基于深度神经网络的网络视频字幕的快速提取方法与流程
本发明涉及计算机视觉领域的文本检测方法和文本识别方法,尤其涉及一种自动样本合成和多batch加速的端到端的基于深度神经网络的网络视频字幕的快速提取方法。
背景技术:
近年来,深度神经网络由于其特征表示和鲁棒性的能力而推动了目标检测和目标识别的进步,并且基于dnn的方法已经实现了非常好的性能。在文本检测领域ctpn(z.tian,w.huang,tonghe,etal.detectingtextinnaturalimagewithconnectionisttextproposalnetwork.eccv,2016)对水平和长文本的检测效果很好,在文本识别领域attentionocr(lee,chenyu,ands.osindero."recursiverecurrentnetswithattentionmodelingforocrinthewild."computervisionandpatternrecognitionieee,2016:2231-2239.)的识别效果也不错。
目前文本检测和识别主要基于一些开源的数据集来进行训练,这些开源数据集基本以英文为主,数据量不大;目前网上还没有更公开的网络视频字幕的检测和识别的数据集,这也成为基于深度学习方法的网络视频字幕提取的一个难点所在。网络视频由于视频帧数比较庞大,所以要求视频字幕的提取应该具有实时性,这样才能满足商用需求。
近年来,基于深度学习的自然场景下文本检测和识别有了较大发展,但是基于深度学习的网络视频字幕的文本检测和识别的方法比较少,主要是由于目前缺乏公开的网络视频字幕的文本检测和文本识别的训练样本,而且由于视频帧数巨大,如果网络耗时太长,就没有太大的应用价值,如果减小网络,又会造成字幕提取效果不好。
技术实现要素:
为了解决上述问题,本发明的目的是提供一种方法简单,实现网络视频字幕的高效准确的提取的基于深度神经网络的网络视频字幕的快速提取方法。
本发明的技术方案是:基于深度神经网络的网络视频字幕提取方法,该提取方法包括:
s1:将随机选取的背景图片合成含字幕的图片,再利用一定的投影算法,得到字幕的图片的标签数据;
s2:建立字幕文本检测模型和字幕文本识别模型,将s1得到标签数据加入到字幕文本检测模型和字幕文本识别模型中进行训练;
s3:建立多batch加速机制;
s4:将训练好的字幕文本检测模型和字幕文本识别模型组合在一起形成一个端到端的字幕提取算法,并加入多batch的机制,加速字幕的提取速度。
进一步,所述s1的具体步骤为:
s1.1利用ffmpeg和opencv这两个工具库,将预先设置配置文本,配置文件包含ass字幕需要属性设置信息,根据读取到的配置文件信息生成ass字幕文与随机选取的背景图片进行处理,得到包含字幕的图片和其二值图片;
s2.2:对二值图片在水平和竖直两个方向上做投影得到字幕文本行的位置,得到的字幕位置信息和字幕文本信息组成了训练样本,即标签数据。
进一步,所述s2的所述文本检测模型为开源的ctpn模型,即开源模型的基础上,将anchor修改为[11,16,27,35,44,55,69,86,108,135]。
进一步,所述s2的具体步骤为:将s1得到的标签数据分别加入到字幕文本检测模型和字幕文本识别模型的训练代码中去,作为模型的数据层,自动生成字幕文本检测模型和字幕文本识别模型的训练数据,对字幕文本检测模型和字幕文本识别模型进行深度训练。
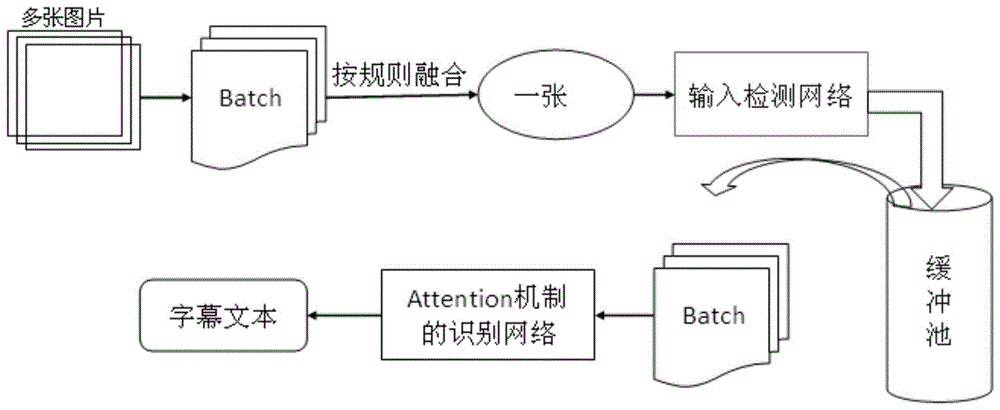
进一步,所述s3的具体步骤为:将视频解析成一帧一帧的多张图片,每帧数据只取下三分之一的图片数据,然后将连续的三帧需要处理的图片按照其在视频中出现的先后顺序,从上而下组合成一个新的视频帧,将多个新的视频帧组合成一个n*h*w*3的多batch加速机制;其中n代表batch里的图片数目,一个batch里包含3*n帧图片数据,h、w表示图片的高和宽,3表示输入图片的通道数。
进一步,所述s4的具体步骤为:将含有字幕文本检测模型文本检测网络和含有字幕文本识别模型的文本识别网络建立有效的网络连接,并在文本检测网络与文本识别网络之间加入一个“缓冲池”,当文本检测网络检测的结果填满“缓冲池”时,将“缓冲池”中的多batch加速机制一次性输入到文本识别网络,进行字幕文本字符的识别。
一种实现所述的基于深度神经网络的网络视频字幕提取方法的计算机程序。
一种实现所述的基于深度神经网络的网络视频字幕提取方法的信息处理终端。
一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的基于深度神经网络的网络视频字幕提取方法。
本发明的有益效果是:由于采用上述技术方案,本发明的使用ctpn和基于attention机制的识别网络作为基础的检测网络和识别网络,将两个网络通过有效的连接在一起,用于对网络视频字幕进行提取。针对,网络视频字幕的深度学习训练样本的缺乏这一情况,我们提出了一个样本自动生成样本的数据层;为了加快网络视频字幕的提取,我们提出了多batch加速机制,使得网络提取字幕的速度比没有多batch加速机制时提高了两倍。在加入自动合成样本的数据层和多batch加速机制后,我们的字幕提取方法的字符级识别准确率基本在0.98以上,行级识别准确率达到了平均达到了0.85,平均提取速度60ms/帧,已经初步得到了商业应用。
附图说明
图1为本发明基于深度神经网络的网络视频字幕提取方法的逻辑框图。
图2为本发明中得到标签数据的流程框图。
图3为采用本发明方法对新闻标题的提取的实验结果。
图4为采用本发明方法对中文简体字幕的提取的实验结果。
图5为采用本发明方法对英文字幕的提取的实验结果。
图6为采用本发明方法对中文繁体字幕的提取的实验结果。
具体实施方式
下面结合具体实施例对本发明的技术方案做进一步说明。
本发明基于深度神经网络的网络视频字幕提取方法,该提取方法包括:
s1:将随机选取的背景图片合成含字幕的图片,再利用一定的投影算法,得到字幕的图片的标签数据;
s2:建立字幕文本检测模型和字幕文本识别模型,将s1得到标签数据加入到字幕文本检测模型和字幕文本识别模型中进行训练;
s3:建立多batch加速机制,
s4:将训练好的字幕文本检测模型和字幕文本识别模型组合在一起形成一个端到端的字幕提取算法,并加入多batch的机制,加速字幕的提取速度。
所述s1的具体步骤为:
s1.1利用ffmpeg和opencv这两个工具库,将预先设置配置文本,配置文件包含ass字幕需要属性设置信息,根据读取到的配置文件信息生成ass字幕文与随机选取的背景图片进行处理,得到包含字幕的图片和其二值图片;
s2.2:对二值图片在水平和竖直两个方向上做投影得到字幕文本行的位置,得到的字幕位置信息和字幕文本信息组成了训练样本,即标签数据。
所述s2的所述文本检测模型为开源的ctpn模型,即开源模型的基础上,将anchor修改为[11,16,27,35,44,55,69,86,108,135]。
所述s2的具体步骤为:将s1得到的标签数据分别加入到字幕文本检测模型和字幕文本识别模型的训练代码中去,作为模型的数据层,自动生成字幕文本检测模型和字幕文本识别模型的训练数据,对字幕文本检测模型和字幕文本识别模型进行深度训练。
所述s3的具体步骤为:将视频解析成一帧一帧的多张图片,每帧数据只取下三分之一的图片数据,然后将连续的三帧需要处理的图片按照其在视频中出现的先后顺序,从上而下组合成一个新的视频帧,将多个新的视频帧组合成一个n*h*w*3的多batch加速机制;其中n代表batch里的图片数目,一个batch里包含3*n帧图片数据,h、w表示图片的高和宽,3表示输入图片的通道数。
所述s4的具体步骤为:将含有字幕文本检测模型文本检测网络和含有字幕文本识别模型的文本识别网络建立有效的网络连接,并在文本检测网络与文本识别网络之间加入一个“缓冲池”,当文本检测网络检测的结果填满“缓冲池”时,将“缓冲池”中的组合成一个poolsize*h*w*3的batch一次性输入到文本识别网络,进行字幕文本字符的识别。(注:其中poolsize代表缓冲池的大小)。
当文本检测网络检测的结果填满“缓冲池”时,将“缓冲池”中的组合成一个poolsize*h*w*3的batch一次性输入到文本识别网络,进行字幕文本字符的识别。(注:其中poolsize代表缓冲池的大小).
一种实现所述的基于深度神经网络的网络视频字幕提取方法的计算机程序。
一种实现所述的基于深度神经网络的网络视频字幕提取方法的信息处理终端。
一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的基于深度神经网络的网络视频字幕提取方法。
实施例:
(1)在本发明的实验中,我们采用了tensorflow深度学习框架,用python3语言对模型的进行了编程实现。
(2)使用ctpn网络和基于attention机制的识别网络作为基础的检测网络和识别网络,分别对字幕文本检测网络和字幕文本识别网络进行训练和挑选。在模型的训练过程中,将本发明的样本数据生成程序(算法),分别加入到字幕文本检测模型和字幕文本识别模型的训练代码中去,作为模型的数据层,自动生成字幕文本检测模型和字幕文本识别模型的训练数据,训练字幕文本检测模型和字幕文本识别模型,然后对训练好的检测和识别模型进行测试,挑选出性能最好的模型。训练检测模型大概让数据层合成25000个样本,训练了20万轮,而识别模型训练时合成了大约500万的训练数据,训练了20万轮。
(3)将训练好的字幕文本检测模型和字幕文本识别模型组合在一起形成一个端到端的字幕提取算法,并加入多batch的机制,加速字幕的提取速度。
(4)对最终的端到端的字幕提取方法,进行实验验证,所有的实验都在装有linux和gtx1080tigpu的服务器上进行。
(5)实验结果如图3(新闻标题的提取)、图4(中文简体字幕的提取)、图5(英文字幕的提取)、图6(中文繁体字幕的提取)
模型在标注的数据集上的测试效果:
英文字幕:测试数据样本大小3000张;字符级准确率达到了99%以上,行级准确率达到了86%;
中文简体字幕:测试数据样本大小3000张;字符级准确率达到了97%以上,行级准确率达到了91%;
中文繁体字幕:测试数据样本大小3000张;字符级准确率达到了95%以上,行级准确率达到了80%;
没有batch加速机制:高清网络视频字幕的检测时间86ms/帧;识别时间108ms/帧,字幕平均提取时间大约200ms/帧;
有batch加速机制:高清网络视频字幕的平均检测时间55ms/帧;平均识别时间5ms/帧,字幕平均提取时间大约60ms/帧。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!