一种海量高铁轴温数据的分布式时间序列模式检索方法与流程
本发明涉及时间序列分析
技术领域:
,尤其涉及一种海量高铁轴温数据的分布式时间序列模式检索方法。
背景技术:
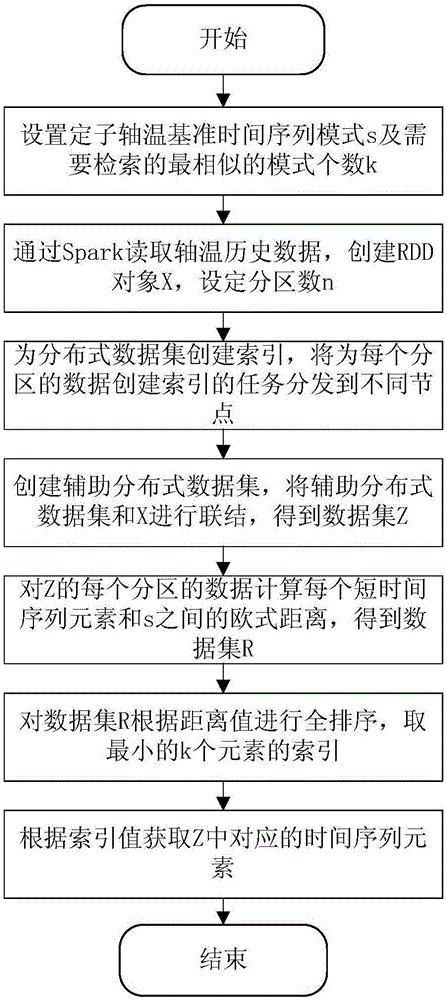
:时间序列是一种和时间相关联、具有先后次序的数值序列或符号序列,在金融、气象、故障诊断等领域应用非常广泛。高铁轴温数据作为高铁日常运维数据的重要组成部分,具有典型的时间序列特征,对时间序列的分析处理也是目前高铁故障诊断研究的一个重要方向,包括异常模式的检索、模式挖掘、聚类等。由于高铁轴温传感器数量多、采集频率快,因此高铁轴温数据具有数据量大、维度高、更新频率高等特点,即具有典型的大数据特征。因此如何对高铁海量轴温数据组成的庞大的时间序列的高效处理,是目前需要研究和待解决的问题。时间序列的相似模式检索问题可描述为给定某时间序列模式,从一个大型的时间序列中找出与之最相似的若干子序列,时间序列相似性检索是其他时间序列分析任务实现的前提,比如异常检测和模式识别等。目前的时间序列相似模式检索方法主要采用单机方法对时间序列进行串行的检索,找出相似性符合要求的所有子序列模式。但是由于机器性能的限制,单机方法能够处理的数据量有限,且计算的效率低下,难以满足海量轴温时间序列数据的检索需求。目前大数据和云计算的发展,使得数据的分布式并行计算成为了可能,极大的提高了数据处理的能力和效率,为海量轴温时间序列数据的分析问题提供了解决的思路。为了提高海量轴温时间序列数据的检索效率,需要研究分布式的时间序列相似模式检索方法。技术实现要素:本发明要解决的技术问题是针对上述现有技术的不足,提供一种海量高铁轴温数据的分布式时间序列模式检索方法,使用分布式计算节点组成的大数据处理集群,通过将数据分发到集群不同节点的内存中,当集群运行计算任务时,将计算任务分解分发到不同的节点,从而实现时间序列相似模式的并行检索。为解决上述技术问题,本发明所采取的技术方案是:一种海量高铁轴温数据的分布式时间序列模式检索方法,包括以下步骤:步骤1、设置检索的轴温数据基准时间序列模式s,确定检索模式的长度m,设定需要检索的最相似的模式个数为k;所述轴温数据为高铁的轴承温度数据,采样周期为1s;所述基准时间序列模式是在轴温数据中自定义选取的一个连续时间段的数据,长度为m;步骤2、将待检索的海量历史轴温时间序列数据读取进分布式系统计算节点的内存中,构造初始分布式数据集x,并确定并行计算任务的个数n,具体包括以下步骤:步骤2.1、将保存在硬盘存储介质中的历史轴温数据通过网络上传至分布式文件系统hdfs(hadoopdistributedfilesystem)中;步骤2.2、使用分布式spark计算引擎读取存储在hdfs的海量轴温时间序列数据;步骤2.3、设置要创建的分布式数据集的分区个数为n,spark计算引擎根据设定的分区数将存储在hdfs上的轴温数据切分出n个数据块,为每个数据块创建一个分区,构造出分区数为n的分布式数据集rdd(resilientdistributeddataset,即弹性分布式数据集)对象x,x的每个元素为某一时刻的轴温数据值,并且x维护着分区的顺序及每个分区首个元素在整个数据集中的偏移量;步骤2.4、根据分区数确定并行计算任务个数为n,spark计算引擎为rdd对象x的每个数据分区创建一个计算任务分发到不同计算节点,任务之间相互独立,每个任务并行处理一个分区的数据;步骤3、为步骤2中分布式数据集x构建索引,根据时间顺序对数据集x中的每个元素从0开始编号,其中每个分区的编号任务是在不同节点并行进行计算的;数据集x中的每个元素转换为<key,value>键值对记录形式,其中,key为索引编号,value为对应时刻的轴温时间序列数值;步骤4、根据基准时间序列模式的长度构造m-1个辅助分布式数据集yj,其中j∈(1,m-1),将步骤3中分布式数据集x和辅助分布式数据集进行联结,构造出每个元素是一个长度为m的短时间序列的分布式数据集z,具体步骤包括:步骤4.1、根据设定的基准时间序列模式的长度m,构造出m-1个和步骤3中数据集x相同的辅助分布式数据集yj,其中j∈(1,m-1);步骤4.2、对m-1个辅助分布式数据集yj构建索引,其中yj的元素从-j开始编号;步骤4.3、对分布式数据集x依次和m-1个辅助分布式数据集yj进行笛卡尔积操作,并将进行笛卡尔积的两个分布式数据集中具有相同索引key值的元素进行联结;步骤4.4、经过步骤4.3之后,从步骤3中的数据集x构造出分布式数据集z,z的元素为<key1,(value1,value2,...,valuem)>形式,其中,key1为元素的编号,(value1,value2,...,valuem)代表一段以第key1个时刻开始长度为m的短时间序列;步骤5、通过spark计算引擎创建计算任务,每个计算任务的逻辑是计算基准时间序列模式和每个数据分区的元素之间的欧式距离,将每个计算任务分发到分布式系统中的若干节点并行计算,构造出分布式数据集r,具体步骤包括:步骤5.1、通过spark计算引擎为步骤4.4中数据集z的每个数据分区创建一个计算任务,每个计算任务完成的逻辑都是将基准数据序列s和该数据分区的每个元素代表的短时间序列l计算欧式距离;步骤5.2、通过分布式spark计算引擎调度步骤5.1中创建的计算任务,将计算任务分发到数据分区所在的计算节点,每个计算任务处理其所在节点的分区数据;步骤5.3、创建分布式数据集r,数据个数和数据集z相同,其元素为<keyr,valuer>键值对形式,keyr为元素编号,valuer为z的每个元素和基准时间序列之间的计算得出的欧式距离数值;步骤6、对步骤5.3中的分布式数据集r根据欧式距离值进行全排序,取距离最小的前k个元素,并返回每个元素的索引,其具体步骤包括:步骤6.1、通过spark计算引擎对分布式数据集r的每个分区的数据根据元素的value进行并行计算排序,取每个分区最小的k个元素;步骤6.2、将r的n个分区求得的n×k个元素收集到分布式系统中的一个节点上,进行汇总排序,取最小的k个元素,并记录计算得到的元素的索引值;步骤7、根据步骤6得到的索引取得步骤4中数据集z中相应的元素,即得到了海量轴温历史时间序列数据集中与基准时间序列最相似的k个子时间序列。采用上述技术方案所产生的有益效果在于:本发明提供的一种海量高铁轴温数据的分布式时间序列模式检索方法,在利用分布式spark计算引擎和分布式文件系统hdfs的基础上,对海量高铁轴温时间序列数据组成的分布式数据集进行重新组织变换,将高铁轴温数据组成的分布式数据集的每个元素转换成相互独立并且保持时间顺序的短时间序列,通过spark计算引擎可以对每个数据分区创建一个计算任务分发到分布式系统的不同计算节点进行计算。从而可以实现时间序列的并行相似性检索效果,解决单机无法处理的海量高铁轴温时间序列的相似性检索问题,提高海量轴温时间序列数据的相似性检索效率。附图说明图1为本发明实施例提供的一种海量高铁轴温数据的分布式时间序列模式检索方法的流程图;图2为本发明实施例提供的时间序列检索效果图。具体实施方式下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。高铁轴温数据是典型的时间序列数据,本实施例以某铁路局采集的高铁定子轴温数据为例,采用本发明的面向海量高铁轴温数据基于spark的并行时间序列相似模式检索方法对该时间序列的相似模式进行检索。高铁定子轴温数据为安装在高铁定子端的轴温传感器采集到的温度数据,本实施例中使用的历史轴温的数据量为20gb,数据记录条数为213002710,采样周期为1s,数据内容包括采集时间和该时刻的轴承温度值,部分数据如表1所示。表1部分高铁定子轴温数据由于历史轴温数据量大,这里只列出部分定子轴温数据用以说明高铁定子轴温数据的形式。一种面向海量高铁定子轴温数据基于spark的并行时间序列检索方法,如图1所示,包括以下步骤:步骤1、设置检索的轴温数据基准时间序列模式s,选取第160个数据为起始点,长度m为12的连续数据作为基准时间序列模式,基准时间序列模式s的数据为[103,103,105,105,110,159,144,127,116,116,117,113],设置检索的最相似的模式个数k为2;时间序列模式检索的任务是在海量的轴温历史数据表示的大型时间序列中查找和基准时间序列模式最相似的若干个长度为m的子时间序列;步骤2、将待检索的高铁定子轴温历史时间序列数据读取进分布式计算节点的内存中,构造分布式数据集x,设置并行计算任务个数n为10。具体包括以下步骤:步骤2.1、首先将保存在硬盘存储介质中的高铁定子轴温历史数据通过网络上传到分布式文件系统hdfs中;步骤2.2、使用分布式spark计算引擎读取存储在hdfs上的高铁定子轴温数据;步骤2.3、在spark读取定子轴温数据的时候设置数据分区个数为10,spark计算引擎根据数据分区的个数将读取到的定子轴温数据切分为10个数据块,这些数据分区组成了分布式数据集合rdd对象x,x的数据分区形式为{partition1,partition2,...,partition10},其中每个partition代表一个数据分区,分区之间具有时间上的顺序性。本实施例中,以partition1的数据说明分区内部的数据形式,分区partition1的轴温记录条数为20001036条,partition1的内部数据形式为{x1,x2,...,x20001036},xn代表定子轴温的数值,分区的元素按照时间顺序排列,其他分区的形式和partition1相同。步骤2.4、spark计算引擎根据设定的rdd对象的数据分区个数,为每个数据分区创建一个计算任务,将计算任务分发到分布式系统中的不同节点,一个任务只处理其对应的数据分区的定子轴温数据;步骤3、为步骤2中定子轴温数据组成的分布式数据集x构建索引,根据时间顺序,对x的元素从0开始进行编号,数据集x的每个分区的数据转换成{<index,x1>,<index+1,x2>,...,<index+n-1,xn>}其中,index为该分区的首个元素相对于整个数据集的偏移量,n为该分区的数据记录条数,为分布式数据集的每个元素创建一个索引,每个分区的元素索引的创建是在不同节点独立完成的。本实施例以分区partition1为例说明数据的转换逻辑,构建索引之后,分区partition1的数据形式转换为{<0,x1>,<1,x2>,...,<20001035,x20001036>}其他分区的数据形式和partition1相同。步骤4、根据基准时间序列s的长度,构造出11个和步骤3中的x相同的分布式数据集yj,其中j∈(1,11),将分布式数据集x和辅助分布式数据集进行联结,构造出每个元素是一个长度为12的短时间序列的分布式数据集z。步骤4.1、构造出11个和步骤3中数据集x相同的分布式数据集yj,其中j∈(1,11);步骤4.2、对步骤4.1中的11个辅助分布式数据集构建索引,对于yj来说,对其所有的元素的索引都减去j,即转换之后其首元素的索引为-j,以y1为例,其首元素的索引为-1,其他元素的索引以此类推递增;步骤4.3、对步骤3中的数据集x和11个辅助分布式数据集进行笛卡尔积操作,对进行笛卡尔积操作的任意两个数据集,保留两个数据集中具有相同索引的元素进行联结。两个集合的笛卡尔积数学表达式为a×b={(x,y)|x∈a∧y∈b}其中,a和b表示两个数据集合,x和y分别表示a和b中德任意元素,(x,y)表示两个集合进行笛卡尔积计算之后得到的集合中的元素形式。两个数据集中具有相同索引的两个元素<key,value1>和<key,value2>进行联结之后的结果为<key,(value1,value2)>。本实施例以x和y1的联结为例说明联结的逻辑,x和y1中索引为同为10的元素分别为<10,99>和<10,100>,两个元素联结之后的结果为<10,(99,100)>,其他元素的联结与此类似。步骤4.4、经过步骤4.3之后,构造出分布式数据集z,z的每个元素变为<key,(value1,value2,...,value12)>其中,key为元素的索引,从0开始编号,value转换为长度为12的短时间序列。本实施例以z中第160个元素,即索引为159的元素说明z中数据的形式,z中索引key为159的元素形式为<159,(103,103,105,105,110,159,144,127,116,116,117,113)>步骤5、通过spark计算引擎调度计算任务,为步骤4.4中数据集z的10个分区创建10个计算任务,将10个计算任务分发到分布式系统的5个节点进行并行计算。具体步骤包括:步骤5.1、通过spark计算引擎为步骤4.4中数据集z的10个数据分区分别创建一个计算任务,每个计算任务完成的逻辑都是将基准数据序列s和数据集z的每个分区的长度为12的短时间序列元素计算欧式距离;对于两个k维向量s(x11,x12,...,x1k)和l(x21,x22,...,x2k)之间的欧式距离为:步骤5.2、通过分布式spark计算引擎调度步骤5.1中创建的计算任务,将计算任务分发到数据分区所在的计算节点,每个计算任务处理其所在节点的分区数据;步骤5.3、创建分布式数据集r,数据个数和数据集z相同,其元素为<keyr,valuer>键值对形式,keyr为元素编号,valuer为z的每个元素和基准时间序列之间的计算得出的欧式距离数值。本实施例中,构造的分布式数据集r中分区数同样为10,r中的数据元素形式如表2所不:表2分布式数据集r的部分数据形式步骤6、对步骤5.3创建的分布式数据集根据欧式距离的值进行全排序,取值最小的前2个元素,得到其索引值。具体步骤包括:步骤6.1、通过spark计算引擎为步骤5.3中数据集r的每个分区创建一个计算任务,分发到5个节点计算。计算每个分区元素值最小的2个元素,记录其索引值;步骤6.2、将步骤6.1中计算得到的2×10个局部最小元素通过spark计算引擎收集到分布式系统的主节点上,进行汇总排序,计算得到全局最小的2个元素,记录其索引值;步骤6.3、根据步骤6.2中计算得到的2个索引值,获取步骤4.4中数据集z中相应索引对应的元素值,即为与基准时间序列s最相似的2个子时间序列。本实施例中根据基准时间序列s在轴温历史数据中检索到的最相似的两个子时间序列分别为起始索引为401和95,检索结果如表3所示:表3相似模式检索结果索引欧式距离轴温时间序列数值7036.318{105,105,112,117,122,121,178,132,116,113,115,111}40138.716{106,107,107,108,108,119,128,136,112,110,110,111}检索方法的效果如图2所示,其中图中矩形线框标识的数据为定子轴温基准时间序列模式,椭圆形线框标识的数据为在定子轴温历史时间序列中检索出来的最相似的2个子时间序列模式。最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1