一种RSFQFFT处理器的蝶形运算处理方法及系统与流程
本发明涉及计算机和数字信号处理领域,特别涉及一种rsfqfft处理器的蝶形运算处理方法及系统。
背景技术:
现有技术对于微处理器的设计大都是基于cmos(硅互补金属氧化物)的半导体技术,而缩小集成电路线宽尺寸和增加单位面积晶体管的集成度正是半导体技术领域面临的两大挑战,随着对半导体器件运行可靠性和速度越来越高的需求,集成电路的线宽尺寸也越来越接近原子直径,而这一发展趋势也会在不久的将来导致经济上的不可取。
因此,为了满足未来能源高效的高性能计算机系统的需要,必须找到一种可行的替代技术。rsfq(超导高速单磁通量子)电路因其具有超高运算速度和超低功耗的特性被列为最可能的下一代集成电路,而现有技术中对于rsfq处理器的设计还有待开发。
因此,本发明设计了一种rsfqfft处理器的蝶形运算处理方法及系统。
技术实现要素:
本发明提供一种rsfqfft处理器的蝶形运算处理系统,包括用于执行计算的第一计算模块和第二计算模块,用于执行常数乘法的旋转因子模块和用于改变序列顺序的重排模块;在执行运算时,输入数据经所述第一计算模块执行计算后将获得的第一数据串输入至所述旋转因子模块中执行常数乘法并获得中间结果,所述中间结果经所述重排模块改变序列顺序后,将获得的第二数据串输入至所述第二计算模块执行计算并获得输出数据。
优选的,所述第一计算模块与所述第二计算模块相同,均包括若干个可执行蝶形计算的蝶形计算单元。
优选的,所述蝶形计算单元采用了基于分裂基算法的8点串并体系结构,包括72级流水线,2946个dff(dflip-flop),1968个与门,1128个异或门,144个ndro(non-destructiveread-out),102个非门以及699个cb(融合缓冲)。
优选的,所述蝶形单元包括一个基4蝶形计算单元、两个基2蝶形计算单元和两个分裂基蝶形计算单元。
优选的,所述基4蝶形计算单元包括12个乘法器、11个加法器和11个减法器;所述基2蝶形计算单元包括4个乘法器、3个加法器和3个减法器;所述分裂基蝶形计算单元包括8个乘法器、6个加法器和6个减法器。
优选的,所述旋转因子模块包括21级流水线,14个乘法器和42个dff。
优选的,所述重排块包括8级流水线,128个d2ff和56个dff。
优选的,所述蝶形运算处理系统包括173级流水线,所述输入数据在第1-16个时钟周期被输入,所述输出数据在第174-188个时钟周期被输出。
根据本发明另一个方面,还提供一种利用如上所述蝶形运算处理系统执行运算的方法,包括以下步骤:
步骤0-步骤7,将输入数据输入至所述第一计算模块中执行蝶形计算并输出;
步骤1-步骤8,将所述第一计算模块的输出数据输入至所述旋转因子模块中执行常数乘法运算并输出;
步骤2-步骤9,将所述旋转因子的输出数据输入至所述重排模块中执行序列顺序重排并输出;
步骤3-步骤10,将所述重排模块的输出数据输入至所述第二计算模块;
步骤4-步骤11,所述第二计算模块执行蝶形计算并输出获得的输出数据。
优选的,所述输入数据为64点数据,被分为8串,每串8点分别输入至所述第一计算模块。
相对于现有技术,本发明取得了如下有益技术效果:本发明提供的rsfqfft处理器的蝶形运算处理方法及系统,采用了rsfq电路实现了fft算法中的分裂基算法,相对于传统的cmos电路来说,实现了超高的运算速度和超低的功耗;同时采用了8点串并体系结构,能够连续处理64点数据,增加了处理器的吞吐量并降低了硬件成本,实现了硬件资源消耗与运算延迟的均衡效果。
附图说明
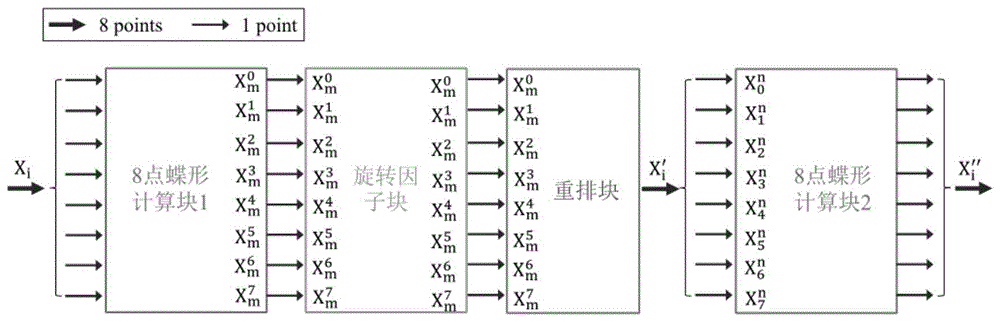
图1是本发明优选实施例提供的8点串并蝶形运算处理系统的示意图。
图2是本发明优选实施例提供的基2蝶形计算单元的示意图。
图3是本发明优选实施例提供的基4蝶形计算单元的示意图。
图4是本发明优选实施例提供的分裂基计算单元的示意图。
图5是本发明优选实施例提供的蝶形计算模块的加法器逻辑门电路。
图6是本发明优选实施例提供的蝶形计算模块的减法器逻辑门电路。
图7是本发明优选实施例提供的旋转因子模块的示意图。
图8是本发明优选实施例提供的重排模块的逻辑门级电路。
具体实施方式
为了使本发明的目的、技术方案以及优点更加清楚明白,以下结合附图,对本发明的实施例中提供rsfqfft处理器的蝶形运算处理方法及系统进一步详细说明。
快速傅里叶变换(fft)算法是数字信号处理中最重要的算法之一,其应用十分广泛,例如,对语音信号的分析和合成,对通信系统中实现全数字化的时分制与频分制(tdm/fdm)的复用转换等等。蝶形运算是指2点离散傅里叶变换(dft)运算,整个fft的运算过程可以由若干级迭代的蝶形运算组成。由于在实际应用中,fft需要在极大的吞吐率下计算,甚至达到在每秒千兆采样的范围,因此很难使用现有的cmos电路来实现高能效的fft处理器。
为此,发明人经研究提出了一种利用rsfq电路实现fft运算的蝶形运算处理方法及系统,不仅能够高速低耗的实现fft的运算过程,还能够满足fft所需的大吞吐率。下面将结合具体实施例进行详细说明。
本发明提供的rsfqfft处理器的蝶形运算处理系统,以能够连续处理64点数据的蝶形运算处理系统为例,在执行运算处理时,将每个数据分成8串,每串8点,以便增加处理器的吞吐量,同时还能够降低硬件成本;其中,每点输入数据长度为4比特,分为2串,每串2比特。
图1是本发明优选实施例提供的8点串并蝶形运算处理系统的示意图,如图1所示,上述运算处理系统包括两个具有相同结构的用于执行蝶形计算的蝶形计算模块1和2,用于执行常数乘法的旋转因子模块和用于改变序列顺序的重排模块。其中,每个蝶形计算模块均包括一个基4蝶形计算单元、两个基2蝶形计算单元和两个分裂基蝶形计算单元。
图2是本发明优选实施例提供的基2蝶形计算单元的示意图,如图2所示,基2蝶形计算单元可执行一个复数乘法运算,用于处理fft运算的偶数项,该运算可由4个实数乘法运算来实现;具体的,该基2蝶形计算单元可包括4个乘法器、3个加法器以及3个减法器。
图3是本发明优选实施例提供的基4蝶形计算单元的示意图,如图3所示,基4蝶形计算单元可执行三个复数乘法运算,用于处理fft运算的奇数项,该运算可由12个实数乘法运算来实现;具体的,该基4蝶形计算单元可包括12个乘法器、11个加法器和11个减法器。
图4是本发明优选实施例提供的分裂基计算单元的示意图,如图4所示,分裂基计算单元结合了基2算法和基4算法,可执行两个复数乘法运算,该运算可由8个实数乘法运算来实现;具体的,该分裂基计算单元计算单元可包括8个乘法器、6个加法器和6个减法器。
由此可知,利用加法器、减法器和乘法器可以实现图1中所示的蝶形运算处理系统的蝶形计算模块。
图5是本发明优选实施例提供的蝶形计算模块的加法器逻辑门电路,如图5所示,该加法器逻辑门电路具有四个输入端口a0,a1,b0,b1和两个输出端口s0,s1,该加法器由异或门、与门、dff、cb等器件实现。其中,控制信号end_bar用于判断当前数据串是否为最后一串。
图6是本发明优选实施例提供的蝶形计算模块的减法器逻辑门电路,如图6所示,该减法器逻辑门电路由
在本发明的一个实施例中,上述蝶形计算模块可以采用72级流水线组成,具体的,包含2946个dff、1968个与门、1128个异或门、144个ndro、102个非门和699个cb。其中的加法器和减法器可分别采用图5和图6所示的逻辑门电路,乘法器可以采用现有技术中的由与门、异或门、非门、dff以及ndro等构成的乘法器逻辑门电路(例如,“g.tang,k.takagi,andn.takagi,“rsfq4-bitbit-sliceintegermultiplier,”ieicetrans.electronics,vol.e99-c,no.6,pp.697–702,jun.2016”中提供的乘法器逻辑门电路)。
图7是本发明优选实施例提供的旋转因子模块的示意图,如图7所示,由于从8点蝶形计算块1输出的每一串的第1点对应的旋转因子值都是1,旋转因子模块只需要执行7个复数乘法即可。在本发明的一个实施例中,上述旋转因子模块可由14个乘法器实现,其中,dff用于保持时钟同步。具体的,旋转因子模块由21级流水线组成,共包含14个乘法器和42个dff。
图8是本发明优选实施例提供的重排模块的逻辑门级电路,如图8所示,该重排模块由8级流水线组成,共包含128个d2ff和56个dff,其中,d2ff是指包含2个时钟输入信号和2个输出信号的dff。
综上所述,本发明提供的串并rsfq蝶形运算处理系统共包含173级流水线,其中,数据串在第1个到第16个时钟周期被输入,并且结果串在第174个到第188个时钟周期输出。
发明人经实验发现,上述可连续处理64点数据的蝶形运算处理系统的延迟为188个时钟周期,在不考虑约瑟夫森传输线(jtl),无源传输线(ptl)和分路器(spl)带来的延迟的情况下,其延迟为20292.4ps,与传统的cmos电路相比,实现了超高的运算速度。
根据本发明的一个方面,还提供一种利用上述蝶形运算处理系统执行fft运算的方法,以连续处理64点是数据为例,从步骤0开始计数具体包括以下12个步骤。
步骤0至步骤7:将64点数据分成8串,每串8点。
具体的,在步骤i(0≤i≤7)中,将第i串数据依次输入到蝶形计算模块1中。其中,第i串的8点数据数据为:
x(i),x(i+8),x(i+16),x(i+24),x(i+32),x(i+40),x(i+48),x(i+56)
步骤1至步骤8:将蝶形计算模块1的输出串输入至旋转因子模块中。
具体的,假设8点蝶形计算模块1的输出数据串为
步骤2至步骤9:将旋转因子模块的中间结果输入至重排模块中。
具体的,将旋转因子模块的中间结果输入至重排模块中以改变序列顺序,其中,重排模块的每个输出串(共8串)的第k(0≤k≤7)个点可用于构成蝶形计算模块2的第k(0≤k≤7)个输入串的8个点。例如,重排模块输出的第1串的8个点可以是
步骤3至步骤10:将重排模块的输出串输入至蝶形计算模块2中。
具体的,将重排模块输出的第i(0≤i≤7)串,即xi′,依次输入至8点蝶形计算模块2中。
步骤4至步骤11:输出64点数据串。
具体的,逐个输出64点数据的第i(0≤i≤7)串,其中,第i个输出串的8点数据,可按以下的顺序输出,即
x(i),x(i+8),x(i+16),x(i+24),x(i+32),x(i+40),x(i+48),x(i+56)
虽然本发明已经通过优选实施例进行了描述,然而本发明并非局限于这里所描述的实施例,在不脱离本发明范围的情况下还包括所做出的各种改变以及变化。
- 还没有人留言评论。精彩留言会获得点赞!