基2-2算法的快速傅里叶变换硬件设计方法与流程
本发明属于超大规模集成电路(verylargescaleintegration,简称vlsi)设计范畴,涉及一种16点基22算法结构的快速傅里叶变换的vlsi结构。
背景技术:
快速傅里叶变换(fastfouriertransform,fft)已经成为信号处理中最重要的算法之一,在通信、滤波以及数字频谱分析等领域应用广泛。为满足数字信号处理的实时性需求,人们已经提出许多硬件实现的fft结构,来提高处理速度以及减少硬件资源的使用情况。
流水线fft结构是最常见的fft硬件结构之一。这种结构可以使用较少的硬件资源,连续不间断地处理流入的数据。目前有两种流水线结构的fft:串行流水线结构,这种结构每个时钟周期处理1个采样点数据;另一种是并行流水线结构,这种结构每个时钟周期处理多个采样点数据。
1996年he和torkelson在论文《anewapproachtopipelinefftprocessor》[1]提出基22算法,基22fft算法的提出是fft硬件架构设计实现的里程碑。基22算法结合基2与基4算法的优势,对偶序号使用基2算法,对奇序号使用基4算法。其以运算量小、蝶形运算简单等优势,一经提出便得到了迅速发展。
多路延迟转换fft结构(multipathdelaycommutator,mdc)是目前使用最少数量蝶形运算单元以及存储单元的并行流水线fft结构,可有效利用旋转因子复数乘法器单元,garrido和huang在论文《feedforwardffthardwarearchitecturesbasedonrotatorallocation》[2]中使资源使用率达到100%。
串行流水线fft结构同样得到广泛研究。he和torkelson在论文《designandimplementationofa1024-pointpipelinefftprocessor》[3]中设计的典型的基2单路延迟反馈结构(singledelayfeedbacksdf)对蝶形单元和旋转因子复数乘法器单元的使用率只有50%。使用其他算法,例如在zhou和hwang的论文《implementationsandoptimizationsofpipelinefftsonxilinxfpgas》[4]中,基4和基22算法提高了旋转因子复数乘法器单元的使用率,但是没有提高蝶形单元的使用率。在liu和yu的论文《apipelinedarchitecturefornormali/oorderfft》[5]中,使用单路延迟转换结构(singledelaycommutator,sdc)提高了旋转因子复数乘法器单元和蝶形单元的使用率,但是这种结构增加了存储单元。wang和liu在论文《acombinedsdc-sdfarchitecturefornormali/opipelinedradix-2》[6]中提出一种sdf和sdc相结合的流水线结构,可以分时复用乘法器和加法器,提高了计算速度,但是硬件资源消耗较大。
参考文献
[1]hes,torkelsonm.anewapproachtopipelinefftprocessor[c]//internationalparallelprocessingsymposium.ieeecomputersociety,1996.honolulu:ieee,1996:766-770.
[2]garridom,huangsj,chensg.feedforwardffthardwarearchitecturesbasedonrotatorallocation[j].ieeetransactionsoncircuits&systemsiregularpapers,2018,pp(99):1-12.
[3]hes,torkelsonm.designandimplementationofa1024-pointpipelinefftprocessor[c]//customintegratedcircuitsconference,1998.proceedingsoftheieee.santaclara:ieee,1998:131-134.
[4]zhoub,hwangd.implementationsandoptimizationsofpipelinefftsonxilinxfpgas.[c]//internationalconferenceonreconfigurablecomputingandfpgas,2008.reconfig.cancun:ieee,2008:325-330.
[5]liux,yuf,wangzk.apipelinedarchitecturefornormali/oorderfft[j].frontiersofinformationtechnology&electronicengineering,2011,12(1):76-82.
[6]wangz,liux,heb,etal.acombinedsdc-sdfarchitecturefornormali/opipelinedradix-2fft[j].ieeetransactionsonverylargescaleintegrationsystems,2015,23(5):973-977.
技术实现要素:
本发明提供一种快速傅里叶变换硬件设计方法,此设计方法结合基22算法的优点,设计一种基于串行蝶形单元基22算法结构fft,对比其他现有结构,本发明设计的fft使用了更少的蝶形单元、旋转因子乘法器和存储单元,各个模块的使用率达到100%,并且与现有的串行蝶形单元的基2算法结构相比,相应改进了旋转因子乘法器的结构,使其硬件使用资源更少,节约了硬件资源,缩短了关键路径。本发明的技术方案为:
一种基2-2算法的快速傅里叶变换硬件设计方法,采用频域抽取方式,得到频域抽取的基22算法的16点fft,并得到16点的数据流图,设计16点基于串行蝶形单元的基22fft的整体结构;此结构包含4个处理级,每一级分别包含处理单元和逆序单元;其中处理单元包括蝶形单元和旋转因子乘法器单元。蝶形单元只包含2个加法器,采用一个实数加法器和减法器的串行蝶形单元,使用两个时钟周期完成计算,分别完成实部和虚部的加减法,针对奇数处理级和偶数处理级分别设计出简单旋转因子乘法器和复杂旋转因子乘法器单元,简单旋转因子乘法器完成旋转因子为1,-1,j,-j时的乘法操作,只包含2个多路选择器和一个反相器,复杂旋转因子乘法器完成旋转因子为实部和虚部都不为零时的乘法操作;逆序单元用于缓存数据并改变数据在每一个处理级的输入顺序,置于每级处理单元之后。
优选地,第一个数据和第八个数据,x[0]和x[8]首先进入第一级的处理单元,然后计算x[2]和x[10],以此类推,连续的数据按照顺序进入每一级处理单元,逆序单元将输入数据进行重新排列将间隔l个时钟周期的两个输入数据交换,控制信号通过一个计时器得到,与流水线的时钟延迟相同,以当第一个数据进入fft处理器时计数器开始工作,将所有逆序单元所使用的寄存器相加得到完整的fft处理器所使用的寄存器总数以及整体时钟延迟。
本发明提供了一种硬件效率更高的16点fft架构,采用了串行蝶形单元,节省了硬件开销,具有更高的硬件效率。
附图说明
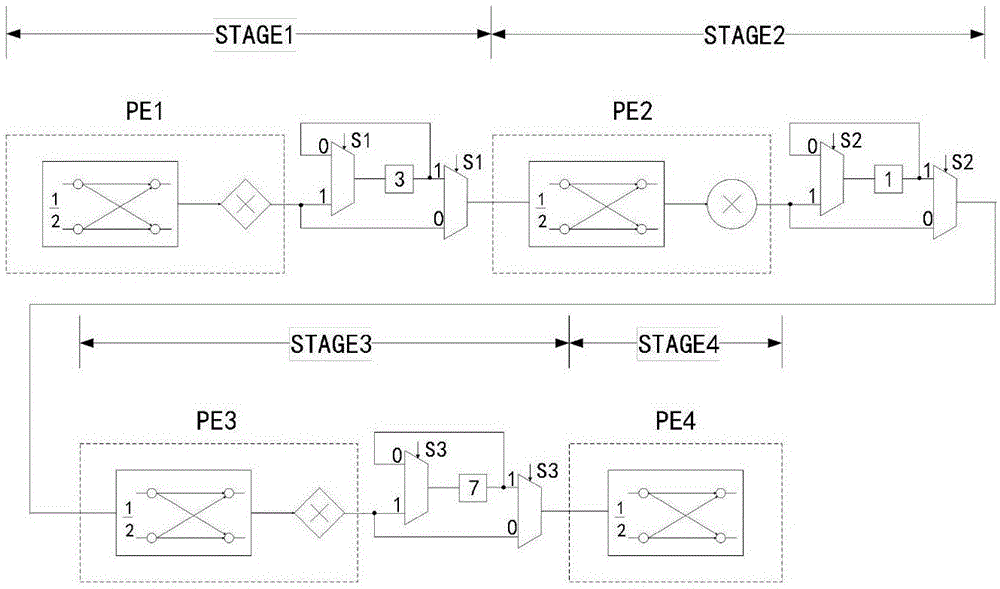
图1为16点频域抽取结构基22fft整体结构示意图
图2为包含复杂旋转因子乘法器的基22结构fft处理单元示意图
图3为包含简单旋转因子乘法器的基22结构fft处理单元示意图
图4为16点fft中数据进入各级处理单元顺序示意图
图5为逆序模块示意图
具体实施方式
下面结合附图对本发明进行详细说明。
如图1所示,给出了16点频域抽取的基22结构的fft。此结构包含4级,分别包含处理单元和逆序单元。其中处理单元包括蝶形单元和旋转因子乘法器单元。简单旋转因子乘法器使用菱形表示,复杂旋转因子乘法器使用圆形表示,复杂旋转因子乘法器即是现有技术中通用的旋转因子乘法器,为了与简单旋转因子乘法器相区别,此处称为复杂旋转因子乘法器。
处理单元
串行蝶形单元上标记数字1/2,代表它与传统的蝶形处理单元相比只需要一半的逻辑单元,它只使用一个实数加法器和减法器。串行蝶形单元使用两个时钟周期完成计算,分别完成实部和虚部的加减法。
根据基22算法的特点,复杂旋转因子乘法器和简单旋转因子乘法器在各级的处理单元中是交替使用的,即当上一级的处理单元中使用简单旋转因子乘法器,则在下一级的处理单元中使用复杂旋转因子乘法器。
图2和图3为在dif结构的串行蝶形单元基22fft中的处理单元结构,图2表示包含复杂旋转因子乘法器的处理单元,图3表示包含简单旋转因子乘法器的处理单元。简单旋转因子乘法器完成旋转因子为1,-1,j,-j时的乘法操作,从图中可以看出只包含2个多路选择器和一个反相器,占用硬件资源少。复杂旋转因子乘法器完成旋转因子为实部和虚部都不为零时的乘法操作。处理单元包含半个传统的蝶形单元和一个复杂旋转因子乘法器或者一个简单旋转因子乘法器。处理单元完成蝶形运算和旋转因子乘法运算:
其中输入x0=xr0+jxi0,x1=xr1+jxi1,输出y0=yr0+jyi0,y1=yr1+jyi1。x代表输入数据,y代表处理单元输出数据,z代表蝶形单元的输出。下脚标0代表第0个输入数据,1代表第1个输入数据。下角标r代表数据的实部,i代表数据的虚部。e为自然常数,j代表虚数符号,α0和α1分别代表两组数据对应的旋转因子角度。
表1表示了处理单元的时序。首先串行蝶形单元处理输入的实部,然后处理虚部。在第0个时钟周期,数据1的实部和虚部进入fft模块,在第二个时钟周期数据2进入模块中,同时蝶形单元计算前两个输入的两个数据的实部加法和减法,然后在第3个时钟周期输入数据3,同时蝶形单元计算虚部加法和减法,并且完成zr1和zi0的交换,进入旋转因子乘法器,计算得出yr0和yi0,并且在下一周期完成数据4的输入以及数据3和数据4的实部加减法运算以及yr1和yi1的计算。整个模块使用流水线设计。其中yr0=zr0cosα0+zi0sinα0,yi0=zr0sinα0-zi0cosα0,yr1=zr1cosα1+zi1sinα1,yi1=zr1sinα1-zi1cosα1。
基22算法的结构把复杂旋转因子乘法器和简单旋转因子乘法器在每级交替使用,在每个处理单元中从输入到输出同样需要2个时钟周期。关键路径包含2个多路选择器和一个乘法器和一个加法器。
表1基22结构fft处理单元时序
数据输入顺序
处理单元在连续的时钟下对一对数据进行蝶形运算和旋转因子相乘运算。而每一级处理单元所处理的数据顺序不同,所以就需要使用逆序模块将数据缓存并进行重新排序,使下一级的处理单元能够正确工作。逆序模块放置在每级处理单元之后。
图4表示串行蝶形单元fft的数据处理顺序,每一列从上到下代表本级的数据输入顺序。第一个数据和第八个数据,x[0]和x[8]首先进入第一级的处理单元,然后计算x[2]和x[10],以此类推。连续的数据按照顺序进入每一级处理单元。
为了得到图4所示的输入顺序,使用逆序模块将输入数据进行重新排列。图5是逆序模块示意图,此模块可以将间隔l个时钟周期的两个输入数据交换。在图1中第1、第2和第3级中交换的数据输入间隔分别为3、1和7个时钟周期,和图5中表示的逆序单元中的数字相同。
对于n点串行蝶形单元结构的fft,n=log2n。在当前运算级数s=1,2,…,n-2时,逆序单元的缓存大小和延迟为
l=2n-s-1-20\*mergeformat(3)
当s=n-1时,
l=2n-1\*mergeformat(4)
控制信号可以通过一个n比特大小的计数器来得到,计数器从0到n-1计数,对于长度为l=2i-1的逆序单元来说,控制信号si为:
控制信号必须与流水线的延迟相同,所以当第一个数据进入fft处理器时计数器开始工作。将所有逆序单元所使用的寄存器相加可以得到完整的fft处理器所使用的寄存器总数以及整体时钟延迟:
在n点串行蝶形单元结构fft中,处理单元中的寄存器和逆序模块中的寄存器一共约为n个,即理论上的n点fft所使用寄存器的最小值。
根据表2,本发明使用的旋转因子乘法器、加法器和存储单元最少,具有极高的硬件效率。这种结构是一种高性能的fft算法的vlsi结构。
表2不同结构硬件资源理论值
对比方案涉及的参考文献如下:
[1]hes,torkelsonm.designandimplementationofa1024-pointpipelinefftprocessor[c]//customintegratedcircuitsconference,1998.proceedingsoftheieee.santaclara:ieee,1998:131-134.
[2]zhoub,hwangd.implementationsandoptimizationsofpipelinefftsonxilinxfpgas.[c]//internationalconferenceonreconfigurablecomputingandfpgas,2008.reconfig.cancun:ieee,2008:325-330.
[3]liux,yuf,wangzk.apipelinedarchitecturefornormali/oorderfft[j].frontiersofinformationtechnology&electronicengineering,2011,12(1):76-82.
[4]wangz,liux,heb,etal.acombinedsdc-sdfarchitecturefornormali/opipelinedradix-2fft[j].ieeetransactionsonverylargescaleintegrationsystems,2015,23(5):973-977.
- 还没有人留言评论。精彩留言会获得点赞!