一种终端上的智能音量控制方法和装置与流程
本申请涉及智能终端技术,特别涉及一种终端上的智能音量控制方法和装置。
背景技术:
当前人工智能的研究是行业热点,而依靠机器学习的智能领域也受到越来越多的关注。伴随着越来越多的智能化要求及大数据的发展,人工智能展现出新的活力。2016年3月google公司的智能机器人alphago,在与韩国棋手李世石的围棋对决中以4:1获胜,这表明在逻辑与运算方面,智能机器人可能超过人类。从人工智能角度看,目前ai的高级认知功能还远弱于人类,但是目前的技术可以实现基于ai智能技术,使智能手机更加智能化,以方便人们的使用。
目前在终端上进行音量调节时,通常是在手机框架层进行区分,手机硬件抽像层进行不同逻辑设备的定义,把不同的铃声做为不同的声音类型,用户可通过实体按键或虚拟触摸的方式分别进行调节。
但是,目前手机上的音量类型众多,有来电铃声、媒体播放音量、按键音、闹铃、通话音等等,有些音共用一个逻辑设备进行音量调节,有些音则单独使用一个逻辑设备进行调节。在不同的场景下,用户不得不进行不同的设置,比如在吵闹的环境下,用户不断地调高通话音量,有时甚至需要插上耳机,而在安静地环境下播放歌曲,可能需要不断地尝试调整音量,以达到一个自己认为最合理的值。这个过程无疑是复杂且无奈的。对于手机熟练使用的人来讲,虽然也略感无奈,但总体来讲,调节各种音量也算得心应手,但对于不熟练使用手机的人,这么多音量的设置无疑是一个痛苦的过程,想达到一个自己称心的音量,需要不停地学习、尝试及调整。
技术实现要素:
本申请提供一种终端上的智能音量控制方法和装置,能够根据当前环境状况自适应建议或调节音量。
为实现上述目的,本申请采用如下技术方案:
一种终端上的智能音量控制方法,包括:
步骤a,采集所述终端的当前位置信息;获取当前环境的图片并输入通过训练生成的图片识别模型,根据照片模型仓库进行图片识别得到图片识别结果;通过图片识别结果确定当前的环境信息;采集当前环境的声音信号,并确定所采集声音信号的音量值;
步骤b,根据所述环境信息、所述分贝值和所述当前位置信息,确定当前概率最高的场景,若所述场景的概率大于设定的概率阈值,则按照预先设定的场景与音量设置间的对应关系,确定所述场景对应的音量设置进行推荐或直接设置;否则,返回步骤a。
较佳地,在每次得到图片识别结果后,所述步骤a进一步包括:根据所述图片识别结果更新所述图片识别模型的参数,并将所述当前环境的图片加入所述照片模型仓库,用于下一次图片识别。
较佳地,周期性执行所述获取当前环境的图片并进行图片识别的处理;
和/或,所述图片识别模型为卷积神经网络。
较佳地,获取当前环境的图片包括:实时采集当前环境的图片,或者,将所述当前位置信息下所述终端曾经拍摄的照片作为所述当前环境的图片。
较佳地,所述通过图片识别结果确定所述第一环境信息包括:从所有图片识别结果中选择概率最大的一个识别结果作为所述第一环境信息;
和/或,当图片识别失败的次数小于预设的阈值时,返回步骤a;当图片识别失败的次数达到或超过预设的阈值时,人工设置所述当前环境图片的环境信息。
较佳地,步骤b中所述确定当前概率最高的场景的方式包括:
在数据库中选择与所述环境信息匹配的第一场景类型,并将各第一场景类型的第一概率设置为1/n,所述n为与所述第一环境信息匹配的场景类型的个数;
根据所述当前位置信息与各所述第一场景类型所在位置间的距离,计算相应第一场景类型的位置概率;
根据每个第一场景类型的第一概率和位置概率,按照预设的位置概率和第一概率在环境概率中所占的比重,计算各第一场景类型的环境概率;
根据每个第一场景类型的环境概率和位置概率,按照预设的环境概率和位置概率在最终概率中所占的比重,计算各第一场景类型的最终概率,并选择最终概率最高的第一场景类型作为最终场景类型;
确定与最终场景类型匹配的所有场景,并从中选择满足所述音量值的场景作为当前概率最高的场景,将所述最终场景类型的概率作为该场景的概率。
较佳地,在选择出第一场景类型后、计算各第一场景类型的环境概率前,该方法进一步包括:对当前环境的声音信号进行语音识别,通过语音识别结果确定各所述第一场景类型的语音概率;
在计算各第一场景类型的环境概率时,进一步根据各第一场景类型的语音概率,按照预设的语音概率在环境概率中所占的比重进行。
较佳地,在对当前环境的声音信号进行语音识别时,若语音识别失败,则在计算各第一场景环境的环境概率时,不再根据语音概率进行。
较佳地,在所述步骤b之前,该方法进一步包括:接收用户对于当前场景的音量设置;
将所述当前概率最高的场景下对应的音量设置为接收的音量设置。
一种智能音量控制装置,包括:定位单元、图片处理单元、声音处理单元、场景选择单元和音量处理单元;
所述定位单元,用于采集所述终端的当前位置信息;
所述图片处理单元,用于获取当前环境的图片并输入通过训练生成的图片识别模型,根据照片模型仓库进行图片识别得到图片识别结果,通过图片识别结果确定当前的环境信息;
所述声音处理单元,用于采集当前环境的声音信号进行语音识别,并确定所采集声音的音量值;
所述场景选择单元,用于根据所述第一环境信息、所述音量值和所述当前位置信息,确定当前概率最高的场景,若所述场景的概率大于设定的概率阈值,则通知所述音量处理单元;否则,通知所述定位单元和所述图片处理单元重新执行各自操作;
所述音量处理单元,用于在接收到所述场景选择单元的通知后,按照预先设定的场景与音量设置间的对应关系,确定所述场景选择单元确定的场景所对应的音量设置进行推荐或直接设置。
较佳地,所述场景选择单元包括:环境概率计算子单元、最终概率计算子单元和场景确定子单元;
所述环境概率计算子单元,用于在数据库中选择与所述第一环境信息匹配的第一场景类型,并将各第一场景类型的第一概率设置为1/n,所述n为与所述第一环境信息匹配的场景类型的个数;根据所述当前位置信息与各所述第一场景类型所在位置间的距离,计算相应第一场景类型的位置概率;根据每个第一场景类型的第一概率和位置概率,按照预设的位置概率和第一概率在环境概率中所占的比重,计算各第一场景类型的环境概率;
所述最终概率计算子单元,用于根据每个第一场景类型的环境概率和位置概率,按照预设的环境概率和位置概率在最终概率中所占的比重,计算各第一场景类型的最终概率,并选择最终概率最高的第一场景类型作为最终场景类型;
所述场景确定子单元,用于确定与最终场景类型匹配的所有场景,并从中选择满足所述音量值的场景作为当前概率最高的场景,将所述最终场景类型的概率作为该场景的概率。
较佳地,所述声音处理单元,还用于对所述当前环境的声音信号进行语音识别,通过语音识别结果确定各所述第一场景类型的语音概率;
所述环境概率计算子单元在计算各第一场景类型的环境概率时,进一步根据各第一场景类型的语音概率,按照预设的语音概率在环境概率中所占的比重进行。
由上述技术方案可见,本申请中,采集终端的当前位置信息;获取当前环境的图片并输入通过训练生成的图片识别模型,根据照片模型仓库进行图片识别得到图片识别结果,通过图片识别结果确定当前的第一环境信息;采集当前环境的声音信号,并确定所采集声音信号的音量值;接下来,根据第一环境信息、声音信号的音量值和当前位置信息,确定当前概率最高的场景,若该场景的概率大于设定的概率阈值,则按照预先设定的场景与音量设置间的对应关系,确定该场景对应的音量设置进行推荐或直接设置;否则,返回方法起始位置重新执行。通过上述方式,能够利用图片识别模型自动学习并进行图片识别,确定当前环境对应的场景,再按照该场景建议或调节音量。
附图说明
图1为本申请中音量控制方法的基本流程示意图;
图2为图片识别处理的流程图;
图3为声音处理的流程图;
图4为确定场景最终概率信息的流程图;
图5为本申请中音量控制装置的基本结构示意图。
具体实施方式
为了使本申请的目的、技术手段和优点更加清楚明白,以下结合附图对本申请做进一步详细说明。
本申请基于机器学习,通过手机的各种传感器,采集用户的场景及使用习惯,通过不断地自动学习及优化调整,完成手机中的所有音量(包括来电铃声、媒体播放音量、按键音、闹铃、通话音等等)的智能化设置,使其符合各个场景下用户真正需要的音量。
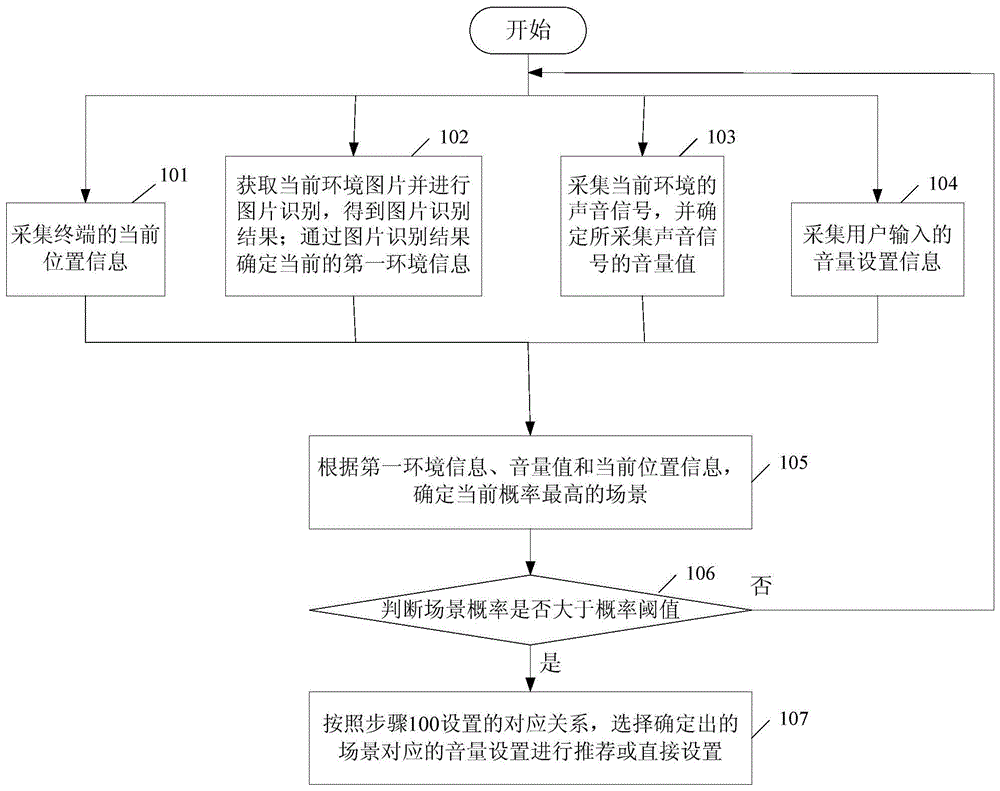
图1为本申请中音量控制方法的基本流程示意图。如图1所示,该方法包括:
步骤100,预设用户场景对应的音量个性化设置。
对应不同的场景,可以设置对应的各种音量的组合取值。具体场景分类可以根据需要进行。通常,场景可以是地点和安静程度的组合,例如,火车站安静场景。给出一个场景与音量组合设置的对应关系举例如表1所示。
表1
步骤101,采集终端的当前位置信息。
终端的位置信息可以辅助确定场景信息。例如,可以根据当前位置与各个场景地点间的距离计算各场景的概率信息,利用该概率信息参与最终场景的确定。
步骤102,获取当前环境的图片并进行图片识别,得到图片识别结果;通过图片识别结果确定当前的第一环境信息。
本步骤中在进行图片识别时,获取当前环境的图片并输入通过训练生成的图片识别模型,根据照片模型仓库进行图片识别。通过上述图片识别模型可以利用大量的机器学习,准确识别图片所反映的环境信息。优选地,采用卷积神经网络进行图片的学习和识别。具体图片识别的内容将在后续详细描述。
通过图片识别确定识别结果后,确定第一环境信息。一般地,图片识别结果可能是多种识别结果的概率信息,例如“天花板”的概率为60%等。在确定图片识别结果后,选择概率最大的一个识别结果作为第一环境信息,用于后续最终场景的确定。
步骤103,采集当前环境的声音信号,并确定所采集声音信号的音量值。
最基本地,通过声音信号的音量值,可以直观地体现当前环境的吵闹程度,从而参与确定最终场景。其中,一般地,音量值可以采用分贝来衡量。
进一步优选地,还可以对采集的声音信号进行语音识别,用于后续最终场景的确定。
通过上述处理,能够采集当前环境信息,包括位置、图片和声音。优选地,还可以进一步执行步骤104接收用户的输入。
步骤104,采集用户输入的音量设置信息。
用户也可以手动针对当前场景进行音量设置,本申请仍然会接收用户的音量设置,并按照优先级进行音量设置。
前述步骤101~104的处理,可以以任意顺序执行或并行执行,并不一定是按照101~104的顺序执行。
在完成上述信息采集后,执行以下步骤确定场景。
步骤105,根据第一环境信息、音量值和当前位置信息,确定当前概率最高的场景。
根据前述步骤确定的第一环境信息、音量值和当前位置信息确定各个可能场景的概率信息,选择概率最高的场景作为当前场景类型。
步骤106,判断步骤105确定的场景概率是否大于设定的概率阈值,若是,则执行步骤107,否则返回执行步骤101~104。
当确定出的场景概率达到阈值时,认为当前实际场景与确定出的场景一致性很高。这时,可以通过步骤107推荐或直接设置音量。当确定出的场景概率未达到阈值时,认为当前实际场景与确定出的场景一致性未达标,返回重新采集位置、图片和声音,重新确定场景。
步骤107,按照步骤100设置的对应关系,选择确定出的场景对应的音量设置进行推荐或直接设置。
另外,在进行音量设置时,如果执行了前述步骤104,在这里进行音量推荐或设置时,不能直接执行步骤107,而是要根据步骤104中用户的输入进行音量设置。这是因为,根据步骤105所确定场景的优先级低于用户输入的音量设置。
至此,本申请中的基本方法结束。
下面对上述图1中涉及的细节处理进行描述。
在图1的步骤102中进行图片识别。具体图片识别的处理可以是周期进行的,在每个周期内的处理可以如图2所示,其中,以利用卷积神经网络进行图片的学习和识别为例进行说明,具体包括:
步骤201,获取当前环境的图片。
这里获取图片的方式可以是直接利用终端摄像头自动采集图片,或者,可以是用户手动采集的图片,或者,也可以根据步骤101获取的位置信息在终端中查找曾经在该位置下拍摄的照片作为当前环境的图片。
步骤202,利用卷积神经网络对当前环境的图片进行图片识别。
利用卷积神经网络,可以进行大量的机器学习。在进行图片识别时,可以采用标准的照片模型仓库,例如cifar-100等。
步骤203,判断图片识别是否成功,若是,则执行步骤204,否则结束本次识别处理或者执行步骤206。
步骤204,在多个图片识别结果中选择概率最大的一个作为当前环境图片的第一环境信息。
优选地,可以包括步骤205更新卷积神经网络和照片模型仓库。
步骤205,根据图片识别结果更新卷积神经网络的参数,并将当前环境的图片及其图片识别结果加入照片模型仓库。
在每次完成图片识别后,可以根据图片识别结果更新卷积神经网络的参数,以进一步提高图片识别的准确性。具体卷积神经网络的利用和更新可以采用现有方式进行,这里就不再赘述。
进一步地,还可以将识别结果和对应图片加入照片模型仓库,用于后续图片识别。
步骤206,接收用户对应当前环境的图片输入的图片标记,并将标记和对应的图片加入照片模型仓库。
图片识别失败的原因可能有:1.识别模块出异常;2.手机因性能问题等无法读取图片。当图片识别失败时,可以直接结束本次的图片识别处理,或者,可以采用本步骤通过人工增加图片的标记,并将该标记及对应图片加入照片模型仓库,用于后续图片的识别。可以将用户输入的图片标记作为当前环境图片的第一环境信息,用于后续最终场景的识别。
上述即为本申请方法中进行图片识别的具体处理。在图1的步骤103中进行声音识别和音量值采集。具体声音识别和音量值的处理可以是周期进行的,在每个周期内的处理可以如图3所示,具体包括:
步骤301,采集当前环境的声音信号。
步骤302,确定采集的声音信号的音量值。
根据音量值可以识别出当前环境是安静还是吵闹的。
步骤303,对声音信号进行语音识别。
一般地,为了更好地进行语音识别,通常会先对声音信号进行预处理、傅里叶变换等处理,然后再进行语音识别。具体预处理、傅里叶变换均采用现有方式进行。
如果进行语音识别的处理,那么需要在确定当前环境图片的识别结果后进行。如前所述,根据图片识别结果确定第一环境信息,例如天花板等。在应用该第一环境信息进行场景识别时,首先需要在数据库中选择与第一环境信息匹配的第一场景类型,例如,天花板匹配的场景类型可能是办公室或火车站等。基于此,本步骤中进行语音识别时,需要根据语音识别结果确定各个第一场景类型对应的语音概率,用于后续最终场景的确定。如果无法从当前环境的声音信号中识别出结果,那就丢弃本次识别。在后续场景确定时不再考虑语音概率。
接下来,对于图1流程中步骤105的具体处理进行详细描述,即,根据第一环境信息、音量值和当前位置信息,确定当前概率最高的场景。这里确定概率最高场景的处理可以如图4所示,具体包括:
步骤401,在数据库中选择与环境信息匹配的第一场景类型,并将各第一场景类型的第一概率设置为1/n。
如前所述,在完成图片识别后,能够确定出当前环境图片的环境信息,也就是概率最高的图片识别结果。该环境信息可能属于不同的场景类型,例如环境信息为“天花板”,那么与天花板匹配的可能是办公室或火车站等,将这些场景类型与图片识别结果间的匹配关系保存在数据库中,就可以根据数据库的内容选择与环境信息匹配的第一场景类型。确定出匹配的第一场景类型可能有多个,对于每个第一场景类型,将该场景类型携带第一概率设置为1/n,也就是说,根据图片确定出这几种场景类型的可能性均等。
步骤402,根据当前位置信息与各个第一场景类型所在位置间的距离,计算相应第一场景类型的位置概率。
在通过步骤401确定出各第一场景类型后,再根据当前位置信息与第一场景类型所在位置间的距离,计算位置概率,例如当前位置是办公室的可能性50%,火车站的可能性25%,这个可能性是根据地理位置来决定的。具体地,可以预先定义,比如:当前位置距离某地100米之内,则认为位于某地的概率是80%;距离某地100米到500米之间,则认为位于某地的概率是60%等;根据实际定位得到的当前位置信息与第一场景所在的位置(例如某地的办公楼)距离,按照预先定义的距离与概率的关系,确定各第一场景类型的位置概率。
步骤403,根据每个第一场景类型的第一概率和位置概率,按照预设的位置概率和第一概率在环境概率中所占的比重,计算各第一场景类型的环境概率。
预先设定位置概率和第一概率在环境概率中的比重,例如可以设定位置概率占α,由图片识别结果而确定的第一概率占β,那么某第一场景类型的环境概率=a*α+b*β,a和b分别为某第一场景类型的位置概率和第一概率。其中,α+β=1。
另外,如果在图1流程中包括对声音信号进行的语音识别,且语音识别成功,那么在这里计算环境概率时还需要考虑语音识别得到的声音概率。具体地,可以按照预设的位置概率、第一概率和声音概率在环境概率中所占的比重,根据每个第一场景类型的第一概率、位置概率和环境概率信息,计算各第一场景类型的环境概率。例如,可以设定位置概率占α,由图片识别结果而确定的第一概率占β,由语音识别结果而确定的语音概率为γ,那么某第一场景类型的环境概率=a*α+b*β+c*γ,a、b和c分别为某第一场景类型的位置概率、第一概率和声音概率。其中,α+β+γ=1。
步骤404,根据每个第一场景类型的环境概率和位置概率,按照预设的环境概率和位置概率在最终概率中所占的比重,计算各第一场景类型的最终概率,并选择最终概率最高的第一场景类型作为最终场景类型。
本步骤中,计算最终概率的方式与前述有些类似,利用步骤404得到的环境概率和步骤402得到的位置概率计算最终概率。其中,环境概率和位置概率在最终概率中所占的比重之和为1。
步骤405,确定与最终场景类型匹配的所有场景,并从中选择满足步骤103确定出的音量值的场景作为最终场景类型,将最终场景类型的概率作为选择出的场景的概率。
假定最终场景类型确定为办公室,那么办公室对应的场景可能有多个声音分贝的等级,对应安静、吵闹等。根据声音信号的分贝值在与最终场景类型匹配的所有场景中选择合适的场景,并将最终场景类型的概率作为选择出的场景的概率。
例如最终确定的场景类型为办公室,采用分贝数来衡量音量值,匹配的场景包括:办公室吵闹等级1;办公室吵闹等级2;办公室吵闹等级3(60-80db)。确定的声音信号的分贝值为70,那么选择出的场景为办公室吵闹等级3(60-80db)。
这样就确定出最终选择场景的概率信息,然后继续执行步骤106即可。
下面给出一个应用本申请中的方法确定场景并控制音量的示例。其中,以分贝值衡量声音信号的音量值,利用卷积神经网络进行图片的学习和识别。
首先,采集并识别当前环境的图片,卷积神经网络使用cnn(convolutionalneuralnetworks),具体包括卷积3次,池化2次,神经网络全连接1次。通过图2所示的方法进行图片识别后,得到的第一场景类型及其第一概率如表2所示。
表2
接下来,采用图3所示的方法采集声音信号,确定分贝值并进行语音识别。语音识别完成后相应各第一场景类型的声音概率以及当前环境的分贝值如表3所示。
表3
最后,采用图4所示的处理确定各种场景的概率信息。其中,每种场景的概率与该场景匹配的场景类型的概率一致。例如,场景类型为办公室时,与该类型匹配的各类场景(比如办公室安静级别1,办公室安静级别2等)的概率与办公室的概率信息一致。这里假定场景1为“安静级别1(20-40db),在办公室”。第一次执行图4流程后得到的结果概率信息如表4所示。
表4
由表4可见,最终选择出的场景为场景1,概率为50%,假定概率阈值为90%,则该概率50%未达到阈值,因此,不能采纳该场景信息,需要返回重新进行图片和声音的采集以再次确定场景。优选地,在每次计算得到最终场景概率后,可以保存该结果。在下一次重新采集图片和声音后,利用上述流程重新进行一次场景的确定,假定最终选择出的场景仍然为场景1,概率为70%,由于仍然未达到阈值,因此该场景信息仍然不被采纳,但是结果可以予以保存。再次回到初始重新采集图片和声音。经过n次采集之后,假定最终选择出的场景为场景1,且概率为90%,那么确定当前场景为场景1,根据表5进行音量组合的推荐或设置。
表5
上述即为本申请中音量控制方法的具体实现。本申请还提供了一种音量控制装置,可以用于实施上述音量控制方法。图5为音量控制装置的基本结构示意图。如图5所示,该装置包括:定位单元、图片处理单元、声音处理单元、场景选择单元和音量处理单元。
其中,定位单元,用于采集终端的当前位置信息。图片处理单元,用于获取当前环境的图片并输入通过训练生成的图片识别模型,根据照片模型仓库进行图片识别得到图片识别结果,通过图片识别结果确定当前的环境信息。声音处理单元,用于采集当前环境的声音信号进行语音识别,并确定所采集声音的音量值。场景选择单元,用于根据第一环境信息、声音信号的音量值和当前位置信息,确定当前概率最高的场景,若场景的概率大于设定的概率阈值,则通知音量处理单元;否则,通知定位单元和图片处理单元重新执行各自操作。音量处理单元,用于在接收到场景选择单元的通知后,按照预先设定的场景与音量设置间的对应关系,确定场景选择单元确定的场景所对应的音量设置进行推荐或直接设置。
另外优选地,场景选择单元可以包括:环境概率计算子单元、最终概率计算子单元和场景确定子单元。其中,环境概率计算子单元,用于在数据库中选择与第一环境信息匹配的第一场景类型,并将各第一场景类型的第一概率设置为1/n;根据当前位置信息与各第一场景类型所在位置间的距离,计算相应第一场景类型的位置概率;根据每个第一场景类型的第一概率和位置概率,按照预设的位置概率和第一概率在环境概率中所占的比重,计算各第一场景类型的环境概率;最终概率计算子单元,用于根据每个第一场景类型的环境概率和位置概率,按照预设的环境概率和位置概率在最终概率中所占的比重,计算各第一场景类型的最终概率,并选择最终概率最高的第一场景类型作为最终场景类型;场景确定子单元,用于确定与最终场景类型匹配的所有场景,并从中选择满足音量值的场景作为当前概率最高的场景,将所述最终场景类型的概率作为该场景的概率。
优选地,声音处理单元,还用于对所述当前环境的声音信号进行语音识别,通过语音识别结果确定各第一场景类型的语音概率。环境概率计算子单元在计算各第一场景类型的环境概率时,进一步根据各第一场景类型的语音概率,按照预设的语音概率在环境概率中所占的比重进行。
通过上述本申请,基于机器学习,终端不断采集自己的使用场景,包括视频采集、音频采集、用户习惯采集等等,最后通过不断循环优化的机器学习神经网络算法,完成手机所有音量,在任何场景下的智能化设置,使其符合各个场景下用户真正需要。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!