一种基于自适应平衡集成与动态分层决策的多分类方法与流程
本发明涉及机器学习领域多分类方法,尤其涉及一种基于自适应平衡集成与动态分层决策的多分类方法。
背景技术:
在利用机器学习方法解决多分类问题时,将原始多分类问题转化为多个二分类问题是一种有效的手段。其中,一对多分解策略是一种主流的分解方法,但该框架下存在严重的正负样本数目不平衡、预测结果过度依赖二分类器置信度等问题。根据合适的机器学习方法解决一对多框架下的类不平衡与结果聚合问题,以提高分类模型的准确率,是当今研究的热点之一。解决目前对于不平衡数据的分类问题,常用技术主要分为数据级方法、算法级方法、代价敏感学习和集成学习技术。数据级方法通过对数据空间进行抽样来重新平衡类分布,具体为对多数类样本欠采样或者对少数类样本过采样。欠采样中主要有随机欠采样与基于聚类的欠采样。随机欠采样从多数类样本中随机挑选部分样本与全部少数类样本组成新的训练样本,该方法虽然生成了平衡的数据集,但随机性强、未虑整个样本空间分布特点,会造成多数类有用信息的丢失;基于聚类的欠采样将多数类样本聚成多个簇,其中簇个数等于少数类样本个数,然后从所有簇中挑选中心点或者离中心点最近的样本作为训练样本,一定程度上减少了随机欠采样的盲目性。但是当少数类样本数目很大时,直接选取少数类样本个数作为簇个数可能会影响聚类过程,不利于后续采样。过抽样中经典的方法是smote,该算法随机选择部分少数类样本,从这些少数类样本最近的几个邻居点中随机挑选一个样本,然后在这两个样本之间合成新的少数类样本。过采样具有的缺点是增加少数样本,可能会造成过拟合。borderline-smote1只利用位于边界内的少数样本合成新的样本,borderline-smote2除了只考虑边界点,允许少数类邻居点中存在部分多数类样本。以上方法可以减少噪声点的产生,而基于kmeans和smote的启发式过采样不仅解决类间不平衡,还可以解决类内不平衡。算法级方法通过直接修改现有方法或者提出新的方法来解决类不平衡分类问题,但需要满足一定的假设条件。代价敏感学习为少数类样本分配的错误分类代价成本高于多数类样本,优化目标是使分类器的分类结果对应总代价成本最低,如何确定合适的代价成本是这类方法需要考虑的问题,同时也是难以解决的问题。集成学习技术将数据级方法与集成学习bagging或者boosting方法相结合,不仅通过数据预处理降低数据不平衡程度,而且通过组合多个分类器可提高分类性能。bagging方法虽然简单,但是如果与数据预处理合理组合将对处理类不平衡分类问题具有积极作用,有效地组合两种方法可以提高对不平衡数据的分类效果。解决目前对于一对多框架下结果聚合的问题,主要有最大置信度值与动态排序方法。最大置信度考虑全部二分类模型结果,将最大置信度值对应的类别作为预测类别,但是该方法无法解决出现多个最大置信度值的情况。动态排序方法在对测试样本进行分类前,事先根据朴素贝叶斯分类器得到所有二分类模型对该样本的测试顺序,而不用同时考虑全部二分类模型结果。但朴素贝叶斯分类器给出的输出顺序对最终预测结果具有一定的影响,当所有二分类器输出结果中出现多个正类的概率大于阈值时影响更大。
技术实现要素:
有鉴于此,本发明实施例提出了一种基于自适应平衡集成与动态分层决策的多分类方法,以提高分类模型的准确率。
本发明实施例提出的一种基于自适应平衡集成与动态分层决策的多分类方法,包括:
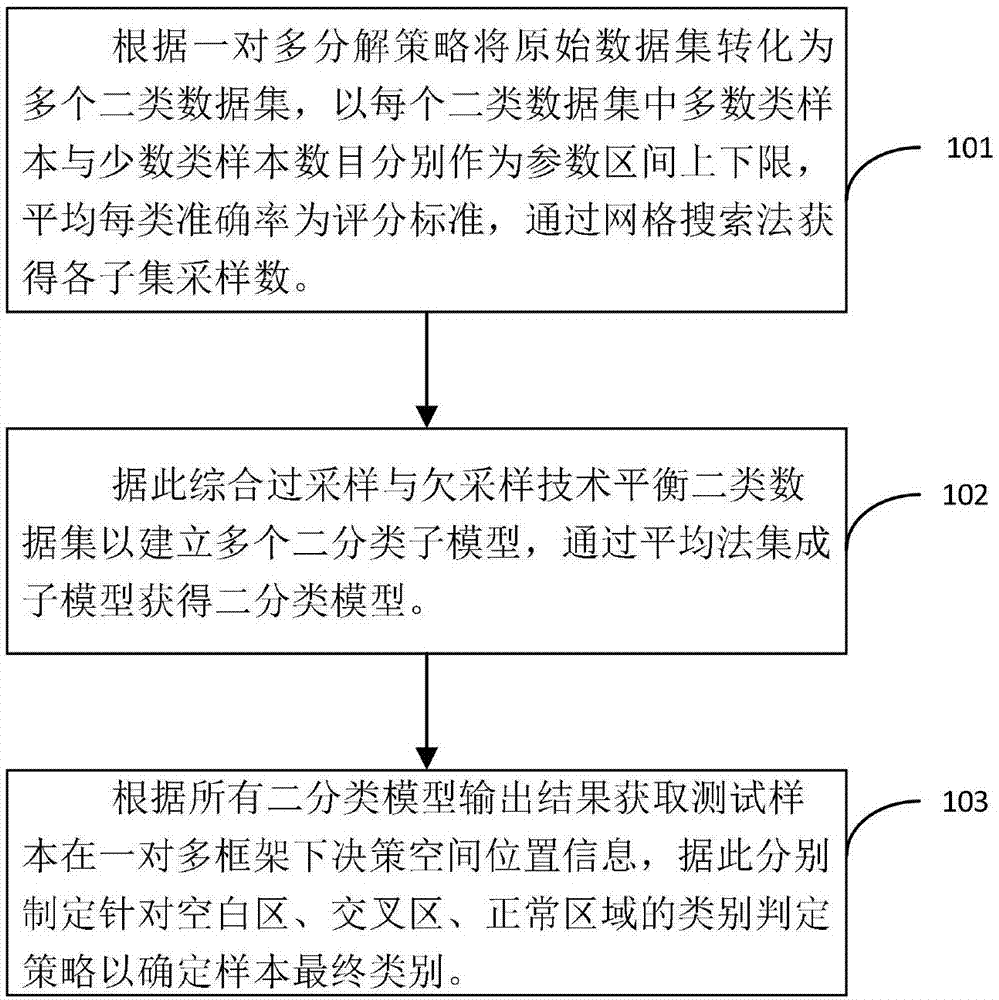
根据一对多分解策略将原始数据集转化为多个二类数据集,以每个二类数据集中多数类样本与少数类样本数目分别作为参数区间上下限,平均每类准确率为评分标准,通过网格搜索法获得各子集采样数;
据此综合过采样与欠采样技术平衡二类数据集以建立多个二分类子模型,通过平均法集成子模型获得二分类模型;
根据所有二分类模型输出结果获取测试样本在一对多框架下决策空间位置信息,据此分别制定针对空白区、交叉区、正常区域的类别判定策略以确定样本最终类别。
上述方法中,根据一对多分解策略将原始数据集转化为多个二类数据集,以每个二类数据集中多数类样本与少数类样本数目分别作为参数区间上下限,平均每类准确率为评分标准,通过网格搜索法获得各子集采样数的方法为:假定数据集d的类别总数为m,根据一对多分解策略将原始数据集d转化为m个二类数据集di,其中,i=1,2,...,m,每个二类数据集中正类对应某一类别,负类对应剩余所有类别;根据网格搜索法分别对每个di在{count(less),count(more)}内进行采样数目搜索,其中count(more)为多数类训练样本总数、count(less)为少数类训练样本总数,具体地将每个di随机划分为五折,每四折作为训练集dtr={lesstr,moretr},lesstr为少数类训练样本,moretr为多数类训练样本,每一折作为测试集,设定间距d,其中,0<d<count(moretr),从参数区间{count(lesstr),count(moretr)}内等间距确定采样数目num,据此平衡每四折对应的样本数据以建立多个分类模型,其中,count(moretr)为moretr中样本总数、count(lesstr)为lesstr中样本总数,利用剩余一折包含的样本对这些分类模型进行测试,保留模型对各个类别的分类准确率acci,其中,acci表示每个分类模型对第i个类别正确分类的样本数目占该类样本总数的比例,将各类别分类准确率求和取平均值得到平均每类准确率mava:
然后,以mava作为评分标准,重复实验多次,将评分值按从大到小顺序排列,挑选出评分值前3名对应采样数目numi1、numi2、numi3,根据转化公式num'=num/count(lesstr)*count(less)得到最终采样数目numi'1、numi'2、numi'3,其中,num为转化前采样数目,num'为转化后采样数目,count(lesstr)为五折中的少数类训练样本总数。
上述方法中,据此综合过采样与欠采样技术平衡二类数据集以建立多个二分类子模型,通过平均法集成子模型获得二分类模型的方法为:比较每个二类数据集di中正负类样本数目大小,若正负类样本数目相等,则不作任何处理,若正负类样本数目不等,则对两类中的多数类样本进行随机欠采样,利用kmeans-smote方法对少数类样本进行过采样,且满足采样后的正负类样本数目均等于采样数目num';基于bagging思想,重复采样多次,组合每次采样后的正负类样本生成多份正负样本数目平衡的二类数据集,通过训练这些数据集得到多个二分类子模型,即每个二类数据集对应一个二分类模型,该模型中包含多个子模型,最后,根据平均法集成每个二分类问题对应的所有子模型得到最终的二分类模型hi(x):
其中,i表示第i个二分类模型,i=1,2,...,m,hit(x)表示第i个二分类模型对应的第t个子模型,t=1,2,...,t,t为每个二类数据集采样后的平衡子集总数。
上述方法中,根据所有二分类模型输出结果获取测试样本在一对多框架下决策空间位置信息,据此分别制定针对空白区、交叉区、正常区域的类别判定策略以确定样本最终类别的方法为:每个二分类模型对测试样本进行预测,可得到输出向量r={r1,r2,...,ri,...,rm},ri表示第i个二分类模型的输出结果,由于每个分类模型中只包含正类与负类,若预测的正类概率值pi+大于负类概率值pi-,则令ri=1,反之则令ri=0,考虑所有二分类模型对一个测试样本的预测结果,则会出现三种情况,第一种情况为只有一个二分类模型对测试样本的预测结果满足pi+>pi-,即
【附图说明】
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。
图1是本发明实施例所提出的基于自适应平衡集成与动态分层决策的多分类方法的流程示意图;
【具体实施方式】
为了更好的理解本发明的技术方案,下面结合附图对本发明实施例进行详细描述。
应当明确,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本发明实施例给出基于自适应平衡集成与动态分层决策的多分类方法,请参考图1,其为本发明实施例所提出的基于自适应平衡集成与动态分层决策的多分类方法的流程示意图,如图1所示,该方法包括以下步骤:
步骤101,根据一对多分解策略将原始数据集转化为多个二类数据集,以每个二类数据集中多数类样本与少数类样本数目分别作为参数区间上下限,平均每类准确率为评分标准,通过网格搜索法获得各子集采样数。
具体的,假定数据集d的类别总数为m,根据一对多分解策略将原始数据集d转化为m个二类数据集di,其中,i=1,2,...,m,每个二类数据集中正类对应某一类别,负类对应剩余所有类别;根据网格搜索法分别对每个di在{count(less),count(more)}内进行采样数目搜索,其中count(more)为多数类训练样本总数、count(less)为少数类训练样本总数,具体地将每个di随机划分为五折,每四折作为训练集dtr={lesstr,moretr},lesstr为少数类训练样本,moretr为多数类训练样本,每一折作为测试集,设定间距d,其中,0<d<count(moretr),从参数区间{count(lesstr),count(moretr)}内等间距确定采样数目num,据此平衡每四折对应的样本数据以建立多个分类模型,其中,count(moretr)为moretr中样本总数、count(lesstr)为lesstr中样本总数,利用剩余一折包含的样本对这些分类模型进行测试,保留模型对各个类别的分类准确率acci,其中,acci表示每个分类模型对第i个类别正确分类的样本数目占该类样本总数的比例,将各类别分类准确率求和取平均值得到平均每类准确率mava:
然后,以mava作为评分标准,重复实验多次,将评分值按从大到小顺序排列,挑选出评分值前3名对应采样数目numi1、numi2、numi3,根据转化公式num'=num/count(lesstr)*count(less)得到最终采样数目numi'1、numi'2、numi'3,其中,num为转化前采样数目,num'为转化后采样数目,count(lesstr)为五折中的少数类训练样本总数。
步骤102,据此综合过采样与欠采样技术平衡二类数据集以建立多个二分类子模型,通过平均法集成子模型获得二分类模型。
具体的,比较每个二类数据集di中正负类样本数目大小,若正负类样本数目相等,则不作任何处理,若正负类样本数目不等,则对两类中的多数类样本进行随机欠采样,利用kmeans-smote方法对少数类样本进行过采样,且满足采样后的正负类样本数目均等于采样数目num';基于bagging思想,重复采样多次,组合每次采样后的正负类样本生成多份正负样本数目平衡的二类数据集,通过训练这些数据集得到多个二分类子模型,即每个二类数据集对应一个二分类模型,该模型中包含多个子模型,最后,根据平均法集成每个二分类问题对应的所有子模型得到最终的二分类模型hi(x):
其中,i表示第i个二分类模型,i=1,2,...,m,hit(x)表示第i个二分类模型对应的第t个子模型,t=1,2,...,t,t为每个二类数据集采样后的平衡子集总数。
算法1为步骤101与步骤102中平衡数据集与二分类模型构建过程的伪代码:
步骤103,根据所有二分类模型输出结果获取测试样本在一对多框架下决策空间位置信息,据此分别制定针对空白区、交叉区、正常区域的类别判定策略以确定样本最终类别。
具体的,每个二分类模型对测试样本进行预测,可得到输出向量r={r1,r2,...,ri,...,rm},ri表示第i个二分类模型的输出结果,由于每个分类模型中只包含正类与负类,若预测的正类概率值pi+大于负类概率值pi-,则令ri=1,反之则令ri=0,考虑所有二分类模型对一个测试样本的预测结果,则会出现三种情况,第一种情况为只有一个二分类模型对测试样本的预测结果满足pi+>pi-,即
算法2为步骤103中测试样本类别判定过程的伪代码:
表一是本发明实施例给出基于自适应平衡集成方法解决8例keel公开数据集多分类任务时,mava值的对比实验结果,其中,本发明实施例中对比方法是典型解决不平衡分类问题的underbagging方法、kmeans-smote方法与bagging-rb方法,基准分类器为随机森林算法,所有对比方法均在一对多框架下进行实验。由表一可以得出,本发明所提出的方法在公开数据集中相比于对比方法在mava值均有所提高。特别的,提出方法在太阳耀斑数据集上的提升值最高,达到2.17%。本发明实施例所提出的方法在解决一对多框架下的正负样本数据不平衡取得了一定突破。
表一
表二是本发明实施例给出基于动态分层决策的结果聚合方法解决8例keel公开数据集分类任务时,mava值的对比实验结果,其中,本发明实施例中对比方法是典型解决一对多框架结果聚合问题的最大置信度与动态排序方法,基准分类器为随机森林算法。由表二可以得出,本发明所提出的方法在大部分公开数据集中相比于对比方法在mava值均有所提高。特别的,提出方法在玻璃数据集上的提升值最高,达到1.63%。本发明实施例所提出的方法在对二分类模型输出结果的聚合取得了一定突破。
表二
表三是本发明实施例给出基于自适应平衡集成与动态分层决策的多分类方法解决8例keel公开数据集分类任务时,mava值的对比实验结果,其中,本发明实施例中对比方法是典型解决多类不平衡数据分类问题的des-mi、ovo-smb和ovo-easy方法,基准分类器为随机森林算法。由表三可以得出,本发明所提出的方法在大部分公开数据集中相比于对比方法在mava值均有所提高。特别的,提出方法在玻璃数据集上的提升值最高,达到4.72%。本发明实施例所提出的方法在对多类数据集的分类取得了一定突破。
表三
综上所述,本发明实施例具有以下有益效果:
本发明实施的技术方案中,根据一对多分解策略将原始数据集转化为多个二类数据集,以每个二类数据集中多数类样本与少数类样本数目分别作为参数区间上下限,平均每类准确率为评分标准,通过网格搜索法获得各子集采样数;据此综合过采样与欠采样技术平衡二类数据集以建立多个二分类子模型,通过平均法集成子模型获得二分类模型;根据所有二分类模型输出结果获取测试样本在一对多框架下决策空间位置信息,据此分别制定针对空白区、交叉区、正常区域的类别判定策略以确定样本最终类别。根据本发明实施例提供的技术方案,可以有效解决一对多框架下正负样本数目不平衡问题,减少对二分类模型输出置信度值的依赖,提高模型对所有类别的整体识别率。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!