一种基于深度学习的超短时风功率预测方法与流程
本发明涉及风场风功率预测
技术领域:
,具体涉及一种基于深度学习的超短时风功率预测方法。
背景技术:
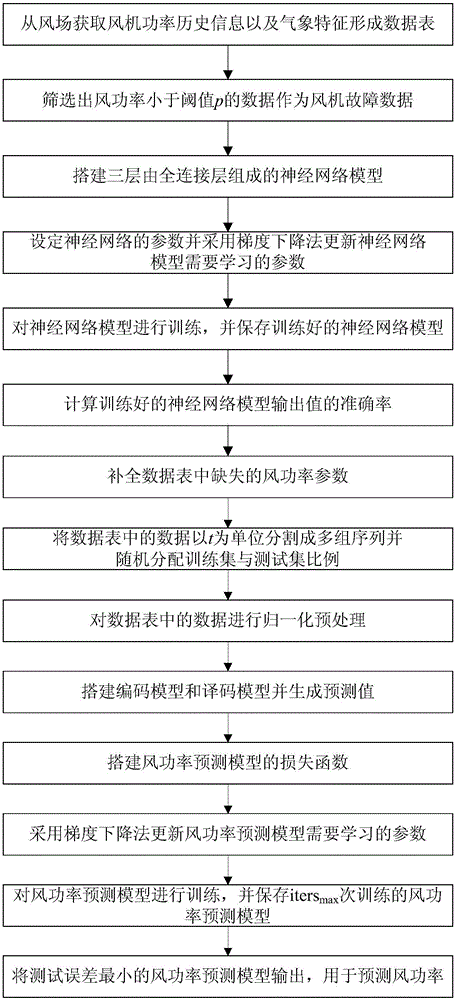
:风电作为一种低成本、无污染、可再生能源,受到世界各国的青睐。以风电为代表的可再生能源,发展很快。据全球风能理事会(gwec)统计数据显示,全球风电累计装机能力呈现逐年递增的趋势。因为风速变化的随机性,风电场出力具有很强的不稳定性,并且大型风力涡轮机不能储存电能,而且不受人为控制。这些客观存在的事实表明,虽然风力发电具有许多显而易见的优点,但同时也将造成负面影响,这些问题在某些程度上限制了风力发电发展的步伐。因此做好风电发电的预测和调控是风电并网稳定运行和有效消纳的重要条件。风功率预测按照预测时间尺度可以分为超短期预测和短期预测,超短期预测一般是预测以小时为单位,短期预测是预测以天为单位。这些预测数据需要上报到上级考核系统中用于电网调度。在实际预测中,因为风电随机性的特点导致上报的预测误差比较大,准确度比较低。因此为了解决大规模风电并网问题,提高风电场与电力系统的协调运行的稳定性,需要解决风功率预测准确性这个关键技术问题。风功率预测方法一般主要有物理方法和统计方法。物理模型的方法主要是根据风电场的地理信息和气象信息,预测出未来一段时间内风电场的气象数据,从而预测出风电场的输出功率。统计方法是根据历史风功率和气象数据信息对风电场输出功率进行预测,常用的预测方法有人工神经元网络、蚁群算法和支持向量机(svm)方法等。目前大部分风功率预测方法都是利用风电场的气象数据和历史数据对整个风电场的输出功率进行预测,没有考虑历史风速的时间序列的相关性。专利zl201510510342.2将小波分解和支持向量机相结合,准确率只达到82.8%,专利zl201510958548.1将遗传算法和神经网络相结合,但准确率也只有81.4%。技术实现要素:针对现有技术存在的问题,本发明提供一种基于深度学习的超短时风功率预测方法,来解决风功率的不确定性,降低由于风电随机性导致的上报预测误差,提高风功率预测的准确性,使电力系统更平稳经济调度。为了实现上述目的,一种基于深度学习的超短时风功率预测方法,包括以下步骤:步骤1:从风场获取风机功率历史信息以及包括风速、风向、温度、湿度构成的气象特征形成数据表;步骤2:补全数据表中缺失的风功率参数,具体步骤如下:步骤2.1:筛选出风功率小于阈值p的数据作为风机故障数据;步骤2.2:搭建三层由全连接层组成的神经网络模型;所述神经网络模型的计算公式如下所示:y=ξ(wx+b);其中,y表示每一层神经网络的输出,最后一层输出的y值为相应风功率,ξ为神经网络的激活函数,x表示每一层神经网络的输入特征,w为神经网络需要学习的权重,b为神经网络需要学习的偏差;步骤2.3:设定神经网络的参数,包括第一层全连接层的输出通道数l1、第二层全连接层的输出通道数l2、第三层全连接层的输出通道数l3、各全连接层的输入层数nin和各全连接层的输出层数nout,初始化神经网络的权重在的范围内均匀分布;步骤2.4:采用梯度下降法更新神经网络模型需要学习的参数,即权重w和偏差b;步骤2.5:将数据批次设置为batch1,训练次数设置为maxt-iters,对神经网络模型进行训练,并保存maxt-iters次训练的神经网络模型;步骤2.6:计算maxt-iters次神经网络模型输出值的准确率acc,将准确率最高的神经网络模型输出;所述神经网络模型输出值的准确率acc的计算公式如下:其中,loss1为神经网络模型的损失函数,ytrue为风功率的真实值;所述神经网络模型的损失函数loss1的计算公式如下:其中,为神经网络模型的预测输出值;步骤2.7:将风机故障数据中的气象特征输入到输出的神经网络模型中,将输出的出风功率补全到数据表中;步骤3:搭建基于序列对序列的风功率预测模型,具体步骤如下:步骤3.1:以时间t为单位,将数据表中的数据分割成多组长度为l的序列,第一组序列中的温度、湿度以及该时刻的风功率作为输入特征,下一组序列中的风功率作为输出特征,随机分配训练集,测试集比例为k1∶k2;步骤3.2:对数据表中的数据进行归一化预处理;步骤3.3:搭建编码模型和译码模型并生成预测值,具体步骤如下:步骤3.3.1:搭建由k个lstm模块组成的编码模型学习序列信息,并将编码模型的隐藏层层数设置为k3,各隐藏层输出通道数设置为k4;所述lstm模块具体计算公式如下:hn=on⊙tanh(whcn+bh);in=σ(wi[inputsn-1;hn-1]+bi);fn=σ(wf[inputsn-1;hn-1]+bf);on=σ(wo[inputsn-1;hn-1]+bo);其中,inputsn表示第n层编码模型的输入,hn表示第n层编码模型隐藏层的输出,cn为第n层的记忆单元,in、fn和on均为第n层的门控开关,wh、wc、wi、wf、wo分别为模型输出h、记忆单元c、门控开关i、f、o的权重,bh、bc、bi、bf、bo分别为模型输出h、记忆单元c、门控开关i、f、o的偏差,σ为sigmoid函数,为中间变量;所述sigmoid函数σ的的计算公式如下:步骤3.3.2:将编码模型最后一个时间序列作为解码模型第一个时间序列隐藏层的输入,搭建由k个lstm模块组成的解码模型;步骤3.3.3:将解码模型每一序列隐藏层最后一层输出与权重w相乘,得到解码模型的预测值,即wx+b,其中,权重初始方式为服从n(0,1)的正态分布;步骤3.4:按照如下公式搭建风功率预测模型的损失函数loss2:步骤3.5:采用梯度下降法更新风功率预测模型需要学习的参数,即权重w和偏差b;步骤3.6:将批次设置为batch2,最大迭代次数设置为itersmax,对风功率预测模型进行训练,并保存itersmax次训练的风功率预测模型;步骤3.7:计算itersmax次风功率预测模型的测试误差accuracy,将测试误差最小的风功率预测模型输出,用于预测风功率;所述预测风功率模型的测试误差accuracy的计算公式如下:其中,mean为每一批次数据的误差平均值。优选的,所述步骤2.4和步骤3.5中更新模型参数的公式如下:其中,θiters+1为第iters+1次迭代的模型参数,α为学习率,ε为常量,giters为第iters次迭代的梯度,e[g2]iters为第iters次迭代的参数梯度平方值;所述第iters次迭代的梯度giters和参数梯度平方值e[g2]iters的计算公式如下:其中,ρ为衰减速率。优选的,所述步骤3.2中对数据进行归一化预处理的公式如下:其中,inputs_mean为输入数据的均值,n为输入数据的个数,inputsi为输入的第i个数据,inputs_std为输入数据的标准差,y_mean为输出数据的均值,yi为输出的第i个数据,y_std为输出数据的标准差。本发明的有益效果:本发明提出一种基于深度学习的超短时风功率预测方法,来解决风功率的不确定性,降低由于风电随机性导致的上报预测误差,提高风功率预测的准确性,使电力系统更平稳经济调度。附图说明图1为本发明实施例中基于深度学习的超短时风功率预测方法的流程图;图2为本发明实施例中补全数据的神经网络结构图;图3为本发明实施例中补全数据的神经网络拟合准确率曲线图;图4为本发明实施例中基于lstm的序列对序列模型的整体结构图;图5为本发明实施例中基于lstm的序列对序列模型的编码模型结构图;图6为本发明实施例中基于lstm的序列对序列模型的解码模型结构图;图7为本发明实施例中风功率预测结果对比曲线图。具体实施方式为了使本发明的目的、技术方案及优势更加清晰,下面结合附图和具体实施例对本发明做进一步详细说明。此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。一种基于深度学习的超短时风功率预测方法,流程如图1所示,具体包括以下步骤:步骤1:从风场获取风机功率历史信息以及包括风速、风向、温度、湿度构成的气象特征形成数据表。步骤2:补全数据表中缺失的风功率参数,具体步骤如下:步骤2.1:筛选出风功率小于阈值p的数据作为风机故障数据。步骤2.2:搭建三层由全连接层组成的神经网络模型。所述神经网络模型的计算公式如公式(1)所示:y=ξ(wx+b)(1)其中,y表示每一层神经网络的输出,最后一层输出的y值为相应风功率,ξ为神经网络的激活函数,x表示每一层神经网络的输入特征,w为神经网络需要学习的权重,b为神经网络需要学习的偏差。本实施例中,神经网络前两层的激活函数为relu激活函数,最后一层神经网络的激活函数为none;所述relu激活函数的计算公式如公式(2)所示:ξ=max(0,wx+b)(2)步骤2.3:设定神经网络的参数,包括第一层全连接层的输出通道数l1、第二层全连接层的输出通道数l2、第三层全连接层的输出通道数l3、各全连接层的输入层数nin和各全连接层的输出层数nout,初始化神经网络的权重在的范围内均匀分布。本实施例中,神经网络是由三层全连接层组成,神经网络的输出通道数分别设置为4,4,1,网络权重的初始化方法采用xavier方法,搭建的神经网络结构如图2所示。步骤2.4:采用梯度下降法更新神经网络模型需要学习的参数,即权重w和偏差b。所述更新模型参数的公式如公式(3)所示:其中,θiters+1为第iters+1次迭代的模型参数,α为学习率,ε为常量,girers为第iters次迭代的梯度,e[g2]iters为第iters次迭代的参数梯度平方值;所述第iters次迭代的梯度giters和参数梯度平方值e[g2]iters的计算公式如公式(4)和公式(5)所示:其中,ρ为衰减速率。本实施例中,学习率α设置为0.007,ε默认为1e-10,衰减速率ρ设置为0.92。步骤2.5:将数据批次设置为batch1,训练次数设置为maxt-iters,对神经网络模型进行训练,并保存maxt-iters次训练的神经网络模型。本实施例中,由于计算机运行内存有限,将所有数据一起训练会造成内存溢出现象发生,所以采用小批次训练方法,每次模型只训练一定批次数量的数据,故将数据批次batch1设置为16,训练次数maxt-iters设置为50000。步骤2.6:计算maxt-iters次神经网络模型输出值的准确率acc,将准确率最高的神经网络模型输出。所述神经网络模型输出值的准确率acc的计算公式如公式(6)所示:其中,loss1为神经网络模型的损失函数,ytrue为风功率的真实值;所述神经网络模型的损失函数loss1的计算公式如公式(7)所示:其中,为神经网络模型的预测输出值。本实施例中,神经网络拟合准确率如图3所示,由图3可以看出,最终测试准确率可达到80%左右。步骤2.7:将风机故障数据中的气象特征输入到输出的神经网络模型中,将输出的出风功率补全到数据表中。步骤3:搭建基于序列对序列的风功率预测模型,其结构如图4所示,具体步骤如下:步骤3.1:以时间t为单位,将数据表中的数据分割成多组长度为l的序列,第一组序列中的温度、湿度以及该时刻的风功率作为输入特征,下一组序列中的风功率作为输出特征,随机分配训练集,测试集比例为k1∶k2。本实施例中,取时间t为15min,长度l为10,测试集比例k1∶k2为8∶2,因此,将数据以每15分钟,长度为10生成一组序列作为输入,输入特征包括温度、湿度以及该时刻的风功率,下一时段15分钟,长度为10的风功率生成一组序列作为输出,输出特征只包含风功率。步骤3.2:对数据表中的数据进行归一化预处理。所述对数据进行归一化预处理的公式如公式(8)和公式(9)所示:其中,inputs_mean为输入数据的均值,n为输入数据的个数,inputsi为输入的第i个数据,inputs_std为输入数据的标准差,y_mean为输出数据的均值,yi为输出的第i个数据,y_std为输出数据的标准差。步骤3.3:搭建编码模型和译码模型并生成预测值,具体步骤如下:步骤3.3.1:搭建由k个lstm模块组成的编码模型学习序列信息,并将编码模型的隐藏层层数设置为k3,各隐藏层输出通道数设置为k4。本实施例中,取k为10,k3为3,k4为10,搭建的编码模型结构如图5所示,其中,实心圆即为lstm模块,lstm就是利用门控开关来控制所接收上一单元信息的多少,使网络可以学习更长序列的信息。选择lstm是因为相较与rnn模块,lstm可以解决梯度消失问题。所述lstm模块具体计算公式如公式(10)和公式(15)所示:hn=on⊙tanh(whcn+bh)(10)in=σ(wi[inputsn-1;hn-1]+bi)(13)fn=σ(wf[inputsn-1;hn-1]+bf)(14)on=σ(wo[inputsn-1;hn-1]+bo)(15)其中,inputsn表示第n层编码模型的输入,hn表示第n层编码模型隐藏层的输出,cn为第n层的记忆单元,in、fn和on均为第n层的门控开关,wh、wc、wi、wf、wo分别为模型输出h、记忆单元c、门控开关i、f、o的权重,bh、bc、bi、bf、bo分别为模型输出h、记忆单元c、门控开关i、f、o的偏差,σ为sigmoid函数,为中间变量;所述sigmoid函数σ的的计算公式如公式(16)所示:步骤3.3.2:将编码模型最后一个时间序列作为解码模型第一个时间序列隐藏层的输入,搭建由k个lstm模块组成的解码模型。本实施例中,解码模型结构和编码模型结构相同大致相同,都为10个lstm模块连接在一起,其结构如图6所示。本实施例中,序列对序列的风功率预测模型训练时,解码模型的输入是上一时刻的输出真实值,测试时,解码模型的输入是上一时刻的预测值。步骤3.3.3:将解码模型每一序列隐藏层最后一层输出与权重w相乘,得到解码模型的预测值,即wx+b,其中,权重初始方式为服从n(0,1)的正态分布。步骤3.4:按照公式(17)搭建风功率预测模型的损失函数loss2:步骤3.5:采用梯度下降法更新风功率预测模型需要学习的参数,即权重w和偏差b如公式(3)-公式(5)所示。本实施例中,风功率预测模型的优化方法与神经网络模型的优化方法相同,均为rmsprop,参数设定完全一致。步骤3.6:将批次设置为batch2,最大迭代次数设置为itersmax,对风功率预测模型进行训练,并保存itersmax次训练的风功率预测模型。本实施例中,在处理器为coretmi5-2400cpu@3.10ghz运行内存为4.00gb的64位台式电脑上进行小批次训练,设定批次batch2为16,最大迭代次数itersmax为10000次,训练模型,保存测试误差最小的模型。步骤3.7:计算itersmax次风功率预测模型的测试误差accuracy,将测试误差最小的风功率预测模型输出,用于预测风功率。所述预测风功率模型的测试误差accuracy的计算公式如公式(18)所示:其中,mean为每一批次数据的误差平均值。本实施例中,最终的风功率预测模型模型的运行时间、准确率如表1所示。表1模型训练时间及准确率模型训练时间单组数据运行时间准确率139.15s0.004s94.20%随机截取的多组数据的预测对比结果如表2所示,将表2转化为可视化的对比曲线图如图7所示,由图7可以看出,预测曲线基本和实际数据重合,对于超短时数据缺失的预测精度已经很高。表2预测结果与真实值比较结果最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解;其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;因而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1