基于互联网模式下多源数据分析的就业推荐方法及系统与流程
本发明涉及大数据技术领域,尤其涉及一种基于互联网模式下多源数据分析的就业推荐方法及一种基于互联网模式下多源数据分析的就业推荐系统。
背景技术:
在大数据技术飞速发展的背景下,数据价值越发显得重要,在大规模并行处理(mpp)数据库、数据挖掘、分布式文件系统(hdfs)、分布式数据库(hive、hbase)、云计算平台、互联网和可扩展的存储系统技术成熟并大规模应用的同时,各行业均在追求和研究如何有效利用数据,使现有数据资产通过分析挖掘让企业或机构,具有更强的决策力、洞察发现力和流程优化能力来适应高增长率和多样化的发展。
如今人们正处于信息爆炸的时代。从追求和寻找信息,已经发展到了筛选、处理、分析大量而复杂且以指数级增长的数据的阶段。很多公司如ibm、emc、teradata、google等公司正把大数据和云计算作为公司的长远发展战略和新的业务增长点。
大量的数据时代也随之带来了信息价值密度低的问题,用户需要花费大量时间进行有价值信息的筛选,从而降低了办事的效率;而此时技术领域则在探索使用技术的手段实现信息的高效筛选及推荐,从而实现所需信息的精准匹配和推荐;并不断探索推荐算法和技术在实际场景的应用。
目前,我国大学生就业难已经成为国家和社会重点关注的问题,利用大数据技术实现精准的毕业生和企业岗位的双向推送成为刚性需求;目前市场上还没有真正的产品实现该功能需求,大多依靠简单的关键字匹配或依靠单一数据来源分析的信息检索技术完成,面临效率低、准确度不高等问题。
技术实现要素:
本发明所要解决的技术问题在于,提供一种基于互联网模式下多源数据分析的就业推荐方法及系统,可实现人才与岗位之间的精准推送。
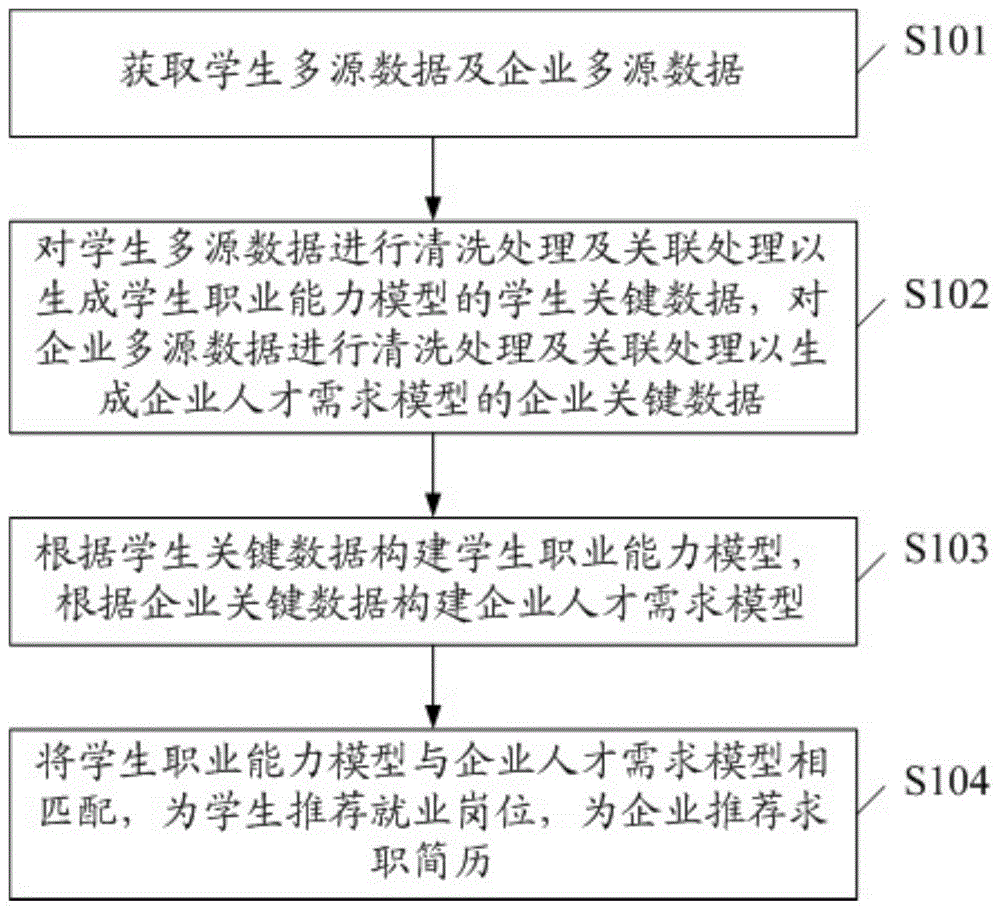
为了解决上述技术问题,本发明提供了一种基于互联网模式下多源数据分析的就业推荐方法,包括:获取学生多源数据及企业多源数据;对学生多源数据进行清洗处理及关联处理以生成学生职业能力模型的学生关键数据,对企业多源数据进行清洗处理及关联处理以生成企业人才需求模型的企业关键数据;根据学生关键数据构建学生职业能力模型,根据企业关键数据构建企业人才需求模型;将学生职业能力模型与企业人才需求模型相匹配,为学生推荐就业岗位,为企业推荐求职简历。
作为上述方案的改进,所述获取学生多源数据的方法包括:获取校园环境中的系统数据,所述系统数据包括学生基本信息、专业信息、课程信息、成绩信息、荣誉信息、特长信息及习惯信息;获取学生简历填写的求职数据,所述求职数据包括意向信息、能力信息及经验信息;获取学生在就业平台的交互数据,所述交互数据包括点击行为信息、收藏行为信息、浏览行为信息、投递行为信息及订阅行为信息;获取学生在就业平台进行的职业测评数据,所述职业测评数据包括性格趋向信息、思维趋向信息及岗位趋向信息。
作为上述方案的改进,所述根据学生关键数据构建学生职业能力模型的方法包括:根据系统数据生成模型基本因子;根据求职数据生成能力指标因子;根据交互数据生成求职意向因子;根据职业测评数据生成推荐参考因子;根据所述模型基本因子、能力指标因子、求职意向因子、推荐参考因子及各因子的预设权重参数,构建学生职业能力模型。
作为上述方案的改进,所述获取企业多源数据的方法包括:通过网络爬虫获取企业数据,所述企业数据包括企业基本信息、企业发布岗位信息、岗位描述信息;获取企业管理人员对简历的搜索数据,所述搜索数据包括关键词信息、搜索频率信息、搜索间隔信息、简历筛选查看信息。
作为上述方案的改进,所述根据企业关键数据构建企业人才需求模型的方法包括:根据企业数据生成岗位要求因子;根据搜索数据生成企业需求因子;根据所述岗位要求因子、企业需求因子及各因子的预设权重参数,构建企业职业能力模型。
作为上述方案的改进,所述基于互联网模式下多源数据分析的毕业生就业推荐方法,还包括:根据学生对所推荐的就业岗位的反馈情况及企业对所推荐的求职简历的反馈情况,优化权重参数。
相应地,本发明还提供了一种基于互联网模式下多源数据分析的就业推荐系统,包括:多源数据获取模块,用于获取学生多源数据及企业多源数据;关键数据处理模块,用于对学生多源数据进行清洗处理及关联处理以生成学生职业能力模型的学生关键数据,并用于对企业多源数据进行清洗处理及关联处理以生成企业人才需求模型的企业关键数据;模型构建模块,用于根据学生关键数据构建学生职业能力模型,并用于根据企业关键数据构建企业人才需求模型;推荐模块,用于将学生职业能力模型与企业人才需求模型相匹配,为学生推荐就业岗位,为企业推荐求职简历。
作为上述方案的改进,所述多源数据获取模块包括:系统数据获取单元,用于获取校园环境中的系统数据;求职数据获取单元,用于获取学生简历填写的求职数据;交互数据获取单元,用于获取学生在就业平台的交互数据;职业测评数据获取单元,用于获取学生在就业平台进行的职业测评数据;企业数据获取单元,用于通过网络爬虫获取企业数据;搜索数据获取单元,用于获取企业管理人员对简历的搜索数据。
作为上述方案的改进,所述模型构建模块包括:模型基本因子生成单元,用于根据系统数据生成模型基本因子;能力指标因子生成单元,用于根据求职数据生成能力指标因子;求职意向因子生成单元,用于根据交互数据生成求职意向因子;推荐参考因子生成单元,用于根据职业测评数据生成推荐参考因子;岗位要求因子生成单元,用于根据企业数据生成岗位要求因子;企业需求因子生成单元,用于根据搜索数据生成企业需求因子;学生模型构建单元,用于根据所述模型基本因子、能力指标因子、求职意向因子、推荐参考因子及各因子的预设权重参数,构建学生职业能力模型;企业模型构建单元,用于根据所述岗位要求因子、企业需求因子及各因子的预设权重参数,构建企业职业能力模型。
作为上述方案的改进,所述基于互联网模式下多源数据分析的毕业生就业推荐系统还包括:优化模块,用于根据学生对所推荐的就业岗位的反馈情况及企业对所推荐的求职简历的反馈情况,优化权重参数。
实施本发明,具有如下有益效果:
本发明通过获取学生多源数据及企业多源数据,感知和清洗原始数据中关键数据字段,形成学生关键数据及企业关键数据,同时通过多维度数据关联,逻辑判断纠错,数据深度挖掘等大数据技术构建学生职业能力模型及企业人才需求模型,再通过推荐算法,实现学生职业能力模型与企业人才需求模型之间的双向匹配,并通过用户操作行为反馈,优化匹配算法,从而实现人才与岗位之间的精准推送。
附图说明
图1是本发明基于互联网模式下多源数据分析的就业推荐方法的流程图;
图2是本发明中按对称逻辑函数进行权重衰减的示意图;
图3是本发明基于互联网模式下多源数据分析的就业推荐系统的第一实施例结构示意图;
图4是本发明中多源数据获取模块的结构示意图;
图5是本发明中模型构建模块的结构示意图;
图6是本发明基于互联网模式下多源数据分析的就业推荐系统的第二实施例结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。仅此声明,本发明在文中出现或即将出现的上、下、左、右、前、后、内、外等方位用词,仅以本发明的附图为基准,其并不是对本发明的具体限定。
如图1所示,图1是本发明基于互联网模式下多源数据分析的就业推荐方法的流程图,包括:
s101,获取学生多源数据及企业多源数据。
具体地,所述获取学生多源数据的方法包括:
(1)获取校园环境中的系统数据。所述系统数据包括学生基本信息、专业信息、课程信息、成绩信息、荣誉信息、特长信息及习惯信息,但不以此为限制。所述系统数据可从学工系统及教务系统中获取,具体地,可以通过学工系统获取学生基础信息、荣誉信息、特长信息及习惯信息,通过教务系统获取学生专业信息、课程信息及成绩信息等,通过有线和无线网络系统获取学生的网络使用偏好信息。
(2)获取学生简历填写的求职数据。所述求职数据包括意向信息、能力信息及经验信息,但不以此为限制。所述求职数据可从学生填写的简历中获取。
(3)获取学生在就业平台的交互数据。所述交互数据包括点击行为信息、收藏行为信息、浏览行为信息、投递(简历投递)行为信息及订阅行为信息,但不以此为限制。所述交互数据可通过学生在就业平台的操作中获取。
(4)获取学生在就业平台进行的职业测评数据。所述职业测评数据包括性格趋向信息、思维趋向信息及岗位趋向信息(即适合的职业和岗位信息),但不以此为限制。所述专业测评数据可通过学生在就业平台上所进行的职业测试中获取。
具体地,所述获取企业多源数据的方法包括:
(1)通过网络爬虫获取企业数据。所述企业数据包括企业基本信息、企业发布岗位信息、岗位描述信息,但不以此为限制。
(2)获取企业管理人员对简历的搜索数据。所述搜索数据包括关键词信息、搜索频率信息、搜索间隔信息、简历筛选查看信息,但不以此为限制。
因此,本发明可通过数据的多源采集,构建庞大的数据库,方便模型的准确构建。
s102,对学生多源数据进行清洗处理及关联处理以生成学生职业能力模型的学生关键数据,对企业多源数据进行清洗处理及关联处理以生成企业人才需求模型的企业关键数据。
本发明需对学生多源数据及企业多源数据进行清洗处理(如,处理乱码、清除格式编码、清理邮箱、清理电话等敏感信息),提取有效的学生关键数据及企业关键数据。同时,还需对学生多源数据及企业多源数据进行多维度的数据关联,逻辑判断纠错,实现多源数据的深度挖掘。
s103,根据学生关键数据构建学生职业能力模型,根据企业关键数据构建企业人才需求模型。
具体地,所述根据学生关键数据构建学生职业能力模型的方法包括:
k11,根据系统数据生成模型基本因子。
本发明采用精准对比的方式,根据系统数据,对基本的相对确定的数据(如,性别信息、年龄信息、专业信息、课程信息、成绩信息等)进行处理,以生成模型基本因子。
k12,根据求职数据生成能力指标因子。
k13,根据交互数据生成求职意向因子。
本发明通过自然语言处理技术对交互数据进行处理,将文本信息进行提取和分词,并生成求职意向因子。
k14,根据职业测评数据生成推荐参考因子。
本发明通过自然语言处理技术对职业测评数据进行处理,将文本信息进行提取和分词,构建合适岗位的列表,并生成推荐参考因子。
k15,根据所述模型基本因子、能力指标因子、求职意向因子、推荐参考因子及各因子的预设权重参数,构建学生职业能力模型。
需要说明的是,每一因子均对应一预设权重参数,本发明根据步骤k11~k14所生成的模型基本因子、能力指标因子、求职意向因子、推荐参考因子及各因子所对应的预设权重参数,构建学生职业能力模型。
进行大量的数据分析和岗位模型建立时,常需要将采集到的数据转换为对岗位的文本描述,因此需利用自然语言处理技术,实现对岗位描述的知识图谱的构建,从而分析获得岗位需求能力的模型向量及关系知识图谱。本发明通过自然语言处理技术对数据进行处理,将文本信息进行提取和分词,并生成相应的因子。
具体地,本发明中的自然语言分析语料库包括:人民日报语料库,wiki百科语料库,京东评论语料库及历史收集的招聘信息语料库。
使用前,数据(如,求职数据、交互数据、职业测评数据)需通过必要的清洗(如,处理乱码、清除格式编码、清理邮箱、清理电话等敏感信息)—>利用n-gram+crf+hmm技术构建分词器(如,采用主流的分词包ansj,jieba)—>通过wiki百科词条获取初始的专有词条作为词典,完成分词工作—>分词完成后,清洗特殊的标点符号,通过word2vec完成词向量锻炼—>此时完成自然语言处理基本步骤。
例如,专业信息处理:通过收集专业描述(一个专业一个简短描述,包括:是什么,学了什么,有什么基本能力,以后能做什么工作)。通过分词器分词—>保留名词,动词等语素—>提取关键字—>利用关键字权重与词向量表结合,获取专业向量。
又如,工作经历/项目经历:收集简历中的工作经历/项目经历,包括工作岗位,内容,开始时间与结束时间,工作岗位与工作内容,按自然语言处理步骤进行向量化。
工作时间,按越靠近当前时间点,给越高的预设权重参数。如图2所示,若需要考核距今5年的工作经验,按对称逻辑函数进行权重衰减。假如6是当前时间点,4为是用户开始某个工作的时间点,期间经历了4~6之间的时间,则以[4,6]区间的函数值的最大值f(6)*(6~4)作为预设权重参数;同样,假如2~4之间是做的另一份工作,则以f(4)*(4~2)作为预设权重参数,最后把所有工作的向量*各自的预设权重参数,求和,作为工作经历的向量表达。
因此,本发明通过多维度的数据关联,逻辑判断纠错,数据深度挖掘等大数据技术构建学生职业能力模型。
具体地,所述根据企业关键数据构建企业人才需求模型的方法包括:
k21,根据企业数据生成岗位要求因子。
本发明根据企业数据(如,招聘岗位类型、招聘人数、就职区域、岗位描述信息等),通过分词和关联,生成岗位要求因子。
k22,根据搜索数据生成企业需求因子。
k23,根据所述岗位要求因子、企业需求因子及各因子的预设权重参数,构建企业职业能力模型。
例如,通过网络爬虫工具获取企业发布岗位信息及岗位描述信息,并把企业发布岗位信息(即岗位名称)与岗位描述信息结合,通过分词器分词—>保留名词,动词等语素—>提取关键字—>利用关键字的预设权重参数与词向量表结合,获取岗位向量。
因此,本发明通过多维度的数据关联,逻辑判断纠错,数据深度挖掘等大数据技术构建企业人才需求模型。
s104,将学生职业能力模型与企业人才需求模型相匹配,为学生推荐就业岗位,为企业推荐求职简历。
例如,分别计算数据因子:基础结构化因子(a),岗位与专业因子(b),岗位与工作经历因子(c),岗位与项目经历因子(d);同时,预设权重参数:基础结构化权重(wa)50,岗位与专业权重(wb)50,岗位与工作经历权重(wc)50,岗位与项目经历权重(wd)50;总体匹配度=(wa*a+wb*b+wc*c+wd*d)/(wa+wb+wc+wd),按匹配度大小给用户推荐岗位。
又如,系统数据中显示当学生为研究生,则学历限制在“研究生”、“本科”“专科”及“无限制”四个等级的岗位会标识为匹配成功,匹配成功的项,乘以相应的预设权重参数,求和,即可获取基础结构化信息的匹配度。
因此,本发明能有效地将学生职业能力模型与企业人才需求模型相结合,实现学生职业能力因子与企业人才需求因子的精准匹配,并计算出相应的匹配度,为学生推荐就业岗位topn,为企业推荐求职简历topn。
进一步,所述基于互联网模式下多源数据分析的毕业生就业推荐方法还包括:根据学生对所推荐的就业岗位的反馈情况及企业对所推荐的求职简历的反馈情况,优化权重参数。
为了不断优化权重参数的权重,本发明根据学生及企业的反馈情况,采用机器学习的方式,实现推荐算法的自主优化,从而校验推荐准确度,实现更为精准的推荐。
例如:当用户出现点击行为,若点击了一个岗位,匹配度为(a,b,c,d)=(30,50,80,70),则更新预设权重参数(wa,wb,wc,wd)=(50+30,50+50,50+80,50+70)=(80,100,130,120)。因此,随着用户点击次数增多,权重参数也会累积更新,逐步逼近用户的真实考虑倾向。
又如,当用户持续1个月没出现点击行为,则累积权重参数按比例衰减,本发明的衰减策略是往后每个月衰减一半,直到回到十位数。如(800,1000,1300,1200)=>(400,500,650,600)=>...=>(50,62.5,81.25,75),此操作主要是用于回避用户闲置一定时间后,就业倾向改变,而之前过大的权重参数会导致对新的点击行为不敏感。
由上可知,本发明通过获取学生多源数据及企业多源数据,感知和清洗原始数据中关键数据字段,形成学生关键数据及企业关键数据,同时通过多维度数据关联,逻辑判断纠错,数据深度挖掘等大数据技术构建学生职业能力模型及企业人才需求模型,再通过推荐算法,实现学生职业能力模型与企业人才需求模型之间的双向匹配,并通过用户操作行为反馈,优化匹配算法,从而实现人才与岗位之间的精准推送。
参见图3,图3显示了本发明基于互联网模式下多源数据分析的毕业生就业推荐系统100的第一实施例,其包括:
多源数据获取模块1,用于获取学生多源数据及企业多源数据。
关键数据处理模块2,用于对学生多源数据进行清洗处理及关联处理以生成学生职业能力模型的学生关键数据,并用于对企业多源数据进行清洗处理及关联处理以生成企业人才需求模型的企业关键数据。需要说明的是,关键数据处理模块2用于对学生多源数据及企业多源数据进行清洗处理(如,处理乱码、清除格式编码、清理邮箱、清理电话等敏感信息),提取有效的学生关键数据及企业关键数据;同时,还用于对学生多源数据及企业多源数据进行多维度的数据关联,逻辑判断纠错,实现多源数据的深度挖掘。
模型构建模块3,用于根据学生关键数据构建学生职业能力模型,并用于根据企业关键数据构建企业人才需求模型。
推荐模块4,用于将学生职业能力模型与企业人才需求模型相匹配,为学生推荐就业岗位,为企业推荐求职简历。
例如,分别计算数据因子:基础结构化因子(a),岗位与专业因子(b),岗位与工作经历因子(c),岗位与项目经历因子(d);同时,预设权重参数:基础结构化权重(wa)50,岗位与专业权重(wb)50,岗位与工作经历权重(wc)50,岗位与项目经历权重(wd)50;总体匹配度=(wa*a+wb*b+wc*c+wd*d)/(wa+wb+wc+wd),按匹配度大小给用户推荐岗位。
又如,系统数据中显示当学生为研究生,则学历限制在“研究生”、“本科”“专科”及“无限制”四个等级的岗位会标识为匹配成功,匹配成功的项,乘以相应的预设权重参数,求和,即可获取基础结构化信息的匹配度。
因此,本发明能有效地将学生职业能力模型与企业人才需求模型相结合,实现学生职业能力因子与企业人才需求因子的精准匹配,并计算出相应的匹配度,为学生推荐就业岗位topn,为企业推荐求职简历topn。
如图4所示,所述多源数据获取模块1包括:
系统数据获取单元11,用于获取校园环境中的系统数据。所述系统数据包括学生基本信息、专业信息、课程信息、成绩信息、荣誉信息、特长信息及习惯信息,但不以此为限制。所述系统数据可从学工系统及教务系统中获取,具体地,可以通过学工系统获取学生基础信息、荣誉信息、特长信息及习惯信息,通过教务系统获取学生专业信息、课程信息及成绩信息等,通过有线和无线网络系统获取学生的网络使用偏好信息。
求职数据获取单元12,用于获取学生简历填写的求职数据。所述求职数据包括意向信息、能力信息及经验信息,但不以此为限制。所述求职数据可从学生填写的简历中获取。
交互数据获取单元13,用于获取学生在就业平台的交互数据。所述交互数据包括点击行为信息、收藏行为信息、浏览行为信息、投递(简历投递)行为信息及订阅行为信息,但不以此为限制。所述交互数据可通过学生在就业平台的操作中获取。
职业测评数据获取单元14,用于获取学生在就业平台进行的职业测评数据。所述职业测评数据包括性格趋向信息、思维趋向信息及岗位趋向信息(即适合的职业和岗位信息),但不以此为限制。所述专业测评数据可通过学生在就业平台上所进行的职业测试中获取。
企业数据获取单元15,用于通过网络爬虫获取企业数据。所述企业数据包括企业基本信息、企业发布岗位信息、岗位描述信息,但不以此为限制。
搜索数据获取单元16,用于获取企业管理人员对简历的搜索数据。所述搜索数据包括关键词信息、搜索频率信息、搜索间隔信息、简历筛选查看信息,但不以此为限制。
因此,本发明可通过多源数据获取模块1实现数据的多源采集,构建庞大的数据库,方便模型的准确构建。
如图5所示,所述模型构建模块3包括:
模型基本因子生成单元31,用于根据系统数据生成模型基本因子。本发明采用精准对比的方式,根据系统数据,对基本的相对确定的数据(如,性别信息、年龄信息、专业信息、课程信息、成绩信息等)进行处理,以生成模型基本因子。
能力指标因子生成单元31,用于根据求职数据生成能力指标因子。
求职意向因子生成单元33,用于根据交互数据生成求职意向因子。本发明通过自然语言处理技术对交互数据进行处理,将文本信息进行提取和分词,并生成求职意向因子。
推荐参考因子生成单元34,用于根据职业测评数据生成推荐参考因子。本发明通过自然语言处理技术对职业测评数据进行处理,将文本信息进行提取和分词,构建合适岗位的列表,并生成推荐参考因子。
岗位要求因子生成单元35,用于根据企业数据生成岗位要求因子。岗位要求因子生成单元35根据企业数据(如,招聘岗位类型、招聘人数、就职区域、岗位描述信息等),通过分词和关联,生成岗位要求因子。
企业需求因子生成单元36,用于根据搜索数据生成企业需求因子。
学生模型构建单元37,用于根据所述模型基本因子、能力指标因子、求职意向因子、推荐参考因子及各因子的预设权重参数,构建学生职业能力模型。需要说明的是,每一因子均对应一预设权重参数,本发明根据步骤k11~k14所生成的模型基本因子、能力指标因子、求职意向因子、推荐参考因子及各因子所对应的预设权重参数,构建学生职业能力模型。
企业模型构建单元38,用于根据所述岗位要求因子、企业需求因子及各因子的预设权重参数,构建企业职业能力模型。
进行大量的数据分析和岗位模型建立时,常需要将采集到的数据转换为对岗位的文本描述,因此需利用自然语言处理技术,实现对岗位描述的知识图谱的构建,从而分析获得岗位需求能力的模型向量及关系知识图谱。本发明通过自然语言处理技术对数据进行处理,将文本信息进行提取和分词,并生成相应的因子。
具体地,本发明中的自然语言分析语料库包括:人民日报语料库,wiki百科语料库,京东评论语料库及历史收集的招聘信息语料库。
使用前,数据(如,求职数据、交互数据、职业测评数据、企业数据、搜索数据)需通过必要的清洗(如,处理乱码、清除格式编码、清理邮箱、清理电话等敏感信息)—>利用n-gram+crf+hmm技术构建分词器(如,采用主流的分词包ansj,jieba)—>通过wiki百科词条获取初始的专有词条作为词典,完成分词工作—>分词完成后,清洗特殊的标点符号,通过word2vec完成词向量锻炼—>此时完成自然语言处理基本步骤。
例如,专业信息处理:通过收集专业描述(一个专业一个简短描述,包括:是什么,学了什么,有什么基本能力,以后能做什么工作)。通过分词器分词—>保留名词,动词等语素—>提取关键字—>利用关键字权重与词向量表结合,获取专业向量。
又如,工作经历/项目经历:收集简历中的工作经历/项目经历,包括工作岗位,内容,开始时间与结束时间,工作岗位与工作内容,按自然语言处理步骤进行向量化。
工作时间,按越靠近当前时间点,给越高的预设权重参数。如图2所示,若需要考核距今5年的工作经验,按对称逻辑函数进行权重衰减。假如6是当前时间点,4为是用户开始某个工作的时间点,期间经历了4~6之间的时间,则以[4,6]区间的函数值的最大值f(6)*(6~4)作为预设权重参数;同样,假如2~4之间是做的另一份工作,则以f(4)*(4~2)作为预设权重参数,最后把所有工作的向量*各自的预设权重参数,求和,作为工作经历的向量表达。
再如,通过网络爬虫工具获取企业发布岗位信息及岗位描述信息,并把企业发布岗位信息(即岗位名称)与岗位描述信息结合,通过分词器分词—>保留名词,动词等语素—>提取关键字—>利用关键字的预设权重参数与词向量表结合,获取岗位向量。
因此,本发明通过多维度的数据关联,逻辑判断纠错,数据深度挖掘等大数据技术构建学生职业能力模型及企业人才需求模型。
参见图6,图6显示了本发明基于互联网模式下多源数据分析的毕业生就业推荐系统的第二实施例,与图3所示的第一实施例不同的是,本实施例中,所述基于互联网模式下多源数据分析的毕业生就业推荐系统还包括:优化模块5,用于根据学生对所推荐的就业岗位的反馈情况及企业对所推荐的求职简历的反馈情况,优化权重参数。
为了不断优化权重参数的权重,本发明根据学生及企业的反馈情况,采用机器学习的方式,实现推荐算法的自主优化,从而校验推荐准确度,实现更为精准的推荐。
例如:当用户出现点击行为,若点击了一个岗位,匹配度为(a,b,c,d)=(30,50,80,70),则更新预设权重参数(wa,wb,wc,wd)=(50+30,50+50,50+80,50+70)=(80,100,130,120)。因此,随着用户点击次数增多,权重参数也会累积更新,逐步逼近用户的真实考虑倾向。
又如,当用户持续1个月没出现点击行为,则累积权重参数按比例衰减,本发明的衰减策略是往后每个月衰减一半,直到回到十位数。如(800,1000,1300,1200)=>(400,500,650,600)=>...=>(50,62.5,81.25,75),此操作主要是用于回避用户闲置一定时间后,就业倾向改变,而之前过大的权重参数会导致对新的点击行为不敏感。
进一步,所述基于互联网模式下多源数据分析的毕业生就业推荐系统还包括:显示单元6,用于将推荐算法匹配的结果展示给使用者。
由上可知,本发明通过获取学生多源数据及企业多源数据,感知和清洗原始数据中关键数据字段,形成学生关键数据及企业关键数据,同时通过多维度数据关联,逻辑判断纠错,数据深度挖掘等大数据技术构建学生职业能力模型及企业人才需求模型,再通过推荐算法,实现学生职业能力模型与企业人才需求模型之间的双向匹配,并通过用户操作行为反馈,优化匹配算法,从而实现人才与岗位之间的精准推送。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!