很好的检测效果,传统的正则匹配方法检测不出来的sql注入,本发明构建的模型仍然能检测出来,且速度快。
从图2中可以看出,本发明漏报率和误报率很低;经测试证明本发明正确率超过cnn原本针对的图像识别领域平均正确率,在300万条数据上测试,正确率在99.7%。
roc曲线指受试者工作特征曲线(receiveroperatingcharacteristiccurve),是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系;它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、特异性为横坐标绘制成曲线;曲线下面积越大,诊断准确性越高;在roc曲线上,最靠近坐标图左上方的点为敏感性和特异性较高的临界值。
进一步进行测试,分别对211万条正样本、118万条负样本、330万样本(正样本2117860,负样本1187504)进行测试,其正确率分别为99.97%、99.9%和99.95%。
本发明中出现的符号如下:
sql注入:通过把sql命令插入到web表单提交或输入域名或页面请求的查询字符串;最终达到欺骗服务器执行恶意的sql命令;具体来说,它是利用现有应用程序,将(恶意的)sql命令注入到后台数据库引擎执行的能力,它可以通过在web表单中输入(恶意)sql语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行sql语句。
cnn:卷积神经网络(convolutionalneuralnetwork),是一种深度前馈人工神经网络;cnn是一个针对图像识别问题设计的神经网络,它模仿人类识别图像的多层过程。
url:指统一资源定位符。
sql:结构化查询语言(structuredquerylanguage)。
本发明主要用于识别通过url查询语句进行sql注入的行为,把url查询语句进行二分类,分为正常的和sql注入的;由于正常的查询语句和sql注入的查询语句之间会有公共的特征差别,但无法明显看出,因此可以根据这些差别进行分类。
sql注入的查询语句往往有很大的冗余信息,因此与cnn可去除冗余信息的特性相匹配;正常的查询语句和sql注入的查询语句之间有着不明显的隐藏特征,也就是说无法人为的提供很好的分类特征,不好的特征则会导致识别大量出错;他们之间的差别往往存在不明显的特征,无法通过观察得到,cnn可以自动提取认为无法识别的特征,因此使用cnn可提取隐藏共有特征。
现有的sql注入检测主要采用正则匹配进行识别,采用正则技术识别准确率高、速度快,但是不能识别新的攻击,不可避免的出现新的绕过方法以避开正则,比如url多次编码;本发明则可以自动提取sql注入的隐藏共有特征,识别出绕过正则的sql注入攻击流量,且速度快;传统的机器学习方法需要人为筛选特征,而好的特征不易得到,特征的好坏直接影响到识别准确率;一些深度学习识别对url预处理很麻烦,还会失去部分重要信息,比如对url解码,可能会出现中文字符,不去掉会导致词量大量增加,去掉则会少了部分sql注入的重要特征信息;本发明基于单个字符进行向量化,词量较少,但可保留query语句所有信息,且word2vec方法还会保留字符之间的组合信息,比如位置信息,词量少则可以降低训练难度和训练成本。
- 还没有人留言评论。精彩留言会获得点赞!