一种基于多智能体的分布式能源枢纽的调度方法与流程
本发明涉及分布式能源调度技术领域,尤其涉及一种基于多智能体的分布式能源枢纽的调度方法。
背景技术:
能源系统应当对各类用户提供安全可靠、合乎标准的电能,时刻满足电力用户即负荷的电量需求。在满足用户需求的同时,应提高能源利用率,降低碳排放和提高能源使用的灵活性。在此背景下,提出了能源枢纽的概念,能源枢纽可用于不同能源载体之间的转化,存储和调度。在此基础上,本专利提出了一种基于多智能体讨价还价博弈学习算法的分布式能源枢纽经济调度方法。现有的调度优化方法大都属于集中式优化算法,容易给处理器带来较大的计算压力。同时随着规模和复杂度的上涨,难以找到最优解。
技术实现要素:
本发明所要解决的技术问题在于,提供一种多智能体的分布式能源枢纽的调度方法,该方法能够在分布式能源枢纽中有效求得平衡点,并能有效提高最优解的精确性。
为了解决上述技术问题,本发明提供一种基于多智能体的分布式能源枢纽的调度方法,包括如下步骤:
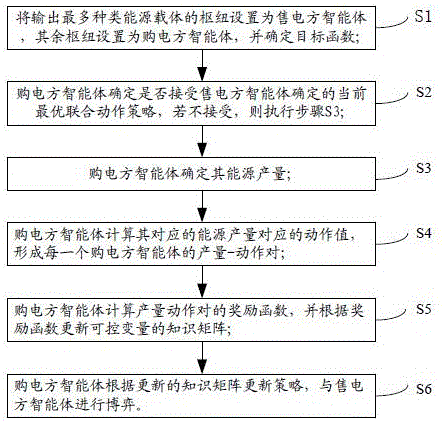
s1、将输出最多种类能源载体的枢纽设置为售电方智能体,其余枢纽设置为购电方智能体,并确定调度的目标函数;
s2、购电方智能体确定是否接受售电方智能体确定的当前最优联合动作策略,若不接受,则执行步骤s3;
s3、购电方智能体确定其能源产量,
s4、购电方智能体计算其对应的能源产量对应的动作值,形成每一个购电方智能体的产量-动作对;
s5、购电方智能体计算产量-动作对的奖励函数,并根据奖励函数更新可控变量的知识矩阵;
s6、购电方智能体根据更新的知识矩阵更新动作策略,与售电方智能体进行博弈。
其中,所述s1中确定的目标函数为:
其中,fi(x)为发电成本,fc(x)为电能损耗,x为整个能源系统的可控变量,包括每个能源载体的产量和每个分配因子;xm表示第m个能源集线器的可控变量向量;小标m和p分别表示第m个能源集线器和第p个能源载体,m表示能源集线器的总数量,p是能源载体的集合;
其中,所述步骤s2中售电方智能体确定的最优联合动作策略为:
其中,k表示迭代次数;xk*表示第k次迭代的最优联合动作策略;
其中,所述步骤s3具体包括:
其中,
其中,所述步骤s4具体包括:
其中,
其中,所述步骤s5中计算获得的奖励函数为:
其中,fikj表示在第k次迭代中,第j个智能体的适应度函数;pm是正系数;saibest表示在第k次迭代,第i个智能体的最优动作集;f为前述惩罚函数;nci表示对第i个购电方智能体的约束数目;pfiu表示对第i个购电方智能体第u个约束的惩罚函数;χ是惩罚因数;ziu表示对第i个购电方智能体的第u个约束;ziu,lim表示与ziu相对应的约束限制。
其中,所述步骤s5中根据奖励函数更新可控变量的知识矩阵具体包括:
其中,qih表示第i个购电方智能体的第h个变量的知识矩阵;δq表示知识量的增长;α表示知识学习率;γ表示折扣系数;
其中,所述步骤s6具体包括:
其中,i=1,2,...,n。
本发明实施例的有益效果在于:采用一个售电方和n个购电方的博弈模型,首先售电方智能体确定当前最优联合动作策略,在各购电方智能体不接受售电方智能体的动作策略的情况下,各购电方智能体确定每一个可控变量的状态-动作对,并计算每一个状态-动作对的奖励函数,根据奖励函数更新知识矩阵,从而更新每一个购电方智能体的动作策略进行博弈。该方法采用一个售电方和n个购电方的博弈模型,能够在分布式能源枢纽中有效求得平衡点,本发明采用联想记忆和群体智能,能够加速知识矩阵的收敛,同时探索机制的存在能有效提高最优解的精确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例的一种基于多智能体的分布式能源枢纽的调度方法的流程示意图。
具体实施方式
以下各实施例的说明是参考附图,用以示例本发明可以用以实施的特定实施例。
以下参照图1进行说明,本发明实施例一提供一种基于多智能体的分布式能源枢纽调度方法,其包括如下步骤:
s1、将输出最多种类能源载体的枢纽设置为售电方智能体,其余枢纽设置为购电方智能体,并确定目标函数。
具体地,选择输出最多种类能源载体的集线器为售电方智能体,其余集线器为购电方智能体。
目标函数为考虑发电方的成本以及电能损耗的综合函数
其中nmp为与第m个能源集线器的第p个输入能源载体相关联的能源数量,nme是第m个能源集线器具有阀点效应的发电机数量,
s2、购电方智能体确定是否接受售电方智能体确定的当前最优联合动作策略,若不接受,则执行步骤s3。
具体地,售电方智能体根据下式确定当前最优联合策略:
其中,k表示迭代次数;xk*表示第k次迭代的最优联合动作策略;
s3、购电方智能体确定其能源产量。
具体地,购电方各智能体若接受售电方智能体的策略,则迭代结束;若不接受,则购电方各智能体根据下式确定第一个可控变量状态,即购电方智能体的能源产量。
此处,
s4、购电方智能体计算其对应的能源产量对应的动作值,形成每一个购电方智能体的产量-动作对。
具体地,每一个购电方智能体根据相应的知识矩阵对可控变量选择一个动作策略,其次根据相应区间的局部最优解,利用非均匀突变算子计算出精确值。
更具体地,每一个购电方智能体根据下式对可控变量选择一个动作策略的范围
更具体地,根据相应区间的局部最优解,利用非均匀突变算子计算出动作的精确值
s5、购电方智能体计算产量-动作对的奖励函数,并根据奖励函数更新可控变量的知识矩阵。
具体地,各购电方智能体根据下式计算每一可控变量的状态-动作对的奖励函数:
其中,
具体地,采用q学习进行知识矩阵更新,同时为了避免“维数灾”应采用联想记忆来存储知识。
根据奖励最大化原则,购电方智能体根据下式对每个可控变量更新知识矩阵,具体包括:
其中,qih表示第i个购电方智能体的第h个变量的知识矩阵;δq表示知识量的增长;α表示知识学习率;γ表示折扣系数;
s6、购电方智能体根据更新的知识矩阵更新策略,与售电方智能体进行博弈。
具体地,购电方智能体根据下式更新策略:
其中,i=1,2,...,n。
本发明实施例的一种基于多智能体的分布式能源枢纽调度方法,采用一个售电方和n个购电方的博弈模型,首先售电方智能体确定当前最优联合动作策略,在各购电方智能体不接受售电方智能体的动作策略的情况下,各购电方智能体确定每一个可控变量的状态-动作对,并计算每一个状态-动作对的奖励函数,根据奖励函数更新知识矩阵,从而更新每一个购电方智能体的动作策略进行博弈。该方法采用一个售电方和n个购电方的博弈模型,能够在分布式能源枢纽中有效求得平衡点,本发明采用联想记忆和群体智能,能够加速知识矩阵的收敛,同时探索机制的存在能有效提高最优解的精确性。
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!