一种多层卷积特征自适应融合的运动目标跟踪方法与流程
本发明公开了一种多层卷积特征自适应融合的运动目标跟踪方法,属于计算机视觉领域。
背景技术:
运动目标跟踪是计算机视觉领域的一个重要研究方向,它在军事和民用方面都有着十分广泛的应用,例如战场监视、智能交通系统、人机交互等。
自从2012年alexnet在图像分类工作中取得巨大成功以来,一系列cnn(convolutionalneuralnetwork,cnn)框架不断刷新纪录。相较与alexnet,vggnet最大的改进就是用多个3×3(3×3是能够捕获上下左右和中心概念的最小尺寸)的卷积核代替一个大尺寸卷积核,增强了网络泛化能力,top-5错误率减少到7.3%。在vot2017挑战赛上有人将vggnet换成网络更深的googlenet和resnet,但是性能方面并没有得到很大提升;在计算机视觉竞赛ilsvrc上,和以上几种网络相比,vggnet在定位方面获得第一名,所以可以采用vggnet网络提取特征。
自bolme等人提出误差最小平方和算法以来,相关滤波跟踪算法层出不穷,一些基于手工特征(hog、colorname)的相关滤波算法在目标快速跟踪方面表现出优异的性能,但是对于目标发生的剧烈形变、遮挡或出现相似物体干扰等各种复杂的情况,缺少目标语义信息的手工特征不能达到很好的鲁棒性。在相关滤波算法中,特征是决定跟踪效果的重要因素之一,特征的进一步发展就是卷积特征。一些跟踪算法利用vggnet网络提取卷积特征以全卷积层的输出作为特征提取层,全卷积层与语义信息密切相关,对于高级视觉识别问题是有效的,但是视觉跟踪的目的是精确定位目标,不是推断它们的语义类,仅使用全卷积层的特征无法精确定位目标。
技术实现要素:
本发明要解决的技术问题是提供一种多层卷积特征自适应融合的运动目标跟踪方法,用以解决传统手工特征如梯度方向直方图特征(histogramoforientedgradient,hog)、颜色特征(colorname,cn)无法全面的表达目标,这些特征难以捕捉目标的语义信息,对形变、旋转等复杂外观变化没有良好的鲁棒性,在不同场景下跟踪性能差异较大的缺陷,并且能够根据可靠性判断依据apce计算每层卷积层的权重,提高了跟踪精度。
本发明采用的技术方案是:一种多层卷积特征自适应融合的运动目标跟踪方法,方法将目标跟踪中采用传统手工特征的方法改进为卷积特征,并对目标尺度进行估计。首先在第一帧图像中,初始化目标区域,利用已训练好的深度网络框架vgg-19提取目标区域的第一和第五层卷积特征,通过相关滤波器学习训练得到两个模板;其次在下一帧,以上一帧目标的预测位置和尺度大小提取检测样本特征,并和上一帧的两个模板进行卷积,即得到两层特征的响应图;然后对所得到的响应图(responsemap)依据apce(averagepeaktocorrelationenergy)测量方法计算权重,自适应加权融合响应图来确定目标的最终位置;确定位置后通过提取目标多个尺度的方向hog特征估计目标最佳尺度。
所述方法的具体步骤如下:
step1、初始化目标并在其所在的图像中选取目标区域;具体为以目标所在位置为中心,采集一个尺寸为目标2倍大小的图像块作为目标区域。
step2、利用已训练好的vgg-19网络提取目标区域的第1层和第5层卷积特征作为训练样本,用训练样本训练得到对应的位置滤波器模板;
使用在imagenet上训练得到的vgg-19网络提取目标区域的第1层和第5层卷积特征,设p表示卷积特征图,f表示采样特征图,采样特征图f中第i个位置的特征向量为fi:
其中aij为权重,pj表示卷积特征图中第j个位置的特征向量,通过建立最小化损失函数训练最优滤波器:
其中g表示滤波器h的期望输出,λ为正则化系数,l表示维度,l∈{1,…,d},fl表示在第l维的采样特征,*表示循环相关,将上式转换到频域求解得到频域在第l维的滤波器hl:
其中,hl、g、f分别为hl、g、f的频域描述,
step3、在新一帧图像的目标区域中提取两层卷积特征得到两个检测样本,分别计算两个检测样本与前一帧图像的目标区域中训练得到的位置滤波器的相关得分,即得到两层特征的响应图;
在新一帧的目标区域提取卷积特征作为检测样本z,计算与步骤2训练得到滤波器的相关得分y,即得到该特征的响应图:
5、根据权利要求1所述的多层卷积特征自适应融合的运动目标跟踪方法,其特征在于:所述step4的具体步骤为:
对step3中的图像分别计算第1层和第5层卷积特征响应图的apce(averagepeaktocorrelationenergy,平均峰值与相关能量),设图像为第t帧,
fmax,表示响应图y中最高的响应分数,fmin表示响应图y中最小的响应分数,fm,n表示响应图y中第m行,第n列的响应分数;mean表示对括号内所有累加数求均值;
对每层响应图的apce归一化[0,1],计算权重值得到w1、w2;
对两层卷积响应进行特征融合得到响应值yt:
yt=w1×yt,1+w2×yt,2
计算yt的最大值,得到目标在第t帧的最终位置。
step4、依据apce测量方法计算两层特征响应图的权重值,加权融合两层特征的响应图,选取最大值作为目标当前位置;
step5、确定位置后,以当前位置为中心,截取图像不同尺度的样本特征,通过hog特征构建尺度金字塔训练尺度滤波器,获取尺度响应最大值为目标当前尺度;
确定目标位置后,以目标新位置为中心,截取图像不同尺度的样本特征,以p×r表示当前帧的目标大小,aqp×aqr为尺度提取样本,
在下一帧中,以上述方法截取不同尺度的图像块,组成新的特征,通过步骤step3中相同的方法和尺度滤波器hs得到ys的值,ys为两层特征融合得到的响应值,ys中最大值对应的尺度为最终尺度估计的结果。
step6、更新尺度滤波器;
对尺度滤波器hs进行更新的公式为:
其中η表示学习率,每一帧图像中尺度滤波器都进行更新,式中
step7、更新位置滤波器;
位置滤波器进行更新的公式为:
式中
step8、重复步骤3至7直到目标跟踪结束。
本发明的有益效果是:
1、使用多层卷积特征自适应融合的运动目标跟踪方法
传统手工特征如梯度方向直方图特征(hog)、颜色特征(cn)对目标细微形变、光照变化等有较好的适应能力,但是这些特征难以捕捉目标的语义信息,对形变、旋转等复杂外观变化没有良好的鲁棒性,容易造成模型漂移导致跟踪失败。在相关滤波算法中,特征是决定跟踪效果的重要因素之一,特征的进一步发展就是卷积特征,卷积特征能够更好地表达目标外观。
2、使用多层卷积特征表达目标外观
一些跟踪算法利用vggnet网络提取卷积特征以全卷积层的输出作为特征提取层,全卷积层与语义信息密切相关,对于高级视觉识别问题是有效的,但是视觉跟踪的目的是精确定位目标,不是推断它们的语义类,仅使用全卷积层的特征无法精确定位目标。本发明提取第一和第五卷积层作为输出,cnn的高层(例如layer5)特征包含更多的语义特性,对旋转和形变等外观变化具有不变性,能够处理较大的目标变化以对目标进行范围定位,但是空间分辨率较低,对平移和尺度都有不变性,无法精确定位目标;而低层(例如layer1)特征包含了纹理和颜色等丰富的细节信息,空间分辨率高,适合高精度定位目标,准确性很强,但是不变性较差。两层特征在目标定位时互补。
3、使用可靠性判断依据计算权重值
给目标响应分配固定权重值对测试序列不具有普遍性,需要做大量实验找到合适的权重值。本发明使用了apce方法自适应融合响应具有可靠性,节省了大量实验时间。
4、通过构建尺度金字塔训练尺度滤波器估计目标尺度
运动过程中目标尺度大小是变化的,当跟踪框是固定大小时,遇到目标变大的情况,只能获取目标的局部信息,目标变小时,跟踪框里出现干扰的背景信息,影响算法的跟踪精确度。为解决这一问题,本发明通过构建尺度金字塔训练尺度滤波器估计目标尺度,跟踪框随着目标尺度的大小变化,极大地减少了在目标跟踪过程中因固定跟踪框带来的错误信息。
总结:多层卷积特征自适应融合的运动目标跟踪方法在相关滤波算法的跟踪框架上融合了多层卷积特征的属性信息,根据高低卷积层的互补特性,很好的表达了目标外观。依据apce计算权重,每层响应图自适应融合以确定最后的位置,提高跟踪精度。其次通过构建尺度金字塔自适应的更新目标尺度。
附图说明
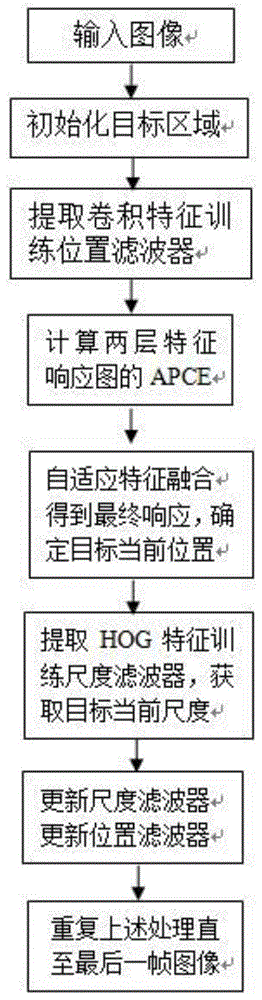
图1为本发明方法的流程图;
图2中(a)表示目标采样图;(b)为第1层卷积特征的响应图;(c)为第5层卷积特征的响应图;(d)为融合后的响应图。
具体实施方式
下面结合附图和具体实施例,对本发明作进一步的说明。
实施例1:如图1所示,一种多层卷积特征自适应融合的运动目标跟踪方法,所述方法的具体步骤如下:
step1、对输入图像初始化目标并选取目标区域,先对第一帧图像进行处理,以其目标位置为中心,采集一个尺寸为目标2倍大小的图像块;
step2、利用已训练好的深度网络框架vgg-19提取目标区域的第1和第5层卷积特征作为训练样本,用训练样本训练位置滤波器模板。
step3、对第二帧图像的目标区域中提取两层卷积特征得到两个检测样本,分别计算两个检测样本与第一帧中训练得到的位置滤波器的相关得分,即得到两层特征的响应图。
step4、依据apce测量方法计算两层特征响应图的权重值,加权融合两层特征的响应图,选取最大值作为目标当前位置;
step5、确定位置后,以当前位置为中心,截取图像不同尺度的样本特征,通过hog特征构建尺度金字塔训练尺度滤波器,获取尺度响应最大值为目标当前尺度;
step6、更新尺度滤波器;
step7、更新位置滤波器;
step8、重复步骤3至7直到跟踪结束,即对第三帧图像直至视频最后一帧图像做步骤3-7相同的处理。
实施例2:下面以具体的视频处理来说明,step1、根据所述输入图像第一帧,以目标位置为中心,采集一个尺寸为目标2倍大小的图像块,如图2(a)所示。
step2、使用在imagenet上训练得到的vgg-19网络提取目标的卷积特征。随着cnn的前向传播,加强了不同类别物体之间的语义区分,同时也降低了可以用来精确定位目标的空间分辨率。例如,输入图像大小为224×224,而第5池化层(poollayer)的全卷积特征输出尺寸为7×7,是输入图像尺寸的1/32,这种低空间分辨率不足以准确地定位目标,为了解决以上问题,我们将第1和第5层的卷积特征通过双线性插值到样本尺寸以精确估计位置。设p表示卷积特征图,f表示采样特征图,第i个位置的特征向量fi为:
其中权重aij取决于i和相邻特征向量j的位置,pj表示卷积特征图中第j个位置的特征向量,特征f的大小为mxnxd,m,n,d分别表示特征的长宽和通道数。通过建立最小化损失函数(2)式训练最优滤波器:
其中g表示滤波器h的期望输出,λ为正则化系数,λ=1.28,l表示特征的某一维度,l∈{1,…,d},fl表示在第l维的采样特征,*表示循环相关,傅里叶变换能够大大提高卷积运算的速度,所以可以转换到频域快速求解。对(2)式求解得到频域在第l维的滤波器hl:
式中,hl、g、f分别为是hl、g、f的频域描述,
step3、上述计算方法得到位置滤波器,完成了位置滤波器的训练过程。此处对目标进行检测,在新一帧的目标区域提取卷积特征作为检测样本z,计算与步骤2训练得到滤波器h的相关得分y,即得到该特征的响应图:如图2(b)、2(c)所示:
step4、在t帧时,分别计算第1和第5卷积特征响应图的apce:
fmax,,fmin,,fm,,n分别表示每层响应图y中最高、最小和在第m行,第n列的响应分数;mean表示对括号内所有累加数求均值。
对每层响应图的apce归一化[0,1],计算权重值得到w1、w2。
在t帧,我们使用一种自适应融合的方法对两层卷积响应进行特征融合得到响应值yt,如图2(d)所示。
yt=w1×yt,1+w2×yt,2(6)
计算yt的最大值,得到目标在第t帧的最终位置。
step确定目标位置后,以目标新位置为中心,截取图像不同尺度的样本特征。以p×r表示当前帧的目标大小,aqp×aqr为尺度提取样本,
在下一帧中,以上述方法截取不同尺度的图像块,组成新的特征,通过公式(4)和尺度滤波器hs相关进而得到ys的值(求取方法和位置估计类似),ys中最大值对应的尺度为最终尺度估计的结果。
step6、对尺度滤波器进行更新,更新公式为:
其中η表示学习率以赋予滤波器历史“记忆”,η=0.0075。每一帧中尺度滤波器都进行更新,式中
step7、以固定学习率η对位置滤波器进行更新,更新公式为:
式中
step8、算法运行至此,第t帧运行结束,目标位置、尺度以及所有滤波器都已经更新完成,下一帧重复运行步骤3至7至视频结束。
为了验证与使用了传统手工特征的相关滤波算法dsst、kcf、cn和同样使用卷积特征的算法hcf相比,本发明方法针对目标在跟踪过程中发生的的快速运动(blurowll、bolt2、jumping),遮挡(shaking、coke),形变(skiing),旋转(motorolling、skiing),光照变化(shaking、motorolling)等复杂情况仍变现良好,在20组视频序列上对几种方法进行对比实验,表1为对5种算法的整体性能分析。
表120个视频序列的平均cle、dp、op
表中加粗的数据表示最优的结果,本发明采用中心位置误差cle(centerlocationerror),距离精度dp(distanceprecision),重叠精度op(overlapprecision)为评价指标。cle为跟踪目标中心点的位置与场景中真实目标中心位置的误差,用欧式距离表示,误差越小,位置越准确;dp为目标中心位置和真实位置的欧氏距离误差小于一定阈值的帧数的百分比。当某一帧跟踪器预测的目标框和真实位置的目标框重叠率ol高于一定的阈值时,则认为该帧跟踪成功。从表1的各项指标可以看出,本发明算法跟踪鲁棒性综合最优。表2,表3为基于部分视频序列的分析。
表25种算法在8个视频中的cle对比
表35种算法在8个视频中的dp对比
由表2、表3可以看出,在carscale序列的测试结果表明:与同样使用了尺度估计的dsst算法相比,本发明(使用了卷积特征)更加鲁棒。并且对于跟踪过程中目标遇到的快速运动(blurowll、bolt2、jumping),遮挡(shaking、coke),形变(skiing),旋转(motorolling、skiing),光照变化(shaking、motorolling)等复杂情况变现良好。
- 还没有人留言评论。精彩留言会获得点赞!