一种基于雷达仿真图像的卷积神经网络人体动作分类方法与流程
本发明属于雷达目标分类与深度学习领域,涉及应用雷达进行人体动作分类的问题。
背景技术:
在人们在与外界进行交互的过程中,除了通过语音交流,还常常借助肢体语言,即通过动作行为传递信息。人体动作分类在许多领域具有广泛的应用场景,例如智能监控、人机交互、虚拟现实、体感游戏、医疗监护等。当前对人体动作识别的研究大多集中于基于视觉的识别,其核心是通过计算机对传感器采集的原始图像或图像序列数据进行处理和分析,学习并理解其中人的动作和动作。然而,不同的光照、视角和背景等条件会使相同的人体动作在姿态和特性上产生差异。此外,还存在人体自遮挡、部分遮挡、人体个体差异、多人物识别对象等问题,这些都是现有的基于视觉方法的人体动作分类方案难以突破的瓶颈。
雷达探测人体有着其他传感器所不具备的优势:首先是其探测距离远;其次,雷达不易受到天气、光线、温度等环境因素的影响;最后,雷达具备穿透墙壁等障碍物的能力,可对障碍物后的人员实施探测。目前,雷达人体探测在很多应用中得到了长足的发展,如无人机、无人车环境感知、医疗患者监护、火灾或地震幸存者搜救、巷战敌情态势感知、反恐行动中恐怖分子探测等,具有十分广阔的应用前景。
雷达人体动作分类是指使用模式识别、机器学习等方法,从雷达信号中自动地分析出人体动作。基于雷达时频图像的人体动作识别是近年发展起来的新技术,经人体运动调制后的雷达回波信号包含了人体各部分微动调制产生的多普勒频率,回波通过时频变换生成图像并将之应用于人体目标的参数估计和运动辨识中,使得基于雷达时频图像的人体动作分类成为可能。传统的雷达人体动作分类方法主要依赖于对时频图像中人体微多普勒特征的人工提取。而作为图像识别中应用最广泛的深度学习模型,卷积神经网络(convolutionalneuralnetwork,cnn)最重要的特点就是能够自动地学习图像中的特征并完成对图像的分类识别。基于cnn的雷达人体动作分类涉及计算机视觉、机器学习、人工智能和雷达信号处理等众多领域的研究,是一个多学科交叉融合的研究方向,具有非常重大的学术价值与社会意义。
[1]胡琼,秦磊,黄庆明,"基于视觉的人体动作识别综述,"计算机学报,vol.36,p.2512-2524,2013.
[2]v.c.chen,f.li,s.-s.ho,andh.wechsler,"micro-dopplereffectinradar:phenomenon,model,andsimulationstudy,"ieeetransactionsonaerospaceandelectronicsystems,vol.42,pp.2-21,2006.
[3]s.s.ram,c.christianson,y.kim,andh.ling,"simulationandanalysisofhumanmicro-dopplersinthrough-wallenvironments,"ieeetransactionsongeoscienceandremotesensing,vol.48,pp.2015-2023,2010.
技术实现要素:
本发明提供一种基于雷达仿真图像的卷积神经网络人体动作分类方法,利用深度学习中的卷积神经网络实现了对雷达图像中人体动作的“端到端”分类,简化了人工提取图像特征的复杂过程,极大地减少了人体动作分类的工作量。为使本发明的技术方案更加清楚,下面对本发明具体实施方式做进一步地描述。
一种基于雷达仿真图像的卷积神经网络人体动作分类方法,包括下列的步骤:
1)建立包含多种人体动作的时频图像数据集:选用mocap数据集进行雷达图像仿真,利用mocap数据集中的人体动作测量数据构建人体目标运动学模型并用于雷达时频图像仿真,建立基于椭球体的人体动作模型,得到人体目标雷达回波,对回波使用时频变换进而生成雷达时频图像,建立包含多种人体动作的时频图像数据集;
2)雷达时頻图像数据增强:对所得到的雷达时頻图像沿时间轴利用滑窗法截取,以产生足够多的数据用于卷积神经网络的训练,将截取生成的雷达图像分为训练集和测试集,完成数据集的构建。
3)建立卷积神经网络模型:以手写体识别网络lenet为基础,在其3个卷积层、2个池化层以及2个全连接层的基础上,引入修正线性单元relu替换原来的sigmoid激活函数作为卷积网络的激活函数,并增加一个池化层,减少一个全连接层,构成卷积神经网络结构,该结构包含3个卷积层、3个最大池化层和1个全连接层,调整网络的层间结构和层内结构及训练参数以达到更好的分类效果;
4)训练卷积神经网络模型:利用2)中生成的数据集对3)中网络结构的各层权重进行训练,通过随机抽取数据集中的图像,分批次将其输入网络,通过梯度下降法更新每次迭代后学习到的权重,经过多次迭代后网络各层权重得到充分优化,最终得到可用于基于雷达图像人体动作分类的卷积神经网络模型。
本发明利用卷积神经网络的算法,设计一种基于仿真雷达图像的人体动作分类系统。该系统以基于mocap数据集生成的仿真雷达多普勒图像为研究对象,包括数据集的制作、卷积神经网络模型的建立、训练和测试。本系统利用雷达信号的特点,可以完成不同环境、光照强度及天气情况下的人体动作分类任务,且利用卷积神经网络提高了分类的准确率实现更加智能、高效的分类。
附图说明
图1本实验卷积神经网络模型结构示意图
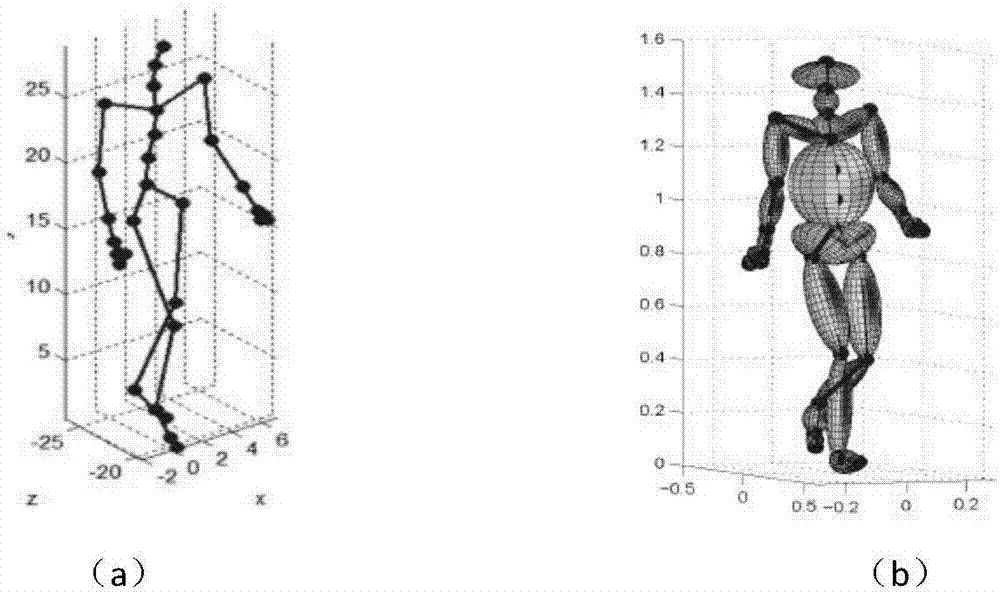
图2(a)人体关节点图;(b)基于椭圆体的人体模型图
图3(a)mocap数据库中骨骼运动轨迹;(b)该轨迹相应的生成雷达谱图
图4本实验模型(a)与lenet分类效果(b)对比图
具体实施方式
为使本发明的技术方案更加清楚,下面对本发明具体实施方式做进一步地描述。本发明按以下步骤具体实现:
1.雷达时频图像数据集构建
(1)基于mocap数据集的雷达图像仿真
motioncapture(mocap)数据集由cmu的graphicslab实验室建立,使用vicon动作捕捉系统捕捉真实的动作数据,该系统由12个mx-40红外相机组成,各相机帧率为120hz,可以记录被试者身上的41个标记点,通过整合不同相机记录下的图像可以得到被试者骨骼的运动轨迹。该数据集包含2605组实验数据,本实验过程中选择其中七种常见的动作用来生成雷达图像,这七种动作分别为:跑步、行走、跳跃、爬行、匍匐前进、站立和拳击。
接着构建基于椭球体的人体动作模型,该模型使用31个关节点来对人体进行建模(如图2(a)所示),每两个相邻关节点定义了一个体节,所有的体节在雷达的各扫描角度均为可见的,在此我们忽略不同人体部位的阴影效应。每个体节近似于一个长椭球体,如下式所示:
式中,(x0,y0,z0)表示两个关节点连线中点的坐标,(a,b,c)是半轴的长度,且b=c。椭球体的体积定义为:
假设椭球体体积和一个半轴a的长度已知,则可计算出b的长度,雷达目标有效截面(rcs)可以利用传统的椭圆rcs公式计算得到。通过椭球体模型建立的人体目标模型如图2(b)所示,整个人体可以看作是由多个椭圆体组合而成的,各部分的雷达反射波振幅可以由近似为椭圆形的rcs得到,将各部分的人体回波连续相加即可得到人体的整体回波,接着使用短时傅里叶变换将回波转化为雷达谱图。图3显示的是mocap数据库中的人体骨骼运动轨迹与生成的相应的雷达谱图。
(2)基于滑窗法的雷达图像数据增强
由雷达图像数据难获取、生成成本高的而引起的数据缺乏的问题可以通过数据增强的方法解决。本实验根据雷达图像的特点,采用“滑窗法”的数据增强手段,具体方法为:在生成的雷达图像上使用固定长度的标准时间窗,沿时间轴连续地截取整个雷达谱图,这样一张雷达谱图可以被截取为多个可供训练的图片。通过这种方法,对于分类任务中每个动作均可获得大小为500张图片的数据集,本实验将每个动作的数据集分为两个部分,分别为400张训练图片和100张测试图片。
2.基于卷积神经网络的人体动作分类模型构建
(1)基础卷积神经网络模型构建
通过研究lenet、alexnet、googlenet、vggnet等几种典型神经网络结构在本实验数据集上的测试效果,根据多次实验及经验数据,选取lenet作为基础网络结构并将其识别结果作为基准,lenet是用于手写字体的识别的一个经典卷积神经网络,其包含3个卷积层、2个池化层以及2个全连接层,特征映射函数采用sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。在此基础上,本实验引入了修正线性单元(relu),增加一个池化层,减少一个全连接层,最终提出了适用于本实验的卷积神经网络结构如图1所示。该模型包含3个卷积层、3个池化层和1个全连接层,池化层采用最大值池化的方法,并采用relu作为激活函数有效降低训练结果的过拟合的风险。
(2)卷积神经网络模型优化
卷积神经网络结构包括层深、层宽等参数,不同的网络结构决定了神经网络的特征表示情况,进而影响识别效果。对结构的研究包括层间结构和层内结构两个部分。层间结构包括层深(网络层数)、连接函数(例如卷积、池化、全连接)等;层内结构包括层宽(同层节点数)、激活函数等。针对层间结构,本实验研究了各种不同网络结构作用,首先改变网络层深,分为两步,第一步保持全连接层数量不变,将卷积层的个数从2逐步变化至5,第二步保持卷积层个数不变,将全连接层个数由1逐步变化为5,实验结果如表1。根据实验结果,本实验选择三层卷积层以及一层全连接层的卷积神经网络结构。之后改变输出特征图的个数,分别取值为1、3、20、64、128,实验结果如表2所示,根据实验结果将每层输出的特征图数量确定为20,以获得最佳的分类准确率。
其次改变层内结构中的特征图大小,分别选取大小为3×3、9×9、20×20、48×48、100×100像素的特征图,通过实验比较卷积神经网络模型在生成不同大小的特征图时的分类准确率(如表3所示),可以看出大小为9×9的特征图能够帮助模型得到较高的准确率。
表1
表2
表3
3.雷达人体动作分类卷积神经网络模型训练
神经网络模型的训练过程即为模型学习各层连接权重的过程。在本实验中,首先对各层权重进行高斯初始化,模型通过梯度下降的方法来调整各层参数,每次迭代批处理图片数目为256,即每次从训练集里随机选择256张雷达图片供网络训练,模型基础学习率设定为0.001,在迭代3000次后完成训练过程。本实验所用计算机采用ubuntu系统,利用nvidia公司的gtxtitanxgpu和intel公司的e31231-v3cpu进行训练,此外本实验还采用了cudnn进行gpu计算加速。
4.模型的分类效果测试
测试时,将测试集的雷达图像输入分类模型,启动测试过程,即可查看模型对雷达图像分类效果的好坏。实验过程中分类结果如图4所示,由图可以看出,本实验构建的基于雷达的人体动作分类模型的分类准确率明显优于lenet,lenet对七种动作的平均分类准确率为93.86%,而本实验中模型的平均分类准确率可以达到98.34%,高出lenet约4.5个百分点。
- 还没有人留言评论。精彩留言会获得点赞!