基于条件变分自编码的密码攻击评估方法与流程
本发明涉及互联网数据加密领域,尤其涉及基于条件变分自编码的密码攻击评估方法。
背景技术:
变分自编码(variationalautoencoder,vae)是一种基于标准自编码模型正则化版本的生成模型。
密码是数据加密和用户认证的普遍方式,用户设置的密码并不完全是随机性的,因此很容易受到密码破解工具的攻击。使用密码猜测算法是评估用户密码强度和安全性的有效方法。
但是,用户密码容易出现一些弊端,多个密码数据库泄漏表明用户倾向选择容易猜到的密码,主要由常见的字符串和数字组成,并且有不少密码创建规则中包含多种多样的个人信息组合方式,所以容易受到密码破译算法攻击,确认用户密码设置是否安全,是一个十分重要的安全问题;一些现有的传统的统计方法无法准确地学习到用户的密码设置习惯,同时需要耗费大量的计算资源和时间代价,不适合实时密码强度评估,而且大部分现有的密码安全性检测算法,只考虑了密码数据集中字符放入的概率分布,并没有把用户个人信息(如邮箱、用户名等)纳入特征条件,而这些个人信息往往与密码有很强的相关性。因此,本发明提出基于条件变分自编码的密码攻击评估方法,以解决现有技术中的不足之处。
技术实现要素:
针对上述问题,本发明通过利用条件变分自编码模型,将用户个人信息中的用户名、邮箱地址和电话号码等条件特征,训练密码攻击模型,并且在编码器端分别使用双向gru循环神经网络和cnn文本卷积神经网络,可以实现对密码序列和用户个人信息的编码和特征的抽象提取,本发明方法可以有效地拟合密码数据的分布和字符组合规律,生成高质量的猜测密码数据,对提高用户密码强度和安全性具有显著效果。
本发明提出基于条件变分自编码的密码攻击评估方法,包括以下步骤:
步骤一:构建变分自编码模型
先基于标准自编码模型正则化后生成一个变分自编码模型,再将一个先验分布强加到隐变量
步骤二:构建条件变分自编码模型
在上述步骤一中的变分自编码模型上加上生成条件,利用变分自编码模型构建出条件变分自编码模型,然后生成特定条件下的生成数据;
步骤三:构建密码攻击模型
采用一个两层双向gru循环神经网络和cnn文本卷积神经网络组成密码攻击模型编码器,然后计算出密码攻击模型最后时刻输出状态,再将最后时刻输出状态经过两个全连接层生成μ和σ,然后从标准正态分布中采样出与μ同维度的随机向量,再经过重参数化后得到中间编码z′,然后根据用户个人信息生成条件编码向量,最后生成用户密码猜测序列;
步骤四:综合利用条件变分自编码模型与密码攻击模型
通过标准高斯先验分布生成的隐编码z生成密码序列,再利用密码攻击模型生成条件编码向量y,再将隐变量
进一步改进在于:所述步骤一中先验分布是规整的几何形式,取标准高斯分布,使得模型能够生成更接近原始数据分布的样本,先利用变分自编码模型将一个先验分布强加到隐变量
进一步改进在于:所述步骤一中变分自编码模型的损失函数如公式(1)所示:
公式(1)中,
进一步改进在于:所述步骤二中条件变分自编码模型的损失函数如公式(2)所示:
公式(2)中,y是条件变量,解码器会在条件y下生成特定的数据。
进一步改进在于:所述步骤二中生成条件为用户的个人信息,具体包括用户名、邮箱地址和电话号码等。
进一步改进在于:所述步骤三中先采用一个两层双向gru循环神经网络和cnn文本卷积神经网络组成密码攻击模型编码器,然后根据公式(3)计算出密码攻击模型最后时刻输出状态,再将最后时刻输出状态经过两个全连接层生成μ和σ,其中μ和σ表达式如公式(4)和公式(5)所示:
ht=bigrue(ht-1,xt-1)(3)
μ=tanh(wμht)(4)
σ=tanh(wσht)(5)
再根据公式(6)从标准正态分布中采样出与μ同维度的随机向量,经过重参数化后得到中间编码z′,然后把用户个人信息当作字符串串联起来,经过cnn文本卷积神经网络对其编码生成条件编码向量,所述编码向量的表达公式如公式(7)所示,然后再根据公式(8)将中间编码z′与条件编码拼接在一起形成最终隐编码,最后根据公式(9)生成用户密码猜测序列;
z′=randn·μ+σ(6)
y=cnn(g)(7)
z=[z′,y](8)
ht,xt′=grud([ht-1,y,z],x′t-1)(9)
进一步改进在于:所述步骤三中双向gru循环神经网络用来对用户密码序列进行编码,cnn文本卷积神经网络用来对用户个人信息进行编码。
进一步改进在于:所述步骤四中编码器在先验分布的控制下,将数据集中的密码序列抽象编码填充在一个高维的先验分布空间,在生成密码时,通过在隐编码的先验分布中采样出的隐变量
本发明的有益效果为:通过利用条件变分自编码模型,将用户个人信息中的用户名、邮箱地址和电话号码等条件特征,训练密码攻击模型,并且在编码器端分别使用双向gru循环神经网络和cnn文本卷积神经网络,可以实现对密码序列和用户个人信息的编码和特征的抽象提取,同时在解码器端使用双向gru循环神经网络,可以实现对用户个人信息和密码数据隐编码的解码,生成密码序列,本发明方法可以有效地拟合密码数据的分布和字符组合规律,生成高质量的猜测密码数据,对提高用户密码强度和安全性具有显著效果,并且可以准确计算出所需猜测次数,匹配出尚未泄漏的密码,具有对密码安全提供预警的优点。
附图说明
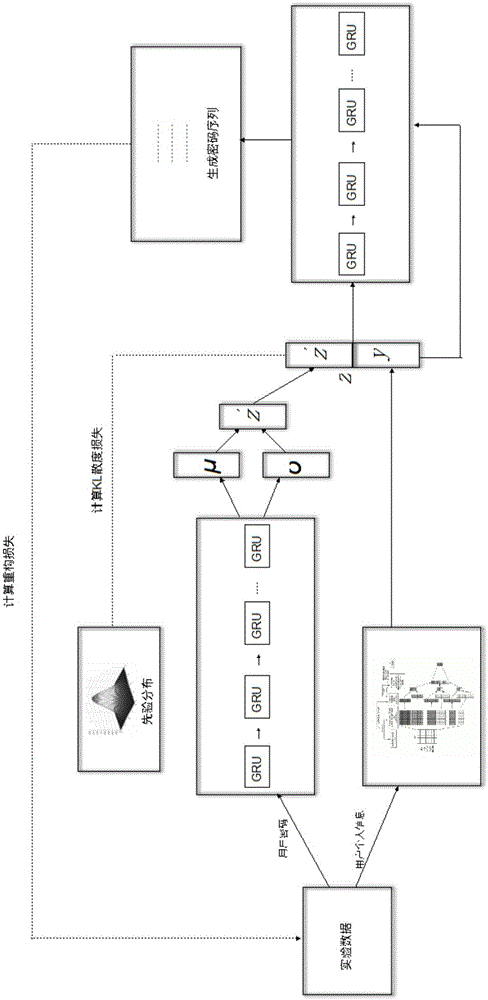
图1为本发明密码攻击模型结构示意图。
具体实施方式
为了加深对本发明的理解,下面将结合实施例对本发明做进一步详述,本实施例仅用于解释本发明,并不构成对本发明保护范围的限定。
根据图1所示,本实施例提出基于条件变分自编码的密码攻击评估方法,包括以下步骤:
步骤一:构建变分自编码模型
先基于标准自编码模型正则化后生成一个变分自编码模型,利用变分自编码模型将一个先验分布强加到隐变量
公式(1)中,
步骤二:构建条件变分自编码模型
在上述步骤一中的变分自编码模型上加上生成条件,生成条件为用户的个人信息,具体包括用户名、邮箱地址和电话号码,利用变分自编码模型构建出条件变分自编码模型,然后生成特定条件下的生成数据,条件变分自编码模型的损失函数如公式(2)所示:
公式(2)中,y是条件变量,解码器会在条件y下生成特定的数据;
步骤三:构建密码攻击模型
先采用一个两层双向gru循环神经网络和cnn文本卷积神经网络组成密码攻击模型编码器,双向gru循环神经网络用来对用户密码序列进行编码,cnn文本卷积神经网络用来对用户个人信息进行编码,然后根据公式(3)计算出密码攻击模型最后时刻输出状态,再将最后时刻输出状态经过两个全连接层生成μ和σ,其中μ和σ表达式如公式(4)和公式(5)所示:
ht=bigrue(ht-1,xt-1)(3)
μ=tanh(wμht)(4)
σ=tanh(wσht)(5)
再根据公式(6)从标准正态分布中采样出与μ同维度的随机向量,经过重参数化后得到中间编码z′,然后把用户个人信息当作字符串串联起来,经过cnn文本卷积神经网络对其编码生成条件编码向量,所述编码向量的表达公式如公式(7)所示,然后再根据公式(8)将中间编码z′与条件编码拼接在一起形成最终隐编码,最后根据公式(9)生成用户密码猜测序列,;
z′=randn·μ+σ(6)
y=cnn(g)(7)
z=[z′,y](8)
ht,xt′=grud([ht-1,y,z],x′t-1)(9)
步骤四:综合利用条件变分自编码模型与密码攻击模型
通过标准高斯先验分布生成的隐编码z生成密码序列,再利用密码攻击模型生成条件编码向量y,再将隐变量
为验证本发明方法的有效性与优越性,进行以下实验:
采用12306、csdn和人人网数据真实密码数据集构成,数据集具体描述如表1所示:
表1实验数据集
为验证方法有效性,选择四种密码猜测算法作比较,分别是pcfg,omen,passgan和passlstm,其中pcfc和omen是基于传统的统计方法,passgan采用深度学习中的生成对抗网络实现,passlstm基于lstm循环神经网络的语言模型。
实验模型分别根据实验数据集训练样本训练出密码生成模型,在测试集中规定每个密码的破解尝试次数不超过限定次数,即在1000、2000、3000、4000和5000次尝试以内破解成功视为模型攻击成功,得出表2、表3和表4所示:
表212306数据集破解成功率
表3csdn数据集破解成功率
表4人人网数据集破解成功率
根据表2可以得出,12306数据集当中,用户的个人信息较多,本发明方法模型可以提取出更多条件信息,比其他几个模型有较明显的优势,表现出更好的性能,但由于12306数据集样本量只有10万多条,各模型的破解成功率也不如csdn和人人网数据集表现得好。
根据表2、表3和表4可以得出,在三个数据集上本发明方法模型都取得了最佳结果,也证明了用户个人信息的条件嵌入对破解密码生成的有效性。
在相同的破解次数下,对不同数据集进行实验得出如表5、表6、表7、表8和表9所示的结果:
表5不同数据1000尝试次数破解成功率
表6不同数据2000尝试次数破解成功率
表7不同数据3000尝试次数破解成功率
表8不同数据4000尝试次数破解成功率
表9不同数据5000尝试次数破解成功率
根据表5、表6、表7、表8和表9可以得出,在不同的破解次数的条件下,本发明方法都取得了较好的结果。由于破解次数的增加,减少了生成破解的密码的随机性,本发明方法也会比其他对比算法表现的更加有优势,具有更高的破解成功率。
通过利用条件变分自编码模型,将用户个人信息中的用户名、邮箱地址和电话号码等条件特征,训练密码攻击模型,并且在编码器端分别使用双向gru循环神经网络和cnn文本卷积神经网络,可以实现对密码序列和用户个人信息的编码和特征的抽象提取,同时在解码器端使用双向gru循环神经网络,可以实现对用户个人信息和密码数据隐编码的解码,生成密码序列,本发明方法可以有效地拟合密码数据的分布和字符组合规律,生成高质量的猜测密码数据,对提高用户密码强度和安全性具有显著效果,并且可以准确计算出所需猜测次数,匹配出尚未泄漏的密码,具有对密码安全提供预警的优点。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!